南洋理工于涵:联邦学习中的博弈论——激励机制与收益分配
需积分: 50 21 浏览量
更新于2024-07-16
收藏 4.94MB PDF 举报
联邦学习作为一种新兴的分布式机器学习技术,近年来在保护数据隐私的同时提高模型性能方面展现出巨大潜力。本研究由新加坡南洋理工大学的于涵副教授和李光耀研究员主导,关注于联邦学习中的博弈论应用。他们探讨了在构建数据联盟时如何通过博弈论框架来设计有效的激励机制,确保数据持有者(Agent/DataOwner)积极参与并维持数据质量。
首先,定义了联邦学习的基本概念,包括联邦模型(Federated Model),这是一个由多个数据持有者(参与者1到N)利用联邦学习方法共同构建的模型。每个参与者贡献自己的数据集,而联邦模型的收益则可能影响效用(Utility)和支付(Payment)。效用表示参与者对联盟的贡献价值,支付则可能涉及参与者间的资金流动,可能是报酬也可能是费用。
在联邦学习中,数据联盟的可持续性关键在于吸引和保留高质量数据。研究者提出通过量化参与者在联盟中的贡献(𝑢𝑢𝑖𝑖(𝑡𝑡))来决定收益分配,这涉及到三种不同的博弈论方案:平均主义、边际收益和边际损失。平均主义策略将联盟收益平均分给所有参与者;线性分配则根据参与者对整体收益的相对贡献进行比例分配。
