CUDA编程入门指南:NVIDIA GPU并行计算
"CUDA 入门教程,涵盖了计算统一设备架构、编程模型、GPU实现以及应用程序编程接口(API)的详细内容,适用于初学者学习CUDA编程。"
CUDA(Compute Unified Device Architecture)是NVIDIA推出的一种并行计算平台和编程模型,它允许开发者利用GPU(图形处理单元)的强大计算能力来解决高性能计算问题。CUDA通过提供C/C++编程接口,使得程序员可以直接编写GPU代码,执行数据并行计算任务。
1. **CUDA计算模型**:
- **计算统一设备架构**:CUDA将GPU视为一个完整的计算平台,可以执行通用计算任务,而不仅仅是图形渲染。
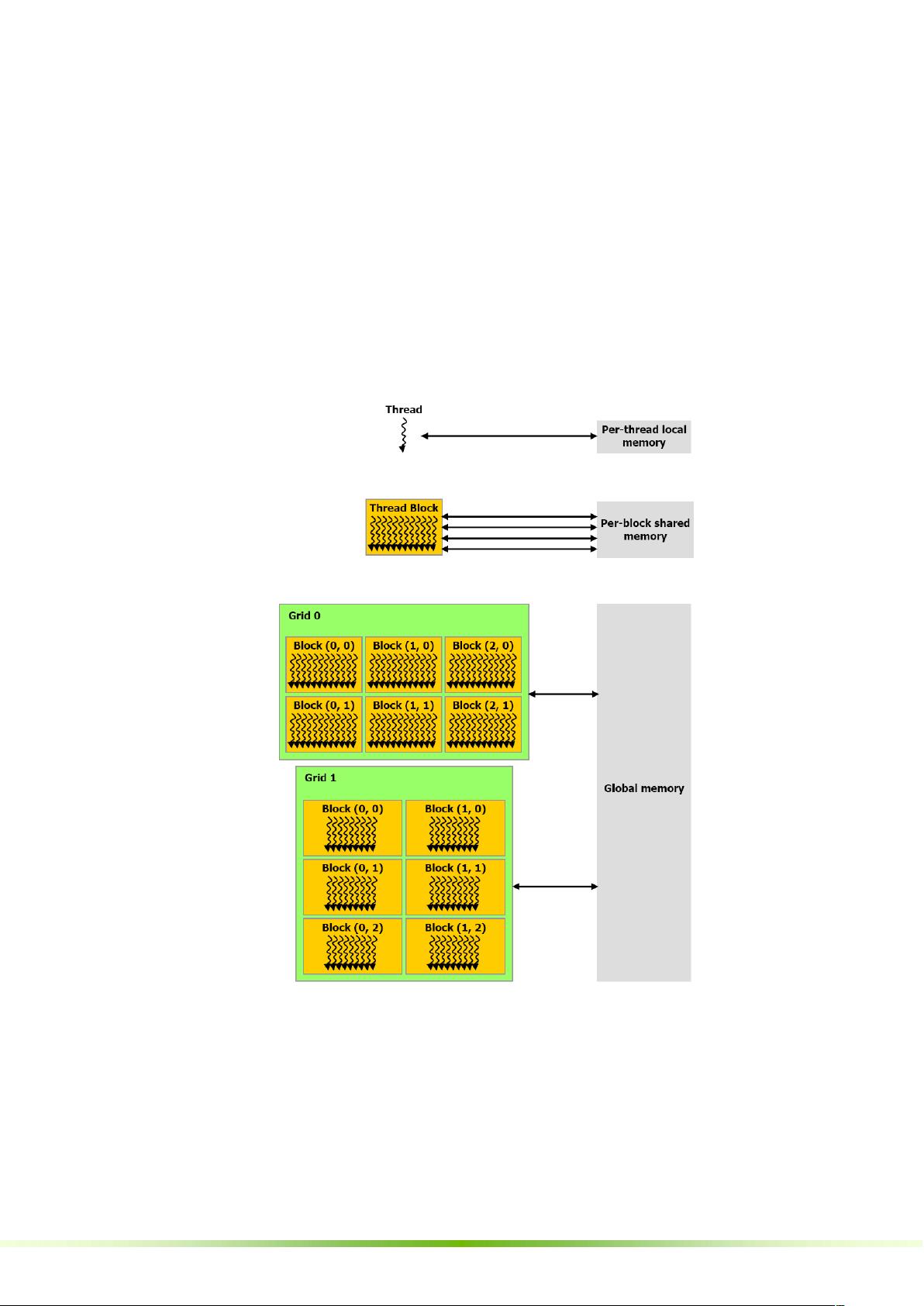
- **线程层次结构**:CUDA中的计算由线程块(thread blocks)组成,线程块又组织成格栅(grids)。线程块内的线程可以高效地同步,而不同线程块之间则通过全局内存通信。
- **存储器层次结构**:包括全局内存、共享内存、常量内存和寄存器,每种都有其特定的访问速度和使用场景。
2. **GPU实现**:
- **SIMT多处理器**:GPU内部的多处理器采用单指令多线程(SIMT)架构,每个流处理器(SP)可以同时执行多个线程。
- **多个设备**:一个系统可能有多个CUDA设备,可以通过编程选择使用哪个GPU。
- **模式切换**:CUDA支持GPU在执行图形任务和计算任务之间的快速切换。
3. **CUDA编程接口**:
- **C/C++扩展**:CUDA提供了对C/C++语言的扩展,如函数和变量的类型限定符。
- `_device_`:定义在GPU设备上执行的函数。
- `_global_`:定义可在主机和设备间迁移的函数。
- `_host_`:定义在主机(CPU)上执行的函数。
- `_constant_`:用于存储在常量内存中的变量。
- `_shared_`:用于存储在共享内存中的变量。
- **执行配置**:如`gridDim`、`blockIdx`、`blockDim`和`threadIdx`等内置变量用于指定线程的组织方式。
- **编译选项**:如`__noinline__`和`#pragma unroll`控制代码优化。
- **通用运行时组件**:包括内置向量类型(如`float4`)、`dim3`类型(表示3D尺寸)、数学函数库、计时函数以及纹理功能。
4. **编程实践**:
- **纹理内存**:CUDA支持纹理内存,这是一种优化的高速缓存,特别适合于访问模式可预测的大数据集。
- **CUDA数组**:可以直接在GPU内存中创建数组,提供高效的数据访问。
CUDA编程涉及的概念和细节较多,包括内存管理、同步机制、错误处理和性能优化等。掌握CUDA编程可以极大地提升计算密集型任务的执行效率,尤其是在物理模拟、图像处理、机器学习等领域。学习CUDA需要理解并行计算的基本概念,并熟悉GPU的硬件特性。

