




6西格玛质量控制:数据处理与Statistical软件分析
版权申诉
60 浏览量
更新于2024-06-30
收藏 2.29MB DOC 举报
"该文档是关于6西格玛质量控制的数据处理与分析的教程,源自理学院《试验设计及质量控制》课程的实验报告。实验时间为2013年12月11日,旨在让学习者掌握6西格玛过程、Statistical软件的运用以及如何在该软件环境下进行数据处理和分析,包括描述统计、直方图、箱线图和假设检验(单样本t检验和两独立样本t检验)。"
在6西格玛质量控制中,数据处理和分析是至关重要的环节,它帮助我们识别和改进过程中的缺陷,以达到近乎完美的产品质量。实验内容首先介绍了描述统计,包括计算变量的均值、中位数、标准差、最小值、最大值和极差,这些指标提供了数据集的基本特征。Statistical软件被用来执行这些计算,简化了数据分析的过程。
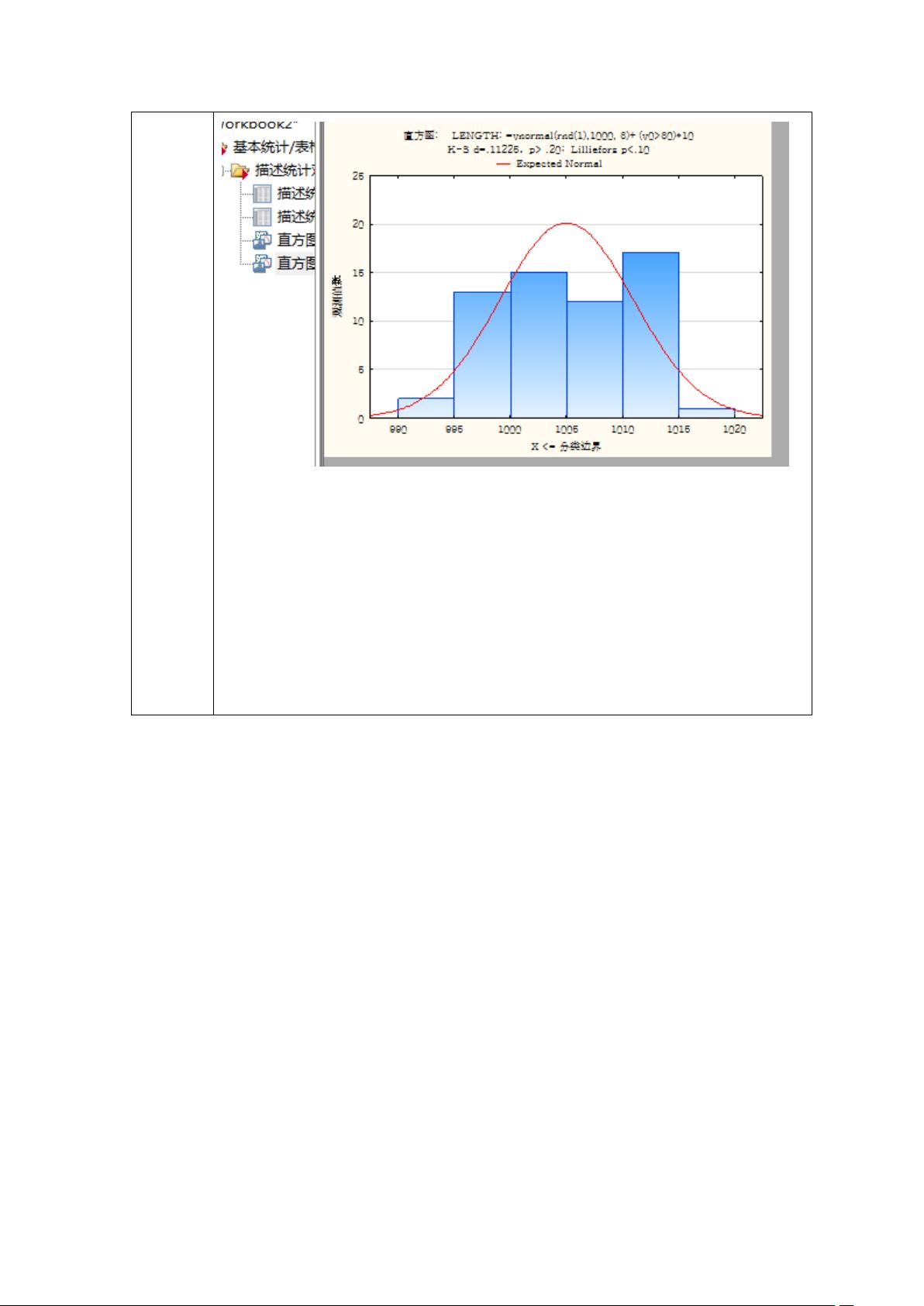
接着,实验展示了如何利用软件绘制直方图,这是一种可视化工具,能直观地展示数据分布的形状和集中趋势。通过观察直方图,可以判断数据是否接近正态分布或其他类型分布,这对于后续的统计分析非常关键。
此外,箱线图(盒须图)也是6西格玛中常用的工具,用于显示数据的五数概括(最小值、下四分位数、中位数、上四分位数、最大值),它可以清晰地展示数据的离群值和分布范围,对于理解数据的变异性和异常情况非常有用。
实验还涉及了假设检验,首先是单样本t检验,用于比较观测数据与已知标准值的差异。在这个例子中,比较的是百公里耗油量是否显著改变了。如果P值大于显著性水平α(通常取0.05),则无法拒绝原假设,即认为数据并未显示出显著变化。在实验中,P值为0.085808,所以得出结论,百公里耗油量仍为8.48升,没有显著改进。
最后,进行了两独立样本t检验,用于比较两个独立群体的均值差异。同样,如果P值大于α,则两个群体的均值被认为无显著差异。在示例中,由于P值远大于0.05,结论是没有证据表明两组配件厚度的均值存在显著差异。
这个6西格玛实验强调了如何使用统计工具来理解和改进过程质量,通过具体的操作步骤,学生能够深入理解并应用6西格玛方法论,提升其在质量控制领域的实践能力。
第 3 页
3、箱线图。
点击统计→六西格玛→测量(M)→盒须图→变量→“1-2
为”反应变量,分类变量为 none→确定→确定,得到如下
结果:
下载后可阅读完整内容,剩余14页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-07-14 上传
2021-09-20 上传
2021-11-30 上传
2022-01-16 上传
2022-07-11 上传
2021-11-19 上传

kfcel5889
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开








最新资源
- s5pv210开发板NAND Flash驱动及测试案例
- PLC编程入门:基础知识与实用技巧解析
- C#开发的VLC视频播放器与插件工具包介绍
- 探索MastodonPleroma的Vivid材料设计前端
- Android屏幕与控件尺寸获取方法示例
- 移动平均图像阈值处理的Matlab实现
- 新版Android基础教程与开发笔记
- 如何将文件安全隐藏到GIF图片中
- MT6225芯片USB驱动安装全攻略
- 网页源代码高亮显示技术解析与应用
- 猛mm象:基于Mammoth的Android开源Mastodon客户端介绍
- 适合初学者的数据结构教学源程序资源
- 泛微EC集群部署及Nginx代理实现指南
- ASP开发的仓库管理系统:物资分类与库存查询
- 四川大学软件开发环境与工具复习资料全攻略
- SQL Server 2005精简版快速安装指南






















