海量数据处理:方法与数据结构解析
需积分: 10 165 浏览量
更新于2024-07-27
收藏 2.9MB PDF 举报
"这篇文档主要讨论了海量数据处理的常用方法,包括数据结构、算法以及分布式处理技术。文章提到了一些关键概念,如哈希、红黑树、Bloom filter、位图、堆、数据库、倒排索引、Trie树、外排序以及Hadoop/MapReduce等,并对它们在处理大数据时的作用进行了概述。文档首先定义了海量数据处理的含义,指出由于数据量过大导致的处理挑战,然后提出了解决方案,包括时间效率提升和空间优化。在时间效率方面,可以通过使用Bloom filter、哈希、位图、堆、数据库索引等方法来加快处理速度;在空间优化上,主要采用分而治之的策略,例如使用哈希映射和分布式计算。此外,文章还区分了单机处理和集群处理的区别,并列出了处理海量数据的六种主要方法模式。文档的后半部分预计将详细解释这些方法,并对关联式容器如set、map、hashtable等的基础知识进行介绍,为后续的深入讨论做准备。"
在海量数据处理中,理解各种数据结构和算法是至关重要的。例如,哈希表(hashtable/hash_map/hash_set)提供快速的查找、插入和删除操作,通常用于构建索引或进行统计分析。Bloom filter是一种空间效率高的概率型数据结构,用于判断一个元素是否可能存在于一个大规模集合中,适用于节省存储空间但能接受一定误判率的场景。位图(bit-map)则可以表示大量离散状态,特别适合于布尔查询和数据压缩。堆(堆排序)在处理大数据时能够提供近似最优的时间复杂度,适用于需要排序的情况。数据库和倒排索引是数据存储和检索的常见工具,尤其适用于关系型数据和文本数据。Trie树(字典树)用于高效存储和查找字符串,减少字符串比较的次数。外排序是处理超过内存容量的大文件的一种方法,通过磁盘读写来实现排序。
此外,分布式处理技术如Hadoop和MapReduce是应对海量数据的关键。Hadoop是一个开源框架,允许在大规模集群上存储和处理数据,而MapReduce是Hadoop中的编程模型,用于编写处理大数据的并行计算任务,它将大型任务分解为可独立执行的小任务,提高了处理效率。
该文档将涵盖从基本数据结构到高级处理技术的全面内容,旨在帮助读者理解和掌握处理海量数据的各种方法。对于准备面试或寻求相关知识的人来说,这是一个宝贵的资源。