第 2 章 编程模型
CUDA 允许程序员定义称为内核(kernel)的 C 语言函数,从而扩展了 C 语言,在调用此类函数时,它将
由 N 个不同的 CUDA 线程并行执行 N 次,这与普通的 C 语言函数只执行一次的方式不同。
在定义内核时,需要使用 _global_ 声明说明符,使用一种全新的 <<<…>>> 语法指定每次调用的 CUDA
线程数:
// Kernel definition
__global__ void vecAdd(float* A, float* B, float* C)
{
}
int main()
{
// Kernel invocation
vecAdd<<<1, N>>>(A, B, C);
}
执行内核的每个线程都会被分配一个独特的线程 ID,可通过内置的 threadIdx 变量在内核中访问此 ID。
以下示例代码将大小为 N 的向量 A 和向量 B 相加,并将结果存储在向量 C 中:
__global__ void vecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
// Kernel invocation
vecAdd<<<1, N>>>(A, B, C);
}
执行 vecAdd( ) 的每个线程都会执行一次成对的加法运算。
2.1 线程层次结构
为方便起见,我们将 threadIdx 设置为一个包含 3 个组件的向量,因而可使用一维、二维或三维缩影标识
线程,构成一维、二维或三维线程块。这提供了一种自然的方法,可为一个域中的各元素调用计算,如
向量、矩阵或字段。下面的示例代码将大小为 NxN 的矩阵 A 和矩阵 B 相加,并将结果存储在矩阵 C 中:
__global__ void matAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
// Kernel invocation
dim3 dimBlock(N, N);
matAdd<<<1, dimBlock>>>(A, B, C);
}
线程的索引及其线程 ID 有着直接的关系:对于一维块来说,两者是相同的;对于大小为 (D
x
,
D
y
) 的二维
块来说,索引为 (x,y) 的线程的 ID 是 (x + yD
x
);对于大小为 (D
x
,
D
y
,
D
z
) 的三维块来说,索引为
(x, y, z) 的线程的 ID 是 (x + yD
x + Z
D
x
D
y
)。
4 CUDA 编程指南,版本 2.0

剩余63页未读,继续阅读
1010 浏览量
139 浏览量
1243 浏览量
163 浏览量
2022-09-14 上传

LING2YUN
- 粉丝: 3
- 资源: 19
 我的内容管理
展开
我的内容管理
展开







最新资源
- torch_cluster-1.5.6-cp36-cp36m-linux_x86_64whl.zip
- D-无人机:拉无人机。 使用计算机视觉在喷漆墙上画画以实现精确导航
- myloader
- Metro_Jiu-Jitsu-crx插件
- 导航条,鼠标悬停滑动下拉二级导航菜单
- 中国企业文化理念:提炼与实施的流程及方法(第一天课程大纲)
- 使用videojs/aliplayer 实现rtmp流的直播播放
- irt_parameter_estimation:基于项目响应理论(IRT)的物流项目特征曲线(ICC)的参数估计例程
- visualvm_21.rar
- torch_sparse-0.6.4-cp38-cp38-linux_x86_64whl.zip
- redratel:数字代理
- JumpStart!-开源
- api-2
- Adoptrs-crx插件
- redis windows x64安装包msi格式的
- XX轧钢企业文化诊断报告
