Spark API 图解:Python与Scala实现的转换与操作
需积分: 5 154 浏览量
更新于2024-07-17
收藏 3.61MB PDF 举报
"TRANSFORMATIONS AND ACTIONS .pdf 是一份关于Spark API的视觉指南,通过Python和Scala代码展示了Spark的转换(Transformations)和动作(Actions)操作,以帮助用户更直观地理解这些算子的工作原理。这份文档包含了Jeff Thompson的67个可视化图表,并由Adam Breindel进一步发展和完善。Databricks公司创建了Databricks Cloud,这是一个统一的平台,用于构建大数据管道,涵盖了从ETL到探索、仪表板、高级分析和数据产品的全过程。"
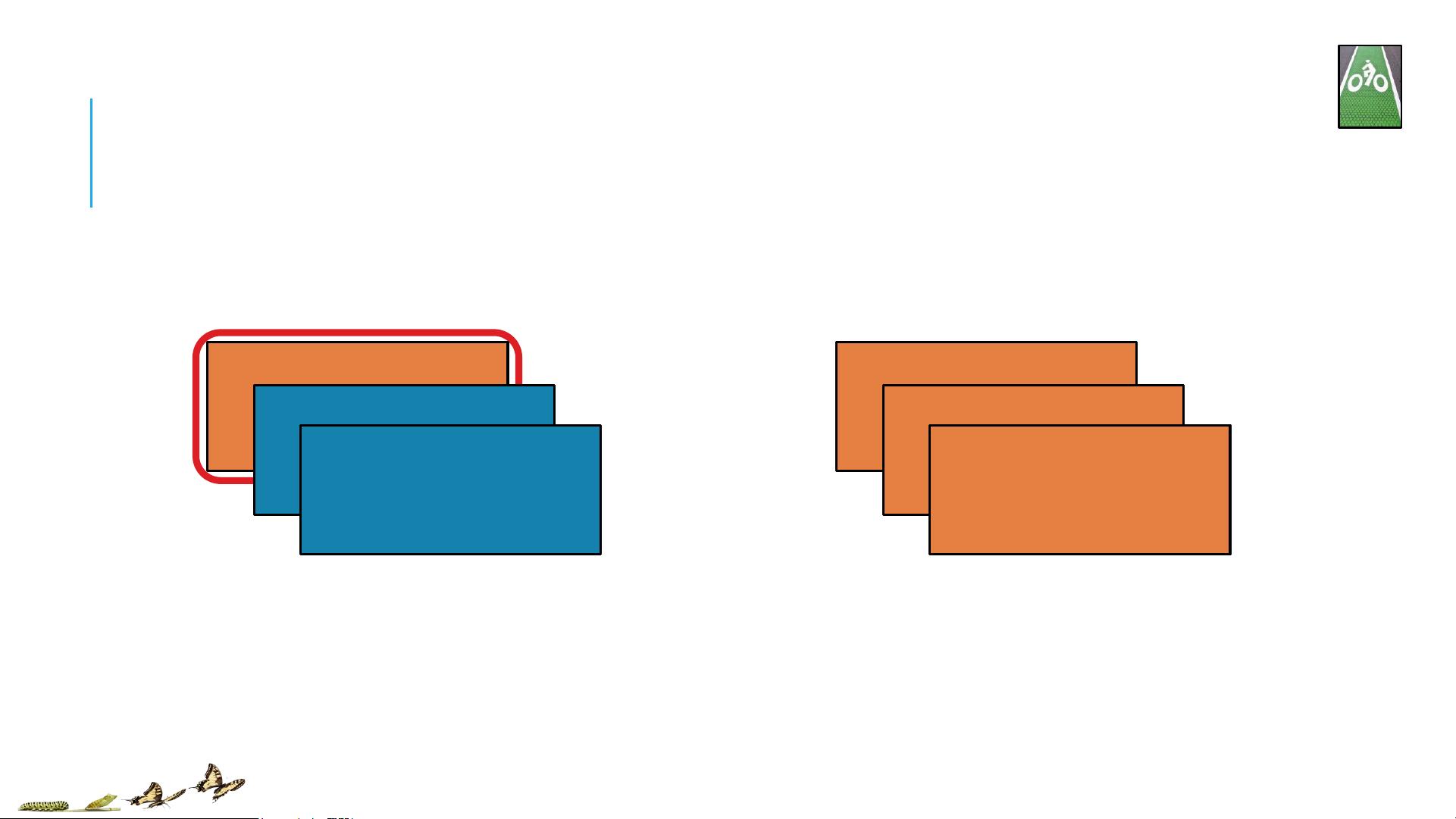
Spark的核心是弹性分布式数据集(RDD),这是一种不可变、分区的数据集合,可以在集群中并行处理。RDD具有两个主要的操作类型:转换(Transformations)和动作(Actions)。
1. 转换(Transformations):
- `map(func)`: 对RDD中的每个元素应用函数func,返回一个新的RDD。
- `filter(pred)`: 根据谓词pred保留满足条件的元素,返回新的RDD。
- `flatMap(func)`: 类似于map,但func可以返回多个值,将结果扁平化成一个单一的RDD。
- `join(otherRDD)`: 将两个RDD基于相同的键进行连接,返回键值对的RDD。
- `groupByKey()`: 将具有相同键的元素聚集在一起,形成键值对的RDD,其中值是一个迭代器。
- `reduceByKey(func)`: 在每个键的值上应用二元函数func进行聚合。
