SparkStreaming实时流处理入门:原理与实战
54 浏览量
更新于2024-08-28
收藏 527KB PDF 举报
"Spark入门实战系列(上)-实时流计算SparkStreaming原理介绍"
SparkStreaming是Apache Spark的重要组成部分,专为实时数据流处理而设计。它构建在Spark Core之上,提供了一种高效、容错的流处理能力,允许开发者使用熟悉的RDD操作来处理持续不断的数据流。SparkStreaming支持多种数据输入源,如Kafka、Flume、Twitter、ZeroMQ、Kinesis以及TCP sockets,涵盖了广泛的数据接入场景。
在SparkStreaming中,实时数据流被划分为一系列固定大小的时间间隔,称为批处理时间间隔(batch interval)。例如,这个间隔可以设置为1秒,意味着每秒钟接收到的数据会被组合成一个批次进行处理。这种将实时流转换为批处理的方式使得SparkStreaming能够利用其核心的RDD(弹性分布式数据集)和并行计算能力。每个时间片的数据对应一个RDD实例,这样DStream(离散化流)实际上就是一系列连续的RDDs。
DStream是SparkStreaming对实时数据流的主要抽象,它代表了一个持续的数据流,由多个连续的RDDs组成。用户可以对DStream应用类似于map、reduce、join和window等高阶操作,来执行复杂的实时分析任务。例如,map函数可以用于对每个数据项执行转换,reduce用于聚合数据,join用于合并来自不同数据流的信息,而window操作则允许在特定时间窗口内的数据上进行计算,这对于处理滑动窗口统计等场景非常有用。
SparkStreaming的设计哲学是"OneStackrulethemall",意味着它可以与其他Spark组件(如MLlib(机器学习库)和GraphX(图计算库))无缝集成,从而实现对流数据的深度分析。例如,可以先用SparkStreaming进行实时预处理,然后将结果传递给MLlib进行模式识别或预测,或者使用GraphX进行网络分析。
在内部,SparkStreaming通过一个FIFO(先进先出)队列管理批数据,生产者负责收集实时数据并将其分批,而消费者即Spark Engine负责处理这些批次。为了协调生产和消费速率,SparkStreaming需要确保数据的稳定流动,避免生产过快导致队列积压,或者消费过快导致数据丢失。这涉及到对系统资源的精细管理和优化,以保持系统的稳定性和性能。
时间片和窗口长度是调整实时处理的关键参数。时间片决定了批处理的频率,窗口长度则定义了在时间轴上考虑的数据范围。例如,一个窗口长度为5分钟的窗口会包含过去5分钟内的所有数据,这对于计算滚动平均值或检测短期趋势非常有用。窗口操作可以与DStream上的其他操作结合使用,实现更复杂的数据分析逻辑。
SparkStreaming提供了一种灵活、强大的实时流处理框架,通过将实时流转化为可处理的批数据,利用Spark的并行计算能力,实现了对大规模流数据的高效处理和分析。它的设计考虑了容错性、可伸缩性和易用性,使其成为实时大数据处理领域的重要工具。
Spark入门实战系列入门实战系列(上上)-实时流计算实时流计算SparkStreaming原理介绍原理介绍
1、Spark Streaming简介
1.1 概述
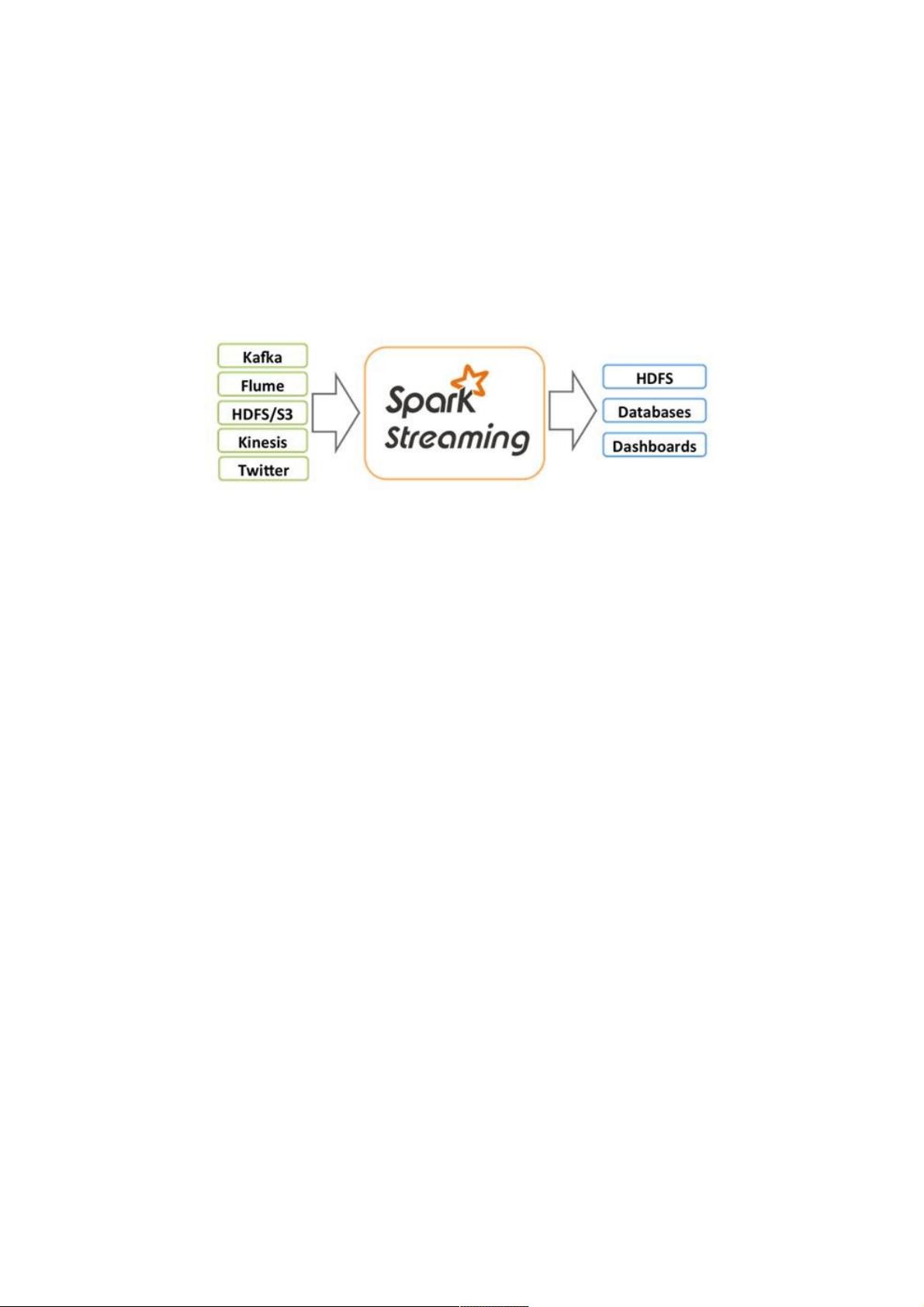
Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源
获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis 以及TCP sockets,从数据源获取数据之后,可以使用诸如map、
reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库和现场仪表盘。
在“One Stack rule them all”的基础上,还可以使用Spark的其他子框架,如集群学习、图计算等,对流数据进行处理。
Spark Streaming处理的数据流图:
Spark的各个子框架,都是基于核心Spark的,Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间
