缺失值插补对机器学习性能影响的深度探究
136 浏览量
更新于2024-06-17
收藏 2.37MB PDF 举报
"这篇论文是关于缺失值插补方法如何影响机器学习性能的文献回顾和分析,重点关注过去十年的研究。作者们从2010年至2021年8月间挑选了191篇相关文章,运用PRISMA技术进行系统性综述。文章讨论了缺失值插补的定义、理论、分析以及与机器学习分类模型的评价指标。通过12年的数据分析,揭示了MVI方法的发展趋势,并提出了一些包含MVI的机器学习管道在不同数据集上的表现。此外,文章还为未来的研究方向提供了指导。"
在医学信息学中,数据的质量至关重要,而缺失值是数据质量的一大挑战。缺失值插补(Missing Value Imputation, MVI)是处理这一问题的关键技术,它能提高机器学习模型的性能。根据数据缺失的模式,缺失值可以分为完全随机缺失(Missing Completely at Random, MCAR)、随机缺失(Missing at Random, MAR)和非随机缺失(Not Missing at Random, NMAR)。
在处理缺失值时,选择合适的插补方法至关重要。常见的MVI方法包括均值插补、中位数插补、最近邻插补(KNN)、多重插补(Multiple Imputation)、主成分分析插补、决策树插补等。每种方法都有其适用场景和优缺点,例如,均值插补简单但可能导致偏差,而KNN插补可以利用邻近样本的信息但计算成本较高。
机器学习模型的性能评估通常涉及精度、召回率、F1分数、AUC-ROC曲线等指标。在应用MVI方法后,这些指标可以帮助研究人员评估模型的预测能力是否得到提升。同时,通过比较不同插补方法的结果,可以找出最适合作为预处理步骤的插补策略。
论文中的研究发现,MVI方法的选择会直接影响机器学习模型的预测准确性和稳定性。随着技术的发展,深度学习和集成学习等先进方法也被应用于缺失值插补,它们可以更灵活地捕捉数据的复杂结构,但可能需要更多的计算资源。
在未来的研究中,重要的是继续探索和开发适应不同类型数据和任务的MVI方法,并结合领域知识优化插补过程。此外,对于非结构化数据(如文本、图像或时间序列数据)的缺失值处理,以及考虑缺失值的因果推断也是研究热点。最后,研究者应更加关注插补方法的解释性和模型的可解释性,这对于医疗、金融等领域的决策支持系统尤其重要。
M.K. Hasan
等人
医学信息学解锁
27
(
2021
)
100799
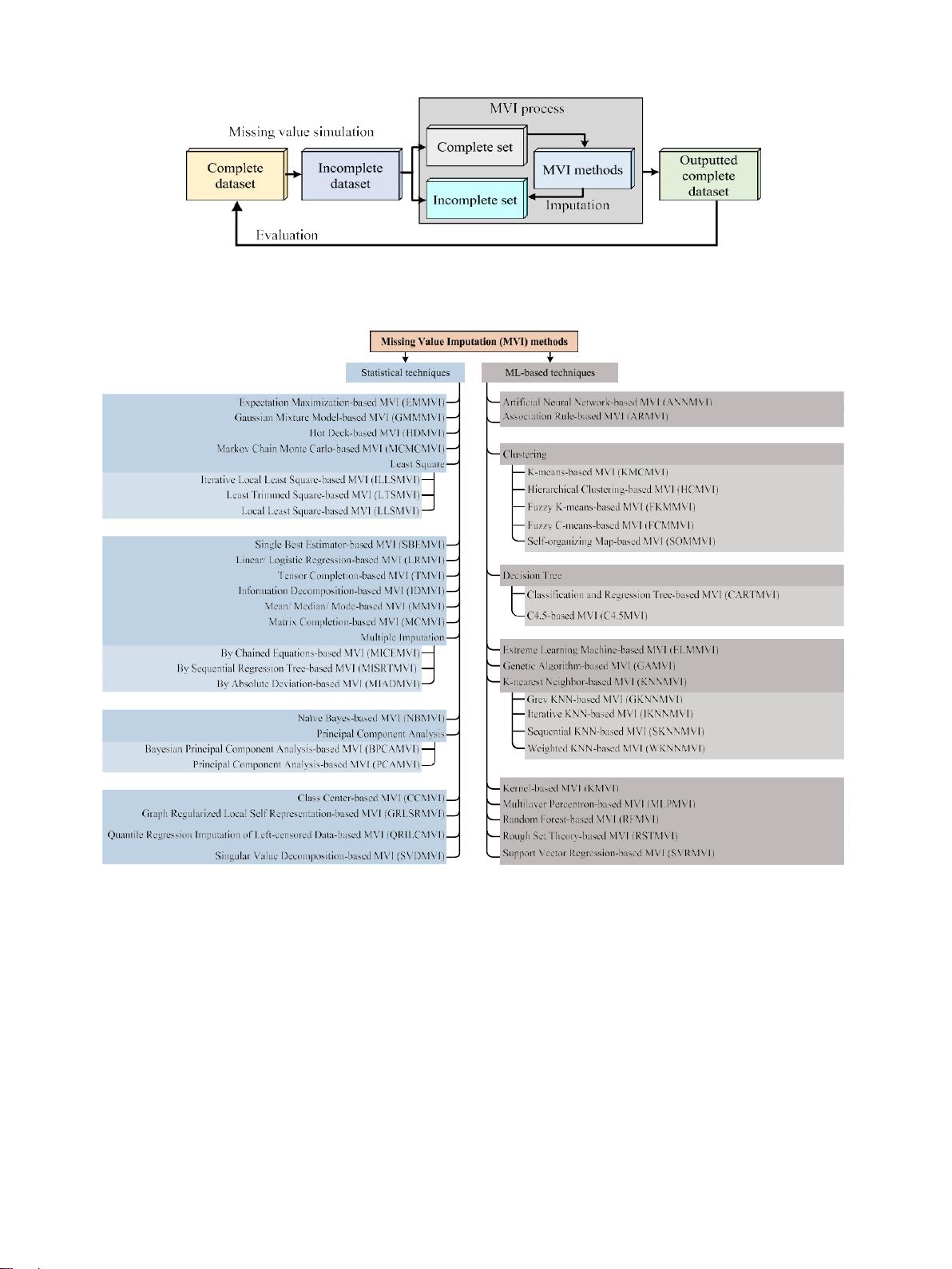
图3.第三章。MV I 程 序
的典型实验配置,用于插补任 何 属 性 中 的缺失值
。
图四、文 献
中 常用的
方法的 分 类 树 展 示 。
