Python实战:pandas、Matplotlib、爬虫库request与bs4详解
需积分: 14 85 浏览量
更新于2024-07-09
收藏 1.08MB PDF 举报
本文将介绍Python中常用的几个库,包括pandas、Matplotlib以及用于网络爬虫的request库和BeautifulSoup(简称bs4),并提供源码示例、详细解释和相关效果图。我们将探讨如何利用这些库进行数据分析、可视化以及网页抓取。
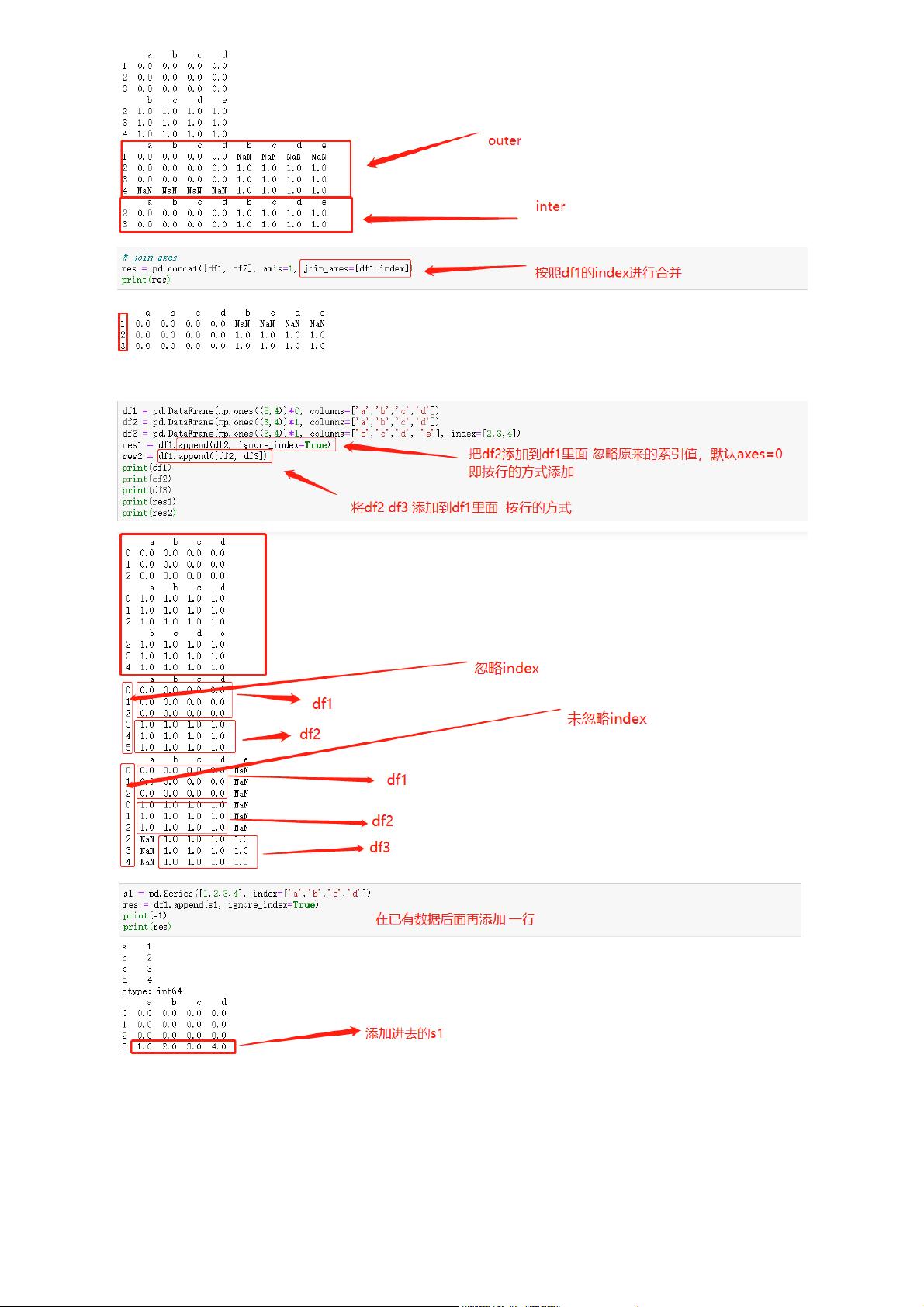
1. pandas库
- `pandas`是Python中一个强大的数据分析工具,可以方便地创建和操作数据集。
- 示例代码展示了如何使用pandas生成类似Excel的数据结构,如Series和DataFrame。
```python
import pandas as pd
s = pd.Series([1, 3, 6, np.nan, 4, 1]) # 生成一维数组
```
- 可以通过索引或条件选择数据,例如:
```python
df.loc['2016-01-01'] # 选择指定日期的数据
```
2. Matplotlib库
- `Matplotlib`是Python中最基础的绘图库,支持生成各种静态、动态和交互式图形。
- 如何绘制简单的图表:
```python
import matplotlib.pyplot as plt
plt.plot(list_0) # 绘制平方数列表
plt.show()
```
- 图形格式化,如设置坐标轴标签、标题等:
```python
plt.xlabel('X-axis Label')
plt.ylabel('Y-axis Label')
plt.title('My Graph')
```
3. request库
- `requests`库用于发送HTTP请求,是Python中进行网页抓取的首选库。
- 发送GET请求:
```python
import requests
response = requests.get('http://example.com')
print(response.text) # 打印响应的文本内容
```
- POST请求:
```python
payload = {'key1': 'value1', 'key2': 'value2'}
response = requests.post('http://httpbin.org/post', data=payload)
```
4. BeautifulSoup库(bs4)
- `bs4`库配合`requests`库用于解析HTML和XML文档,提取所需数据。
- 解析HTML文档:
```python
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('title').text
print(title) # 输出页面标题
```
- 查找和提取特定元素:
```python
links = soup.find_all('a') # 找到所有链接
for link in links:
print(link.get('href')) # 输出链接地址
```
5. Python基本技巧
- 使用`for`循环构造列表:
```python
list_0 = [example[i] for example in dataSet]
```
- 正则表达式(参考链接:https://docs.python.org/zh-cn/3.7/howto/regex.html?highlight=%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8Fs)
- 格式化输出保留一位小数:
```python
print("%.1f" % 0.13333) # 方法1
print("{:.1f}".format(0.13333)) # 方法2
round(0.13333, 1) # 方法3
```
通过掌握以上知识和库的使用,你可以有效地进行数据处理、可视化分析以及网络爬虫任务。结合源码、详细解释和示例效果,能够更好地理解和应用这些工具。
剩余28页未读,继续阅读
2017-07-03 上传
135 浏览量
2022-09-24 上传
2024-04-21 上传
2022-06-12 上传
2023-06-07 上传
2022-05-16 上传
2023-04-07 上传
2024-01-12 上传

薛定猫
- 粉丝: 1w+
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