间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。
对应的批数据,在Spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDDs,即RDD的一个序列。
通俗点理解的话,在流数据分成一批一批后,通过一个先进先出的队列,然后 Spark Engine从该队列中依次取出一个个批数
据,把批数据封装成一个RDD,然后进行处理,这是一个典型的生产者消费者模型,对应的就有生产者消费者模型的问题,
即如何协调生产速率和消费速率。
1.2 术语定义
l离散流(discretized stream)或DStream:这是Spark Streaming对内部持续的实时数据流的抽象描述,即我们处理的一个实
时数据流,在Spark Streaming中对应于一个DStream 实例。
l批数据(batch data):这是化整为零的第一步,将实时流数据以时间片为单位进行分批,将流处理转化为时间片数据的批处
理。随着持续时间的推移,这些处理结果就形成了对应的结果数据流了。
l时间片或批处理时间间隔( batch interval):这是人为地对流数据进行定量的标准,以时间片作为我们拆分流数据的依据。
一个时间片的数据对应一个RDD实例。
l窗口长度(window length):一个窗口覆盖的流数据的时间长度。必须是批处理时间间隔的倍数,
l滑动时间间隔:前一个窗口到后一个窗口所经过的时间长度。必须是批处理时间间隔的倍数
lInput DStream :一个input DStream是一个特殊的DStream,将Spark Streaming连接到一个外部数据源来读取数据。
1.3 Storm与Spark Streming比较
l处理模型以及延迟
虽然两框架都提供了可扩展性(scalability)和可容错性(fault tolerance),但是它们的处理模型从根本上说是不一样的。Storm可
以实现亚秒级时延的处理,而每次只处理一条event,而Spark Streaming可以在一个短暂的时间窗口里面处理多条
(batches)Event。所以说Storm可以实现亚秒级时延的处理,而Spark Streaming则有一定的时延。
l容错和数据保证
然而两者的代价都是容错时候的数据保证,Spark Streaming的容错为有状态的计算提供了更好的支持。在Storm中,每条记
录在系统的移动过程中都需要被标记跟踪,所以Storm只能保证每条记录最少被处理一次,但是允许从错误状态恢复时被处理
多次。这就意味着可变更的状态可能被更新两次从而导致结果不正确。
任一方面,Spark Streaming仅仅需要在批处理级别对记录进行追踪,所以他能保证每个批处理记录仅仅被处理一次,即使是
node节点挂掉。虽然说Storm的 Trident library可以保证一条记录被处理一次,但是它依赖于事务更新状态,而这个过程是很
慢的,并且需要由用户去实现。
l实现和编程API
下载后可阅读完整内容,剩余9页未读,立即下载

weixin_38565818
- 粉丝: 3
- 资源: 956
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python库 | slick_webdriver-1.0.51-py3-none-any.whl
- NRDFReactor-开源
- 易语言超级列表框操作源码-易语言
- Hoja-de-Trabajo-5:Hoja-de-Trabajo 5 2 ejercicios
- OOP-Java:Java语言nesneseyönelimprogramlama olarak gruparkadaşımileyapmışolduğumuzdönemprojesi
- Service.Liquidity.Converter
- reading-notes:实时网址
- genius-starter-files
- 易语言API拖放功能源码-易语言
- spyasuda.github.io:以工作项目组合为特色的专业网站
- brainsatplay.github.io:我们的Brains @ Play前端网站
- 0559、数字电子技术基础实验指导书.rar
- IMU_Calibration
- UltraNice.tsr9pfc273.gaspCeI
- Edustack
- man子手