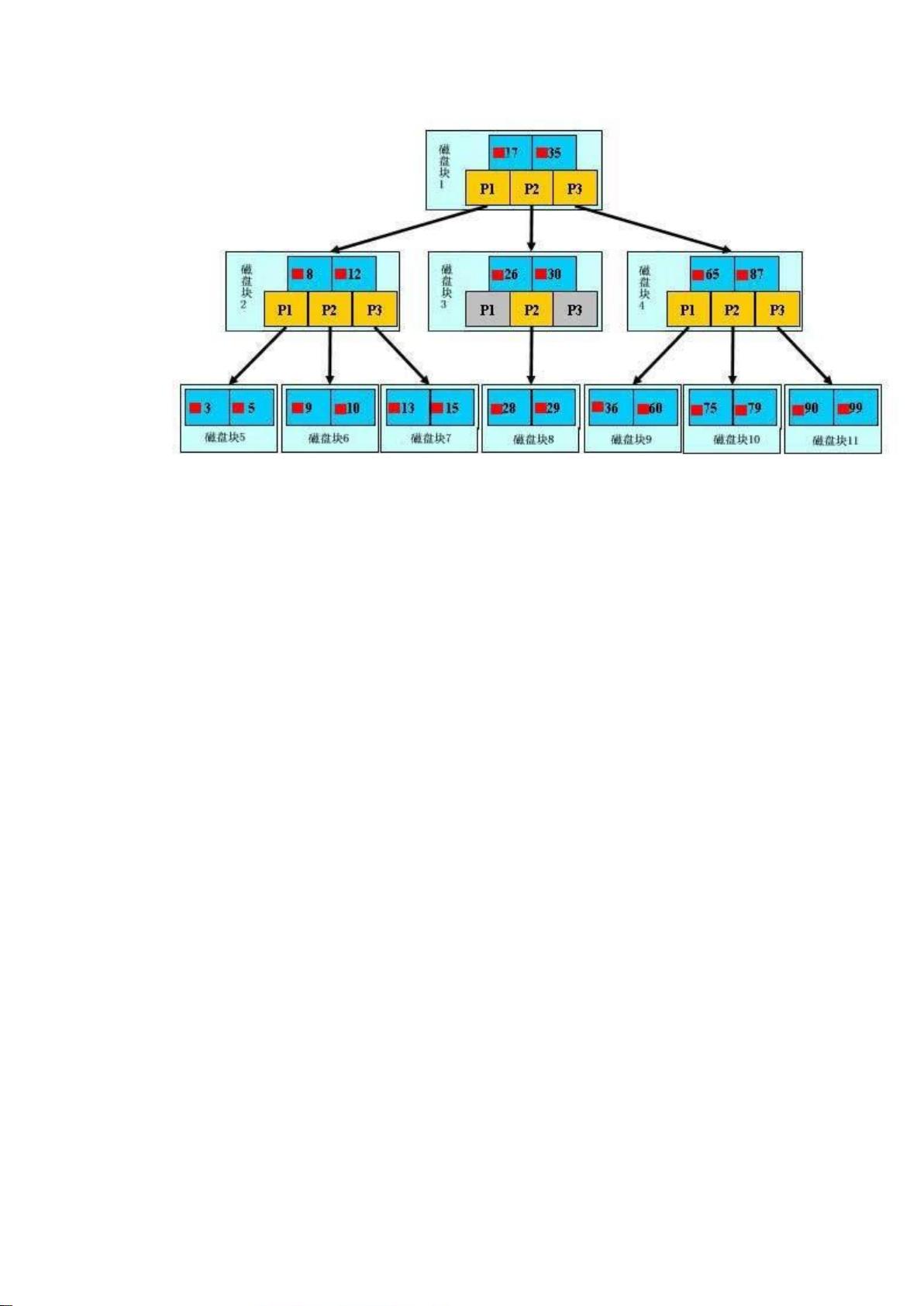
a) Ki (i=1...n)为关键字,且关键字按顺序升序排序 K(i-1)< Ki。
b) Pi 为指向子树根的接点,且指针 P(i-1)指向子树种所有结点的关键字均小于 Ki,
但都大于 K(i-1)。
c) 关键字的个数 n 必须满足: [ceil(m / 2)-1]<= n <= m-1。如下图所示:
针对上面第 5 点,再阐述下:B 树中每一个结点能包含的关键字(如之前上面的 D H 和 Q T X)
数有一个上界和下界。这个下界可以用一个称作 B 树的最小度数(算法导论中文版上译作度数,
最小度数即内节点中节点最小孩子数目)t(t>=2)表示。
每个非根的结点必须至少含有 t-1 个关键字。每个非根的内结点至少有 t 个子女。如果
树是非空的,则根结点至少包含一个关键字;
每个结点可包含之多 2t-1 个关键字。所以一个内结点至多可有 2t 个子女。如果一个结
点恰好有 2t-1 个关键字,我们就说这个结点是满的(而稍后介绍的 B*树作为 B 树的一
种常用变形,B*树中要求每个内结点至少为 2/3 满,而不是像这里的 B 树所要求的至少
半满);
当关键字数 t=2(t=2 的意思是,tmin=2,t 可以>=2)时的 B 树是最简单的(有很多人
会因此误认为 B 树就是二叉查找树,但二叉查找树就是二叉查找树,B 树就是 B 树,B
树的真正最准确的定义为:一棵含有 t(t>=2)个关键字的平衡多路查找树)。每个内
结点可能因此而含有 2 个、3 个或 4 个子女,亦即一棵 2-3-4 树,然而在实际中,通常
采用大得多的 t 值。


剩余93页未读,继续阅读
4248 浏览量
278 浏览量
122 浏览量
2023-08-21 上传
147 浏览量
175 浏览量
370 浏览量

HD1106
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多播静态路由引起的循环问题
- WHR系列产品简易说明手册
- java学习文档及学习方法
- 宽带常用端口表宽带常用端口表
- SNMP的工作原理软件开发
- 2008年上半年信息系统项目管理师试题
- RAID介绍、制作及安装系统
- J2EE系统之-hibernate学习总结
- 项目管理知识体系指南2000
- 嵌入式Linux系统开发技术详解-基于ARM 第5章
- J2EE体系之-JSP学习
- FPGA设计软件quartus2使用教程
- J2EE体系统一,关于JDBC
- Linux网络编程 关于linux网络编程的入门书籍
- IIS系统漏洞大全(详细介绍若干年一来所存在的问题和解决方案)
- JavaEye新闻月刊 - 2009年2月 - 总第12期.pdf
