Spark运行架构详解与生态圈探索
Spark简介以及其生态圈深入讲解了Spark的运行架构、在不同集群环境下的部署方式以及常见问题解决方案。Spark是一个强大的分布式计算框架,其核心概念包括Application(用户编写的Spark应用程序)和Driver(运行应用程序的主进程)。Driver在启动时创建SparkContext,这个上下文提供了与集群交互的接口,为任务调度和数据处理设置基础。
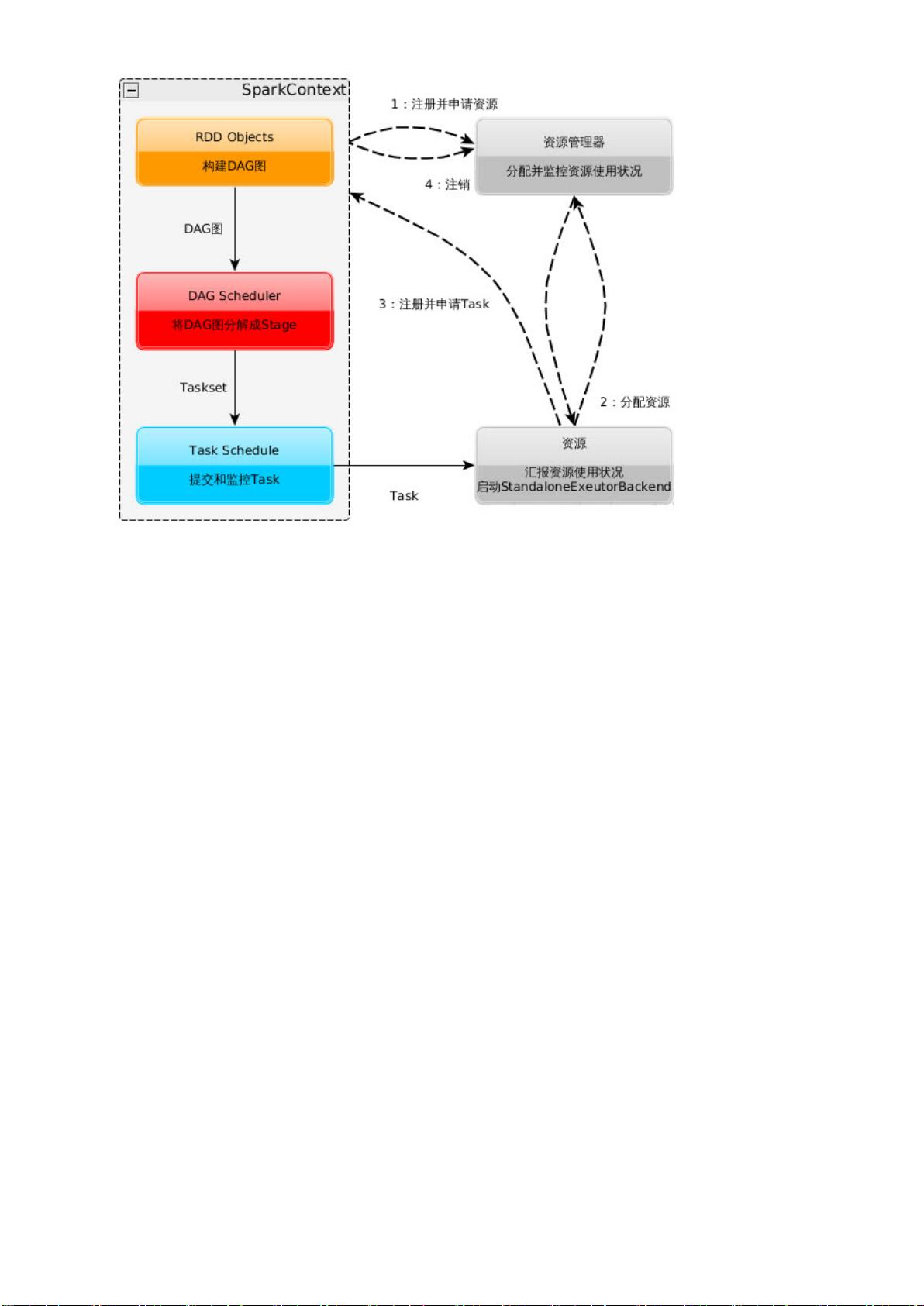
Spark运行架构分为以下几个关键部分:
1. **术语定义**:
- Application:与Hadoop MapReduce中的Job相似,是Spark用户编写的可执行程序,包含Driver(主进程)和Executor(工作进程)组件。
- Driver:负责执行用户提供的main()函数,并创建SparkContext,它负责初始化Spark的运行环境,管理任务的提交和监控。
2. **基本流程**:
- **DAGScheduler**:动态图调度器,根据应用程序逻辑构建有向无环图(DAG),将任务分解为可并行执行的任务块(TaskSet)。
- **TaskScheduler**:负责将DAG中的任务分发到Executor上执行,根据资源管理和负载均衡策略进行调度。
3. **运行原理**:
- **RDD(Resilient Distributed Datasets)**:Spark的核心数据结构,提供弹性、容错的数据集操作,允许用户在分布式环境下进行数据处理。
4. **集群部署**:
- **STANDALONE模式**:最简单的Spark集群模式,由一个Master节点和多个Worker节点组成,Master负责任务调度。
- **SPARK ON YARN**:运行在YARN之上,利用YARN的资源管理和调度能力,包括YARN-Client模式(客户端模式,直接与YARN交互)、YARN-Cluster模式(集群模式,通过YARN API调用)。
5. **运行演示**:
- **STANDALONE模式演示**:涉及启动Spark Shell,查看测试文件位置,执行任务并分析结果。
- **YARN模式演示**:分别展示了客户端和集群模式下的启动步骤、运行过程和结果分析。
6. **问题解决**:
