多节点协同:CurveFS支持的多挂载与并发文件系统比较
需积分: 0 111 浏览量
更新于2024-06-30
收藏 1.08MB PDF 举报
CurveFS支持多挂载功能,这是针对现代应用环境中常见的需求,如云原生数据库和AI训练等,需要在同一文件系统上实现多台机器的并发读写。这种特性在提高系统可用性和性能的同时,也需要确保数据的一致性和完整性。
首先,我们来理解本地文件系统在并发读写中的工作原理。当多个进程尝试访问同一文件时,内核通过数据结构如O_APPEND(追加模式)和文件锁(flock/fcntl)来协调操作。O_APPEND使得新数据追加到文件末尾,避免冲突;而文件锁则可以控制对文件的独占或共享访问,防止数据破坏。
接着,我们探讨了几个流行的分布式文件系统如何处理多挂载场景:
1. GPFS:
- GPFS采用数据和元数据并发保护机制,包括字节区间锁(data locks)用于数据保护,以及共享写锁(metadata locks)保护元数据。AllocationMap提供了额外的元数据保护,并支持其他关键信息的安全管理。
2. Lustre:
- Lustre的分布式锁管理器模型包括基本锁模型、意图锁和范围锁,确保数据一致性。客户端缓存也考虑了数据和元数据的一致性问题。
3. JuiceFS:
- JuiceFS使用DBServer来管理锁,支持flock锁和fcntl区间锁,确保并发读写的正确性。
4. ChubaoFS和CephFS:
- CephFS利用cap(能力)实现分布式锁,通过capspermission和capscombination来控制权限组合,通过caps管理确保安全。fusewrite示例展示了其在实际操作中的应用。
5. NFS:
- NFS虽然不是专门设计用于多挂载,但通过数据和元数据缓存一致性策略,以及客户端缓存机制,尽力保证不同挂载点的数据同步。
在AI训练场景中,CurveFS需要满足低延迟的读取需求,确保写入数据在其他节点可见。在多写多读场景1中,如client1和client2同时写入不同文件,然后读取,CurveFS需要能正确处理并发请求,保证每个节点读取到的是各自写入的内容。