读者可以通过对它们的探索来获得详细的理论信息。大多数早期的调查
集中在解释系统的基本思想,其中最广泛的实践和对基于的
决策系统的影响没有得到明确的解释和审查。本文旨在提供一个全面的
调查方法与其他必要的相关研究。然而,表记录了年以来不
同发表文章中经常使用的所有统计和基于的系统 到年月
这一发现为初学者到专家级研究人员选择合适的算法用于其决策管
道提供了主要的猜测。从表中可以看出, 介绍了几种算法,如
、、、、、 、 、
、、、、
,和在过去十年(年至年月)中最经常使
用,与 图中的 所有其 他算法 相比。 四、
表说明了统计,例如和,以及基于的,例
如,和是过去十年(年至年月)中大量使用的插
补方法。 算法中的步从完整的数据中计算当前参数,然后步
通过最大化似然函数来现代化参数。该过程继续,直到它达到停止
标准,并且从更新的似然函数确定缺失值。在方法中,属性的缺
失值是从完整数据集中该属性的均值(平均值)、中位数(中间值)或
众数(最频繁)值估计的。然而,任何属性的正态分布具有相同的平均
值、中位数和众数,如中针对的实验证明。在策略
中,使用距离函数(通常为欧几里得距离),利用来自个最近观测值
的测量值来填充缺失值。的
剩余22页未读,继续阅读
2021-09-24 上传
2021-08-15 上传
2024-04-25 上传
2023-05-22 上传
2024-03-30 上传
2023-08-21 上传
2024-03-03 上传
2023-04-05 上传
2024-04-10 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Chrome ESLint扩展:实时运行ESLint于网页脚本
- 基于 Webhook 的 redux 预处理器实现教程
- 探索国际CMS内容管理系统v1.1的新功能与应用
- 在Heroku上快速部署Directus平台的指南
- Folks Who Code官网:打造安全友好的开源环境
- React测试专用:上下文提供者组件实现指南
- RabbitMQ利用eLevelDB后端实现高效消息索引
- JavaScript双向对象引用的极简实现教程
- Bazel 0.18.1版本发布,Windows平台构建工具优化
- electron-notification-desktop:电子应用桌面通知解决方案
- 天津理工操作系统实验报告:进程与存储器管理
- 掌握webpack动态热模块替换的实现技巧
- 恶意软件ep_kaput: Etherpad插件系统破坏者
- Java实现Opus音频解码器jopus库的应用与介绍
- QString库:C语言中的高效动态字符串处理
- 微信小程序图像识别与AI功能实现源码