- `distinct()`: 去除RDD中的重复元素。
- `sample(fraction, seed)`: 根据fraction参数随机采样RDD,可选地提供种子seed。
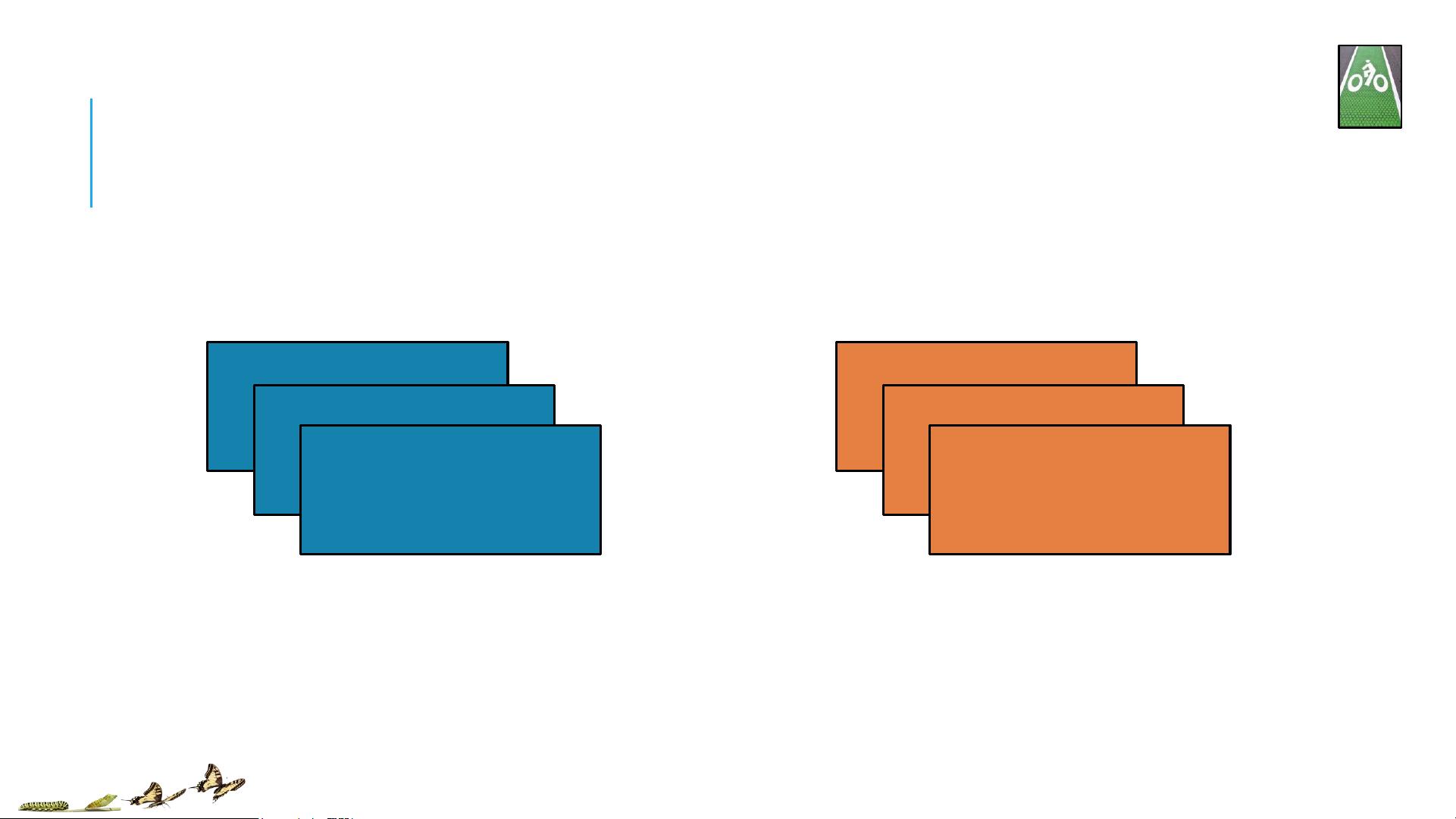
2. 动作(Actions):
- `count()`: 计算RDD的元素数量。
- `collect()`: 将RDD的所有元素拉取到driver端,返回一个列表。
- `first()`: 获取RDD的第一个元素。
- `take(n)`: 拉取RDD的前n个元素。
- `saveAsTextFile(path)`: 将RDD写入文本文件。
- `foreach(func)`: 对RDD的每个元素应用函数func,通常用于输出或副作用,不返回任何结果。
- `reduce(func)`: 使用二元函数func在所有元素上进行全局聚合。
这些操作在Spark中遵循延迟计算模型,转换不会立即执行,而是在触发动作时才进行。此外,由于RDD是分区的,所以转换和动作会在数据所在的节点上本地执行,从而实现高效的数据处理。
Databricks是由Apache Spark的创建者们在2013年晚期成立的,其产品Databricks Cloud提供了从数据提取、转换到数据分析和数据产品的完整解决方案。该公司与Hortonworks、MapR和DataStax等合作伙伴建立了二级或三级支持伙伴关系,目前有约55名员工,并在持续招聘中。

点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-06-30 上传
2008-11-13 上传
2011-06-02 上传
2024-05-15 上传
2018-04-20 上传
点击了解资源详情