CurveFS支持多挂载,通过优化内核层面的数据结构和协议设计,以及引入分布式锁和一致性策略,实现了在多个节点间的高效、一致的文件系统访问。这使得它成为应对现代分布式应用挑战的理想选择,特别是在需要高度可扩展性和数据一致性保障的场景中。
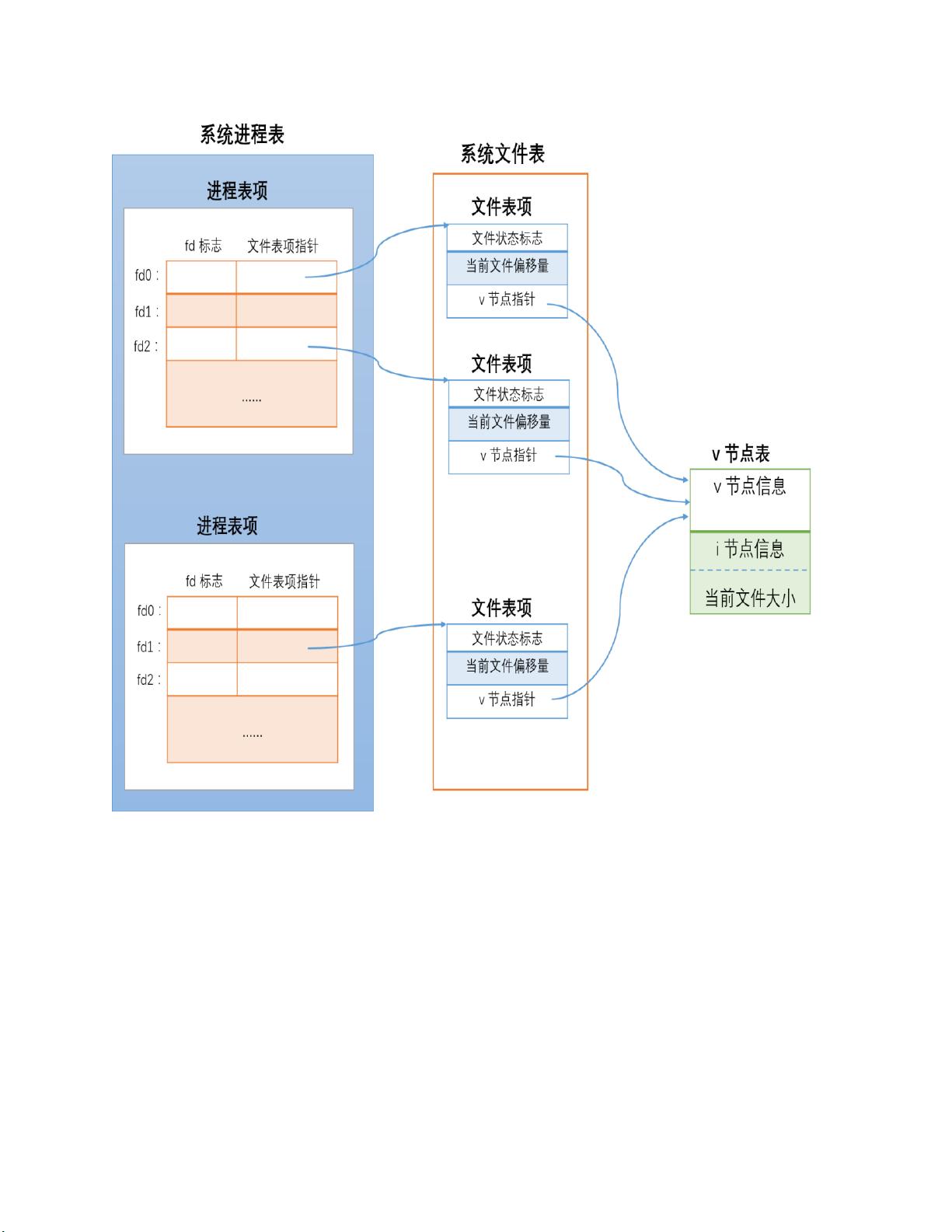
如果进程 2 对 fd1 加上了排他锁,实际就是加在了 fd1 指向的文件表项上。此时,进程 1
对 fd0 加锁会失败。
因为操作系统会检测到进程 1 中 fd0 对应的文件表项 和 进程 2 中 fd1 对应的文件表项指
向相同的 v 节点,且进程 2 中 fd2 对应的文件表项已经加了排它锁。
fcntl
fnctl locks work as a Process <--> File relationship, ignoring filedescriptors
#include <unistd.h>
#include <fcntl.h>

剩余36页未读,继续阅读
1901 浏览量
1227 浏览量
190 浏览量
212 浏览量
276 浏览量
195 浏览量

shkpwbdkak
- 粉丝: 40
- 资源: 299
 我的内容管理
展开
我的内容管理
展开







最新资源
- 图层的操作类型和操作技巧
- 2D.Object.Detection.and.Recognition.2002
- 嵌入式Linux系统(pdf)
- 数据库系统工程师:数据库原理选择题总结
- Everything.You.Know.About.CSS.is.Wrong
- C语言库函数使用大全
- arm 2410手册
- 悟透JavaScript.doc
- 计算机网络谢希仁答案详尽,是很不错的学习资料,考研,考证,很实用
- Thinking in Java 3th Edition
- Java中的static关键字
- 简单交通的设计与制作
- 硬件基础知识及故障维护
- 计算机组成原理课后习题答案 白中英 第三版(网络版)
- 学生学籍管理系统论文
- Linux 0.11内核完全注释.pdf
