2019年多说话者语音克隆自动技术硕士论文
需积分: 10 67 浏览量
更新于2024-07-09
收藏 2.54MB PDF 举报
标题:"Automatic Multispeaker Voice Cloning-2019.pdf" 论文探讨了自动多说话人语音克隆技术,该领域的研究旨在创建能够模仿多个声音来源的先进语音合成系统。作者Corentin Jemine在2018-2019学年撰写此硕士论文,由Gilles Louppe作为指导者,该工作隶属于法国列日大学的应用科学学院。这篇硕士学位论文专注于数据科学的专门领域,特别是与声音处理和人工智能技术相关。
论文的核心内容围绕如何设计并实现一个实时的多说话人语音克隆系统,这涉及到深度学习、声学建模、信号处理以及可能的神经网络架构,如循环神经网络(RNN)或变分自编码器(VAE),来捕捉和复制不同个体的声音特征。研究可能使用了TTS(Text-to-Speech)技术和声码器-解码器结构,通过分析和学习每个说话人的语音样本,包括其音调、语速和发音习惯,以生成高度逼真的语音合成。
论文的成果可以应用于多种场景,如语音合成、音频转换、虚拟助理的个性化声音定制,或者用于增强沉浸式体验,如游戏中的角色配音。此外,论文还强调了版权和使用权的规定,指出用户可以在遵守BOAI原则(Budapest Open Access Initiative)的前提下,进行阅读、下载、复制、传播、打印和学术研究等行为,但商业用途是严格禁止的,同时尊重作者的道德权利。
论文的代码和数据集可以通过论文作者在GitHub上的项目(<https://github.com/CorentinJ/Real-Time-Voice-Cloning>)获取,以及图书馆的数字资源(<http://lib.uliege.be> 和 <http://hdl.handle.net/2268.2/6801>)进行访问。这个研究不仅是对语音识别和合成技术的深入探索,也为后续的多模态交互和个性化语音技术的发展奠定了基础。

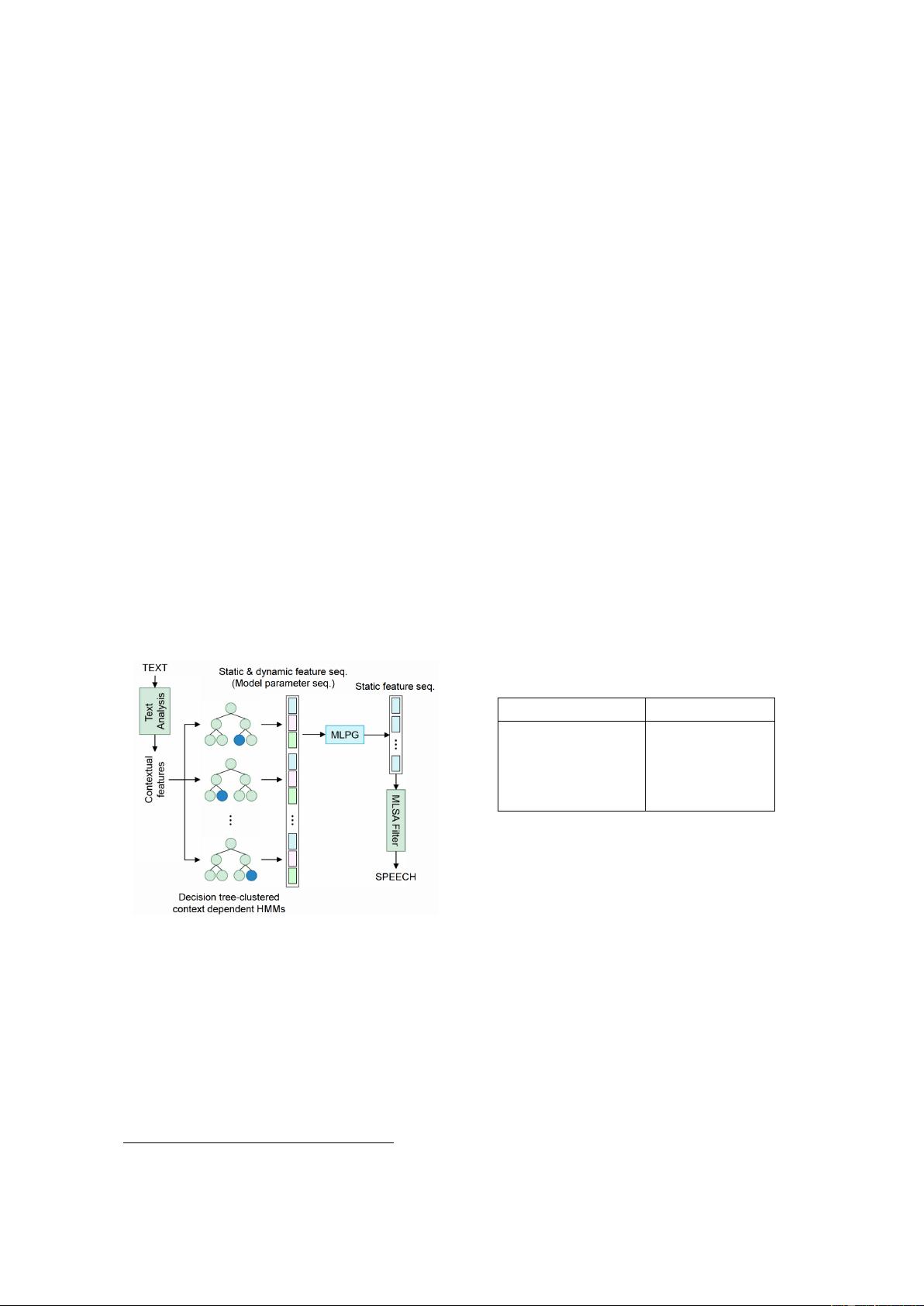
for rare or unknown words. Indeed, manually engineered heuristics do not quite fully
characterize all intricacies of spoken language. For this reason, feature extraction
can also be done with trained models. The line between the feature extractor and
the acoustic model can then become blurry, especially for deep models. In fact, a
tendency that is common across all areas where deep models have overtaken traditional
machine learning techniques is for feature extraction to consist of less heuristics, as
highly nonlinear models become able to operate at higher levels of abstraction.
A common feature extraction technique is to build frames that will integrate
surrounding context in a hierarchical fashion. For example, a frame at the syllable level
could include the word that comprises it, its position in the word, the neighbouring
syllables, the phonemes that make up the syllable, ... The lexical stress and accent
of individual syllables can be predicted by a statistical model such as a decision tree.
To encode prosody, a set of rules such as ToBI (Beckman and Elam, 1997) can be
used. Ultimately, there remains a work of feature engineering to present a frame as a
numerical object to the model, e.g. categorical features are typically encoded using a
one-hot representation.
The reason why the acoustic model does not directly predict an audio waveform
