Impala:快速大数据查询引擎
版权申诉
139 浏览量
更新于2024-08-06
收藏 235KB DOCX 举报
"大数据分析查询引擎Impala是一个由Cloudera公司开发的高效查询系统,设计灵感来源于Google的Dremel系统。Impala的主要目标是解决Hive在处理大规模数据时的低效交互性问题,提供快速的SQL查询功能,支持PB级别的数据处理。与Hive不同,Impala不依赖于MapReduce,而是采用了一种类似并行关系数据库的分布式查询引擎,由Query Planner、Query Coordinator和Query Exec Engine三个组件构成,可以直接对HDFS和HBase中的数据进行实时查询。
Dremel是Google的一个创新性交互式数据分析系统,它基于GFS(Google File System)和其他Google基础设施,支持BigQuery等服务。Dremel的核心特性包括列存储和多层查询树。列存储针对嵌套结构的数据,能够减少查询处理的数据量,提高查询效率。而多层查询树允许查询在大规模分布式环境中高效执行。Dremel的查询树模型类似于分布式搜索引擎,从根节点接收查询,逐层分解并执行,最后汇总结果。
Impala在设计上借鉴了Dremel,实现了列存储格式Parquet,Parquet不仅实现了列式存储,还计划支持Hive的更多特性,如字典编码和游程编码。Impala的系统架构包括多个组件,如StateStore用于元数据管理和状态同步,Catalog Server用于存储和管理表的元数据,以及Impalad进程,它们在各个节点上运行,执行实际的查询任务。
使用Impala,用户可以通过Hive的SQL接口进行数据查询,无需等待MapReduce作业完成,极大地提升了大数据分析的响应速度。这使得Impala成为大数据分析领域的强大工具,尤其适合需要快速响应和交互式查询的场景。然而,尽管Impala提供了高性能的查询能力,但它可能不适合所有的数据分析任务,例如复杂的ETL过程或者需要高度灵活性的数据处理,这些情况Hive或Pig等其他工具可能更为合适。
Impala是Hadoop生态系统中一个重要的组成部分,它为大数据分析带来了更高的交互性和性能,特别是在需要实时查询和分析PB级数据的场景下,Impala展现出了其强大的优势。"
3 / 13
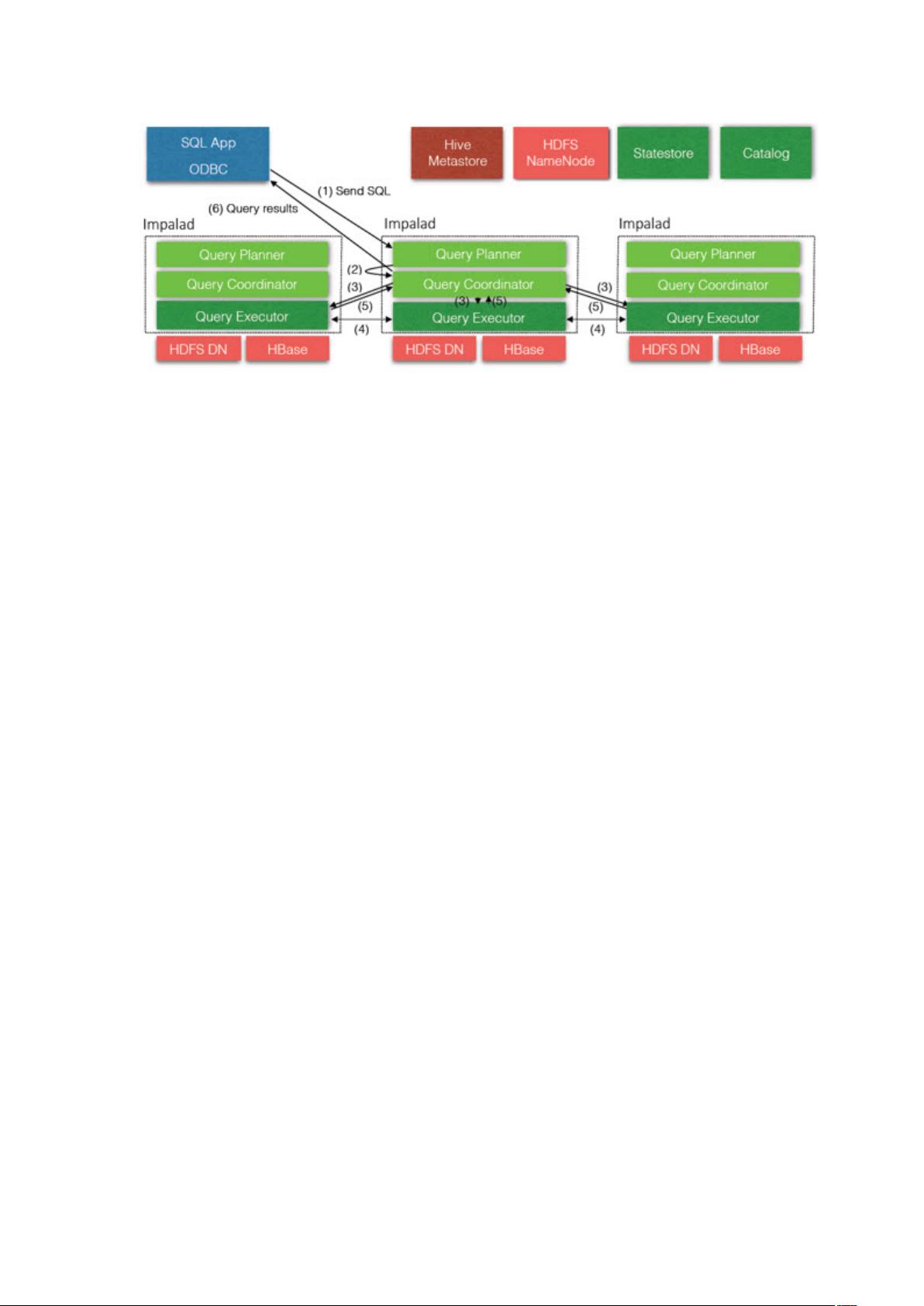
Impalad
及 DataNode 运行在同一节点上,由 Impalad 进程表示,它接收客户端的查询
请求(接收查询请求的 Impalad 为 Coordinator,Coordinator 通过 JNI 调用
java 前端解释 SQL 查询语句,生成查询计划树,再通过调度器把执行计划分发
给具有相应数据的其它 Impalad 进行执行),读写数据,并行执行查询,并把
结果通过网络流式的传送回给 Coordinator,由 Coordinator 返回给客户端。同
时 Impalad 也及 State Store 保持连接,用于确定哪个 Impalad 是健康和可以
