多视图缺失数据补全:ILCA方法与低秩稀疏建模
需积分: 5 28 浏览量
更新于2024-08-26
收藏 1.4MB PDF 举报
随着医疗诊断、网页分类和多媒体分析等众多场景的发展,多视图数据变得日益普遍。然而,一个重要的挑战是并非所有实例在所有视图中都有完整的数据,导致存在缺失视图问题。本文关注的是在多视图数据中进行特征级别的缺失数据补全。
首先,为了捕捉不同视图之间的语义互补性和相同的分布特性,作者提出了一种Isomorphic Linear Correlation Analysis (ILCA)方法。ILCA的核心思想是通过学习一组优秀的同构特征,将多视图数据线性映射到一个特征同构子空间中,这样可以有效地挖掘不同视图之间的共享信息。这种方法强调了特征之间的内在联系,使得即使在缺失情况下也能利用其他视图的结构来推断缺失部分。
接着,论文假设缺失视图的数据服从正态分布,这有助于构建更精确的模型。基于这一假设,缺失视图数据矩阵被分解为低秩成分和稀疏贡献两部分。这样的分解有助于识别数据中的潜在模式和异常值,因为正常情况下,大部分数据应该具有一定的规律性,而缺失的部分则可能是随机或异常的。
为了实现缺失视图的补全,研究人员采用了一种结合了低秩和稀疏成分的策略。他们提出了一种方法,通过学习到的低秩结构来估计缺失数据的全局趋势,同时利用稀疏成分捕捉可能的局部特征。这个过程旨在最大限度地保留数据的分布特征,确保补全后的数据不仅在统计上合理,而且在内容上也与原始数据保持一致性。
最后,该研究还可能涉及优化算法和评估指标,以确保补全过程的有效性和鲁棒性。通过实验验证,ILCA方法能够显著提高多视图数据的学习性能,减少由于缺失数据导致的信息损失,并且在实际应用中展现出良好的可扩展性和适应性。
总结来说,这篇研究论文探讨了在多视图数据中处理缺失问题的方法,重点在于利用ILCA和低秩-稀疏分解策略,旨在发现和利用跨视图的结构信息来完成缺失数据,这对于多源数据融合和跨模态学习至关重要。通过这种方式,该研究为解决实际问题中的多视图数据处理提供了一个有效且实用的解决方案。
Extensive experiments on four multi-view datasets
are conducted to demonstrate the effectiveness of
the proposed framework.
1.2 Organization
The remainder of this paper is organized as follows: We
present a general feature-level framework for completing
missing view to obtain the integrated representations for
multi-view data in Section 2.1. In Section 2.2, a novel Iso-
morphic Linear Correlation Analysis model is developed
for correlating different views through learning a set of
excellent isomorphic features. We build a new Identical Dis-
tribution Pursuit Completion model to recover missing
view of multi-view data under both semantic complemen-
tarity and identical distribution restraints in Section 2.3. Fur-
thermore, Section 3 provides an efficient algorithm to solve
the proposed framework and analyzes the computational
complexities and convergence rates of the proposed algo-
rithms. Section 4 gives a broad overview of some related
work. Experimental results and analyses are reported in
Section 5. Section 6 concludes this paper.
1.3 Notations
Here we establish some notations to be used throughout
this paper. Assume V
x
and V
y
are two different views. Let
the data matrices X
E
¼½x
1
; ...;x
n
1
T
2 R
n
1
d
x
and Y
E
¼
½y
1
; ...;y
n
1
T
2 R
n
1
d
y
be two sets of existing heterogeneous
representations from the V
x
and V
y
, respectively, where
x
i
2 R
d
x
is the ith sample from V
x
, y
i
2 R
d
y
is the ith sample
from V
y
, n
1
is the number of available samples, and d
x
and
d
y
are the dimensionalities of the heterogeneous low-level
feature spaces V
x
and V
y
. Note that for i ¼ 1; ...;n
1
, ðx
i
;y
i
Þ
represents the ith couple of heterogeneous representations.
We assume that both fx
i
g
n
1
i¼1
and fy
i
g
n
1
i¼1
are centered, i.e.,
P
n
1
i¼1
x
i
¼ 0 and
P
n
1
i¼1
y
i
¼ 0. Let the data matrix X
M
¼
½x
n
1
þ1
; ...;x
n
1
þn
2
T
2 R
n
2
d
x
be a set of missing representa-
tions from the V
x
and the data matrix Y
M
¼½y
n
1
þ1
; ...;
y
n
1
þn
2
T
2 R
n
2
d
y
be a set of existing heterogeneous repre-
sentations from the V
y
corresponding to the missing repre-
sentations X
M
.
We use jjAjj
¼
P
r
i¼1
s
i
to denote the trace (nuclear)
norm of a matrix A ¼½a
ij
2R
pq
, where r ¼ rankðAÞ
denotes the rank of A and fs
i
g
r
i¼1
is the set of singular val-
ues of A in a non-increasing order. jjAjj
F
¼
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi
P
p
i¼1
P
q
j¼1
a
2
ij
q
is the Frobenius norm of A.IfA is a square matrix, then let
trðAÞ¼
P
p
i¼1
a
ii
be the trace of A. For two matrices A and
B, hA; Bi¼trðA
T
BÞ denotes the matrix inner product. For a
vector b 2 R
p
, let jjbjj
2
¼
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi
P
p
i¼1
b
2
i
p
be the ‘
2
-norm of b.
Additionally, let jHj be the number of elements in the set
H; ÏfðCÞ denotes the gradient of any smooth function fðÞ
at the point C; for w 2 R
p
, we denote by diagðwÞ the diago-
nal matrix having the components of the vector w on the
diagonal; let D be a set of representations, meanðDÞ denotes
the average value of D. I
k
2 R
k
is an identity matrix.