- **YARN-CLIENT启动报错**:探讨了可能遇到的YARN-Client启动过程中常见的错误及其排查方法。
了解这些内容有助于快速理解和掌握Spark的运行机制,从而有效地在实际项目中应用Spark进行大数据处理和流式计算。
第 5 页 共 24 页 出自石山园,博客地址:http://www.cnblogs.com/shishanyuan
Spark 运行架构特点:
每个 Application 获取专属的 executor 进程,该进程在 Application 期间一直驻留,并以
多线程方式运行 tasks。这种 Application 隔离机制有其优势的,无论是从调度角度看(每
个 Driver 调度它自己的任务),还是从运行角度看(来自不同 Application 的 Task 运行在
不同的 JVM 中)。当然,这也意味着 Spark Application 不能跨应用程序共享数据,除非将
数据写入到外部存储系统。
Spark 与资源管理器无关,只要能够获取 executor 进程,并能保持相互通信就可以了。
提交 SparkContext 的 Client 应该靠近 Worker 节点(运行 Executor 的节点),最好是在同
一个 Rack 里,因为 Spark Application 运行过程中 SparkContext 和 Executor 之间有大
量的信息交换;如果想在远程集群中运行,最好使用 RPC 将 SparkContext 提交给集群,
不要远离 Worker 运行 SparkContext。
Task 采用了数据本地性和推测执行的优化机制。
1.2.1 DAGScheduler
DAGScheduler 把一个 Spark 作业转换成 Stage 的 DAG(Directed Acyclic Graph 有向无
环图),根据 RDD 和 Stage 之间的关系找出开销最小的调度方法,然后把 Stage 以 TaskSet 的
形式提交给 TaskScheduler,下图展示了 DAGScheduler 的作用:
剩余23页未读,继续阅读
2021-01-07 上传
2021-01-07 上传
2018-06-04 上传
点击了解资源详情
2023-03-16 上传
2023-03-16 上传

Mr_JoLiang
- 粉丝: 0
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