接受新的工作。在 Impalad 中启动三个 ThriftServer: beeswax_server(连接客
户端),hs2_server(借用 Hive 元数据), be_server(Impalad 内部使用)
和一个 ImpalaServer 服务。每个 impalad 实例会接收、规划并调节来自
ODBC 或 Impala Shell 等客户端的查询。每个 impalad 实例会充当一个
Worker,处理由其它 impalad 实例分发出来的查询片段(query fragments)。客
户端可以随便连接到任意一个 impalad 实例,被连接的 impalad 实例将充当本
次查询的协调者(Ordinator),将查询分发给集群内的其它 impalad 实例进行
并行计算。当所有计算完毕时,其它各个 impalad 实例将会把各自的计算结果
发送给充当 Ordinator 的 impalad 实例,由这个 Ordinator 实例把结果返回给
客户端。每个 impalad 进程可以处理多个并发请求。
Impala State Store
跟踪集群中的 Impalad 的健康状态及位置信息,由 statestored 进程表示,它通
过创建多个线程来处理 Impalad 的注册订阅和及各 Impalad 保持心跳连接,
各 Impalad 都会缓存一份 State Store 中的信息,当 State Store 离线后
(Impalad 发现 State Store 处于离线时,会进入 recovery 模式,反复注册,
剩余12页未读,继续阅读
2020-01-19 上传
2020-11-18 上传
2021-10-14 上传
2022-06-21 上传
2022-11-24 上传
2020-03-11 上传
2022-11-24 上传
2024-05-16 上传
2019-06-13 上传

kfcel5889
- 粉丝: 3
- 资源: 5万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- ATT7022B-programe,网络验证c语言源码,c语言
- Utils:一些实用程序
- chatomud
- configs:基于UNIX的点文件
- Feminazi a flor-crx插件
- 802.11b PHY Simulink 模型:802.11b 基带物理层的 Simulink:registered: 模型。-matlab开发
- SQLITE
- CpuTimer0,c语言read源码,c语言
- java-projects
- 오늘의 운세-crx插件
- technical-community-builders:雇用技术社区建设者的公司
- csrf_attack_example
- grpar:提取构建引擎组(.grp)文件的工具-开源
- Backjoon
- 每日日记:一种日记应用程序,融合了我在编码过程中所学到的技术
- AT89C2051UPS,c语言输出图形源码,c语言