2THE PROPOSED FORMULATION
We propose a general feature-level framework to complete
missing view of multi-view data. A graphical illustration of
the proposed formulation is given in Fig. 4 to facilitate the
understanding the proposed formulations and algorithms
significantly.
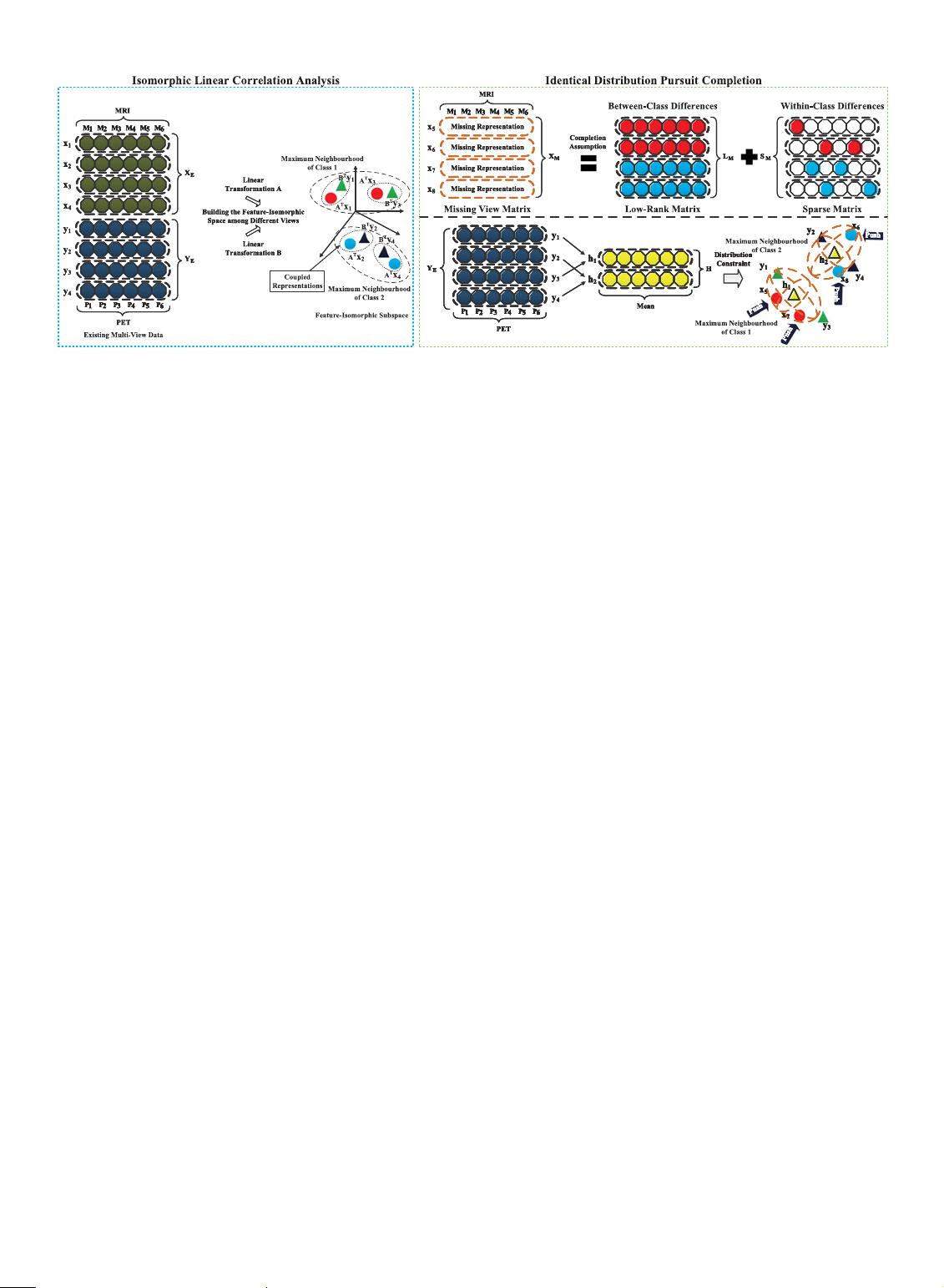
2.1 Overview of the Proposed Formulations
We provide an overview of the proposed formulations by
using the example in Fig. 4. In this example, a set of multi-
view data consists of the views MRI and PET. However, the
MRI view is missing, such as all attributes in the representa-
tions x
5
, x
6
, x
7
, and x
8
are totally absent.
To recover missing view of multi-view data, a feature-
isomorphic subspace is learned by ILCA model to build a
bridge between multiple heterogeneous low-level feature
spaces in the proposed framework, in which the same
dimension and attributes are used to represent the same
semantic concept. Specifically, to fully exploit both semantic
complementarity and similar distributions among different
views as shown in Fig. 3, multiple linear transformations A
and B are learned using the existing multi-view data X
E
and Y
E
to eliminate the heterogeneity across them. Thus, a
feature-isomorphic subspace is obtained by a set of learned
excellent isomorphic features, in which the correlated repre-
sentations from different views are coupled together to
capture the commonality among the heterogeneous repre-
sentations from different views. Consequently, some maxi-
mum neighbourhoods are established among different
categories, such as the maximum neighbourhoods of Class
1 and Class 2 in Fig. 4. We can measure the correlation
among the multi-view data in the feature-isomorphic
Fig. 4. The proposed framework for completing missing view of multi-view data.
1298 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 30, NO. 7, JULY 2018
剩余13页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
158 浏览量
2021-07-14 上传
2021-09-25 上传
2023-02-23 上传
2021-04-06 上传
2024-05-23 上传

weixin_38571104
- 粉丝: 3
- 资源: 944
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
