MATLAB实现的数字识别系统解决图书馆图书错位问题
版权申诉
35 浏览量
更新于2024-07-03
收藏 401KB DOC 举报
"该文档介绍了一个基于MATLAB的数字识别系统的设计,旨在解决图书馆中图书错位和丢失的问题。系统利用数字识别技术自动化地定位图书,提高图书馆资源的利用率和读者体验。"
在当前的数字化时代,图书馆管理系统的效率对于信息的获取至关重要。传统的图书馆系统依赖于索书号来定位图书,索书号是根据《中国图书资料分类法》编制的,由拉丁字母和阿拉伯数字组成,用于区分不同类别的图书,并确保其在书架上的唯一位置。然而,随着图书馆规模的扩大和借阅量的增加,图书错位和丢失的情况时常发生,这不仅降低了图书馆资源的使用效率,也给读者带来了不便。
为了解决这个问题,基于MATLAB的数字识别系统被提出。MATLAB是一种强大的数学计算和数据分析环境,适合开发图像处理和模式识别算法。在这个系统中,可能涉及到的技术包括图像采集、预处理、特征提取和数字识别。例如,系统可能使用摄像头捕获书架上的图书,然后通过图像预处理去除噪声,增强图像质量。接着,特征提取算法(如边缘检测、模板匹配或深度学习模型)将从图像中识别出索书号的特征。最后,数字识别模块将这些特征与已知的索书号数据库进行比对,从而确定图书的确切位置。
这种自动化的数字识别系统可以显著提高图书查找的准确性,减少因图书错位导致的查找困难。同时,它也可以实时监测图书的状态,及时发现丢失的图书,避免电子数据库与实际书库状态的不一致。此外,系统可以减轻图书馆工作人员的工作负担,减少人为错误,提升图书馆服务的整体效率。
尽管MATLAB提供了强大的工具集,但开发这样一个系统仍然面临挑战。比如,光照条件变化、图书标签的磨损、以及不同字体和排版的索书号可能影响识别效果。因此,系统设计需要考虑这些因素,优化算法以提高鲁棒性和准确性。此外,系统的实时性能也是关键,需要确保在大量图书环境中能够快速响应。
基于MATLAB的数字识别系统为图书馆管理提供了一种创新的解决方案,它结合了计算机视觉和机器学习技术,有望改善图书馆的运营效率,提升读者的借阅体验。随着技术的不断发展,类似的自动化识别系统将在未来的图书馆管理中扮演更加重要的角色。
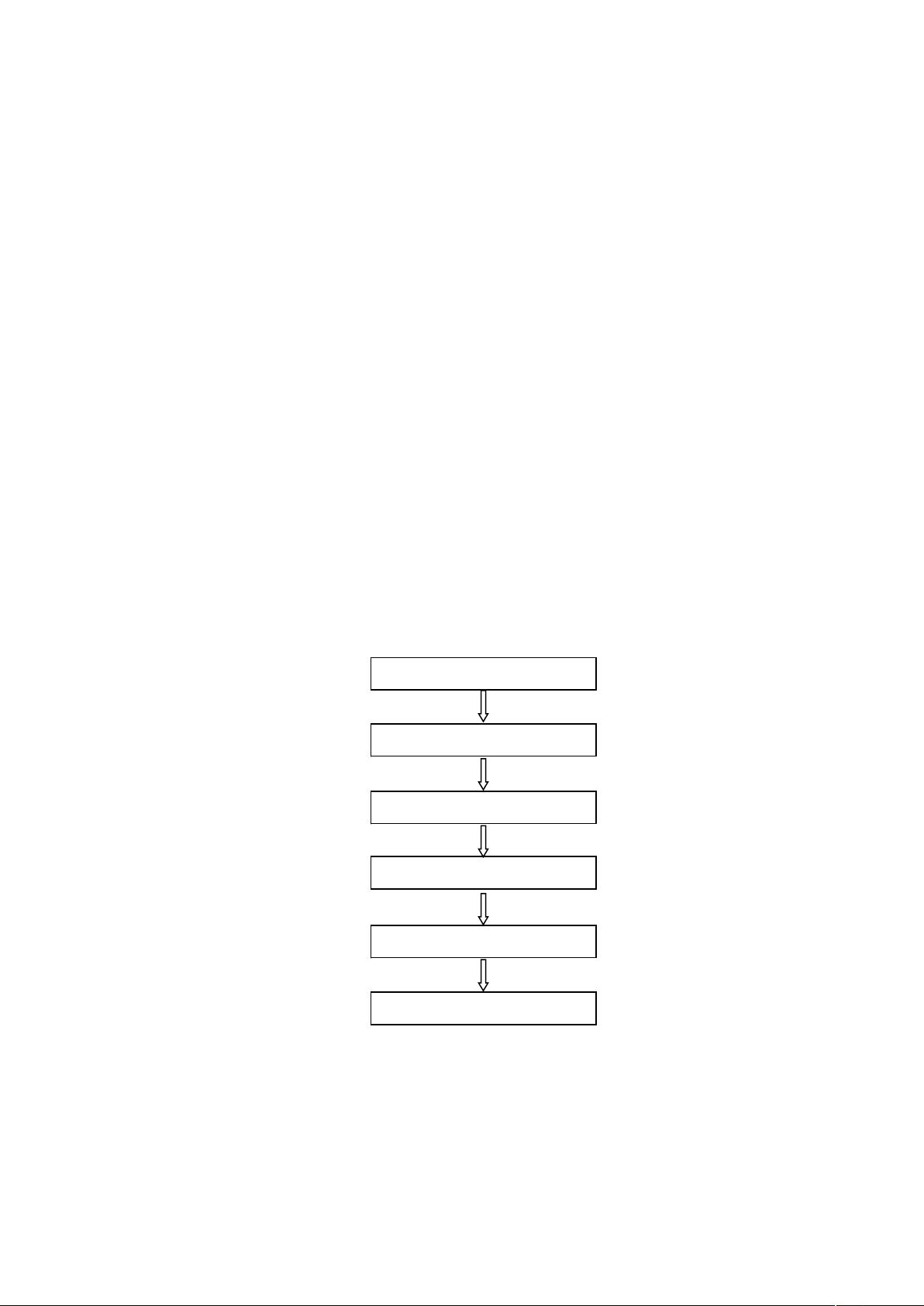
定规则,索书号文字图像具有如下特征:第一,索书号文字采用黑色应刷;第
二,索书号文字数量至少为 3 个;第三,索书号字符水平排列;第四,索书号
贴在书脊下半部分。它算法流程如图 2-2 所示,实验结果证明,该方法具有定
位精度高,准确率高,抗噪能力强,并在“索书号自动识别系统”中取得理想效果。
图 2-2 索书号图像分割算法流程
Canny 算子检测
索书号边缘点彩色分割
文字图像行区域检测
HSI 彩色空间转换
文字图像列区域检测
边界调整


剩余50页未读,继续阅读
2023-07-08 上传
2023-07-01 上传
2023-07-07 上传
2023-10-22 上传
2021-12-08 上传
2023-07-02 上传
2023-09-08 上传
2023-07-02 上传

智慧安全方案
- 粉丝: 3814
- 资源: 59万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