is that audio happens to be difficult to model: it is a particularly dense domain
and audio signals are typically highly nonlinear. A representation that brings out
features in a more tractable manner is the time-frequency domain. Spectrograms
are smoother and much less dense than their waveform counterpart. They also have
the benefit of being two-dimensional, thus allowing models to better leverage spatial
connectivity. Unfortunately, a spectrogram is a lossy representation of the waveform
that discards the phase. There is no unique inverse transformation function, and
deriving one that produces natural-sounding results is not trivial. When referring to
speech, this generative function is called a vocoder. The choice of the vocoder is an
important factor in determining the quality of the generated audio.
As is often the case with tasks that involve generating perceptual data such as
images or audio, a formal and objective evaluation of the performance of the model
is difficult. In our case, we’re concerned with evaluating speech naturalness and voice
similarity of the generated audio. Older TTS methods often relied on statistics com-
puted on the waveform or on the acoustic features to compare different models. Not
only are those metrics often only weakly correlated with the human perception of
sound, but they would also typically be what the model was aiming to minimize.
“When a measure becomes a target, it ceases to be a good measure” (Strathern, 1997).
A recent tendency adopted in TTS is to perform a subjective evaluation with human
subjects and to report their Mean Opinion Score (MOS). The subjects are presented
with a series of audio segments and are asked to rate their naturalness (or similarity
when comparing two segments) on a Likert scale from 1 to 5. Because subjects do not
necessarily rate actual human speech with a 5, it may be possible for TTS systems to
surpass humans on this metric in the future. (Shirali-Shahreza and Penn, 2018) argue
that MOS is not a metric adapted to evaluate TTS systems, and they advocate using
A/B testing instead, where subjects are asked to say which audio segment they prefer
6
剩余37页未读,继续阅读
2020-05-18 上传
2021-05-02 上传
2021-02-03 上传

TracelessLe
- 粉丝: 5w+
- 资源: 466
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