例如,ShuoYang等人在2017年的研究中提出了数据质量意识下的真实值估计和剩余收益共享方法,强调了在移动 crowdsensing 中公平的收益分配对于激励用户参与的重要性。他们建议采用平均主义分配,即在每个时间点将总预算(𝐵𝐵(𝑡𝑡))平等地分配给所有参与者。
然而,为了最大化集体效用(𝑈𝑈),博弈论方法需要平衡公平与效率,找到一个既能鼓励参与者积极投入又能保持联盟稳定性的收益分配策略。线性分配方案提供了一个根据数据持有者的实际贡献调整收益的选项,但具体实施需要权衡不同参与者之间的利益冲突和激励效果。
总结来说,该论文深入分析了联邦学习中博弈论的应用,尤其是通过收益分配博弈解决数据共享和激励问题,这对于推动联邦学习在实际场景中的落地实施具有重要意义。通过理解和优化这些博弈策略,可以提升联邦学习的实用性和可持续性,进一步促进数据安全和隐私保护下的合作学习环境的发展。
7
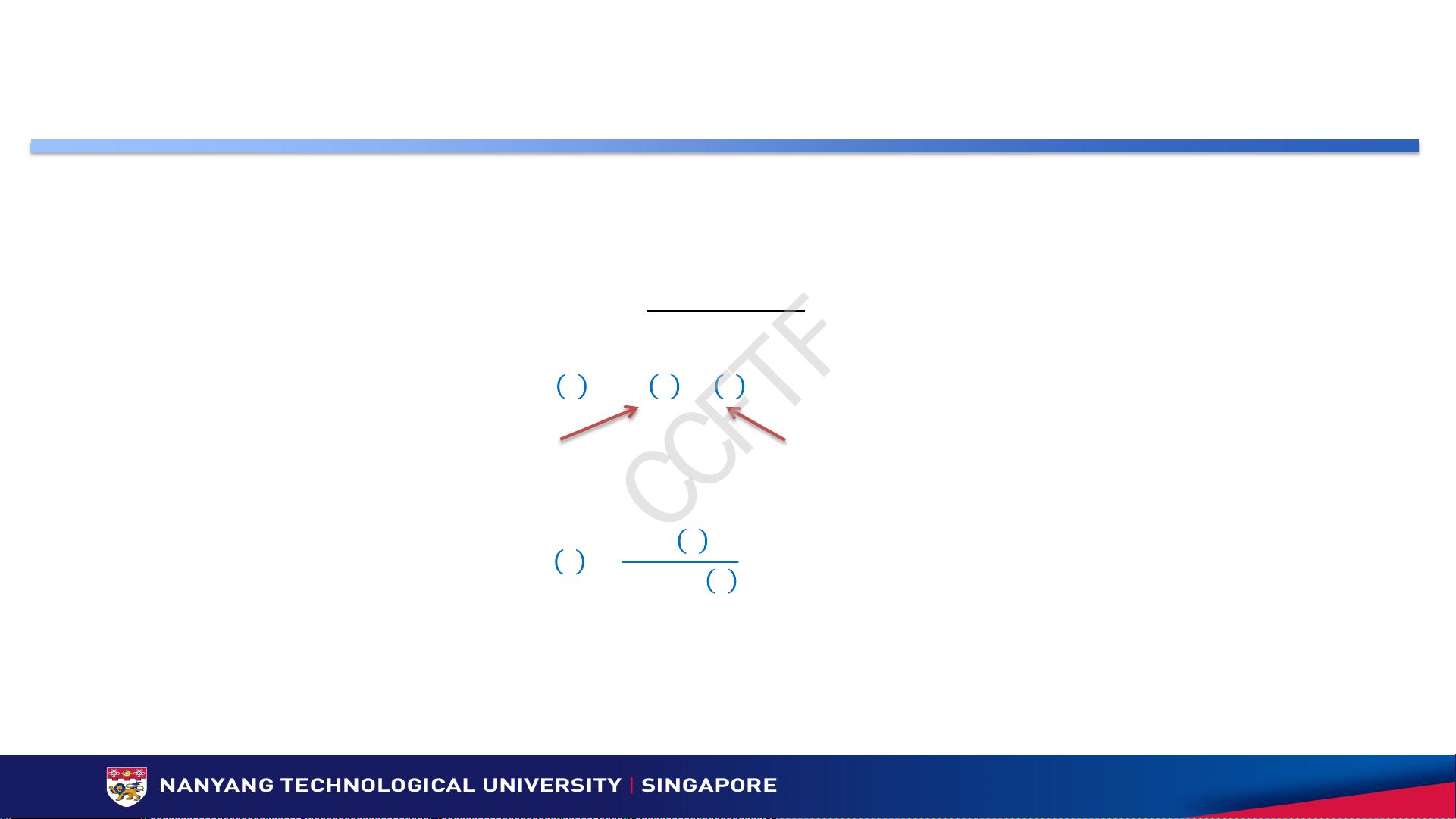
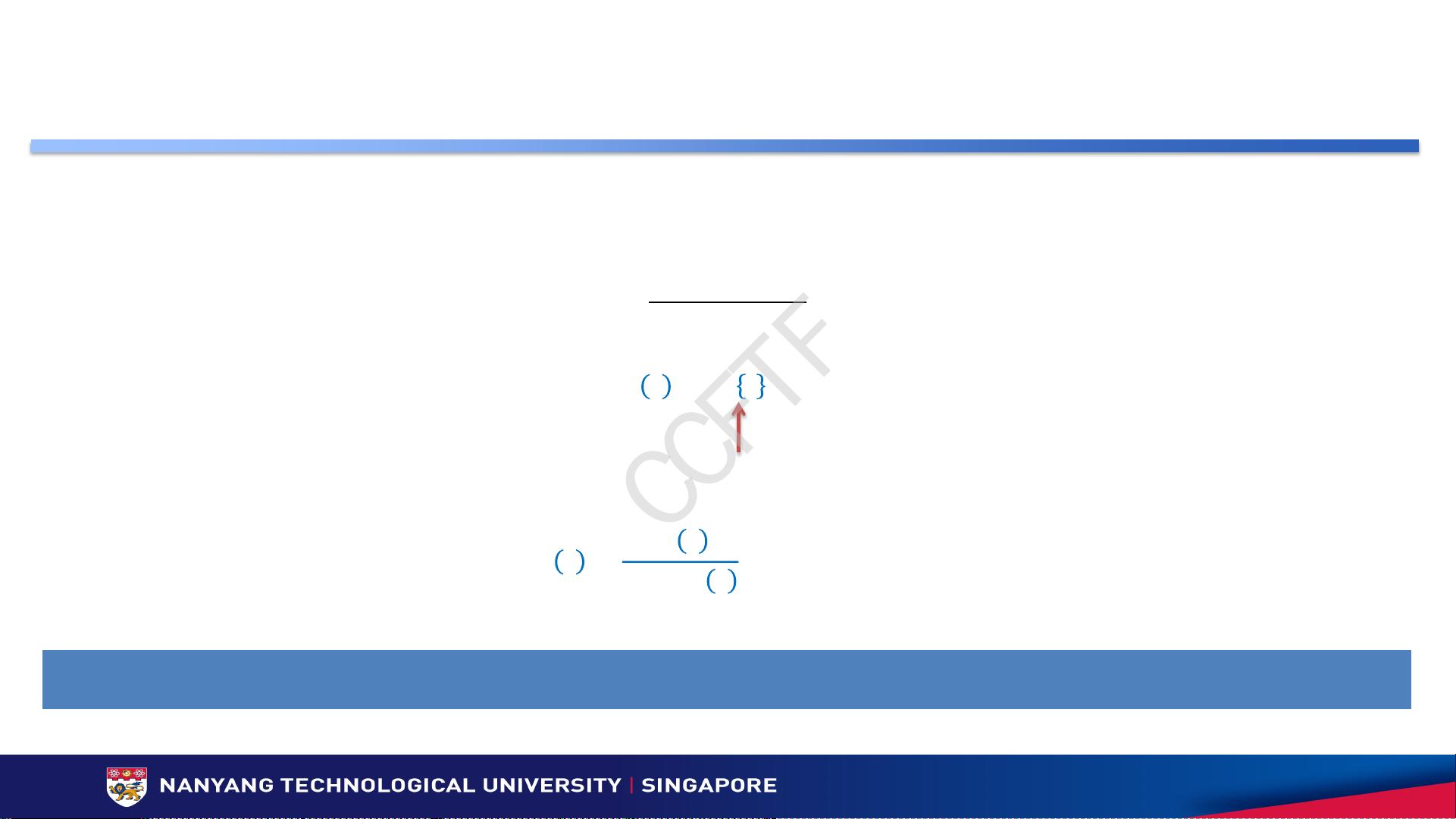
收益分配方案– Linear线性分配
参与者i在总收益中的占比与其所贡献的数据质量和数量之乘机成正比
(边际收益)
=
=
()
数据质量
数据数量
每个时间点的收益分配法:
CCFTF
剩余39页未读,继续阅读
2019-10-30 上传
2010-07-14 上传
2021-03-13 上传
2010-07-14 上传

senhehe
- 粉丝: 0
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- MA82G5D16.zip
- memoryleakexample
- 简书练习代码Demo
- 华为服务器RH2288hv3 BIOS.zip
- 智能电源无线充电解决方案(原理图、PCB源文件、设计报告等)-电路方案
- composed-validations:有意义的Javascript验证库
- test-action-001
- baseJava
- 电子功用-基于多合一传感器的电缆线路在线监测系统
- react-component-boilerplate:React 组件样板。 使用 Karma 快速、持续地测试您的组件
- 密码学校_作业
- DebtCount
- QuickStack:前端Webapp和后端微服务模板,可以作为一个整体运行,也可以作为单独的Webapps微服务运行
- 基于NT0880 电梯完整解决方案(整个功能模块原理图、PCB源文件、视频演示)-电路方案
- Java进阶高手课-并发编程透彻理解
- Android实现3D图像显示源代码
