MapReduce详解:大数据处理的关键技术与应用
需积分: 10 51 浏览量
更新于2024-07-15
收藏 1.14MB PDF 举报
本资源是一份关于《大数据处理技术》的教学资料,由昆明理工大学计算机科学与技术系的周海河教授编撰。章节内容聚焦于第7章MapReduce,该章详细介绍了MapReduce的概念、体系结构、工作流程以及其在大数据处理中的应用。
首先,7.1节概述了分布式并行编程的重要性。提到“摩尔定律”的衰减使得单机处理能力无法满足快速增长的数据需求,促使人们转向分布式并行编程,如MapReduce模型。MapReduce由谷歌提出,以Hadoop作为开源实现,它降低了技术门槛,利用大规模计算机集群进行并行计算,提供强大的处理能力。
在传统并行计算框架(如MPI)与MapReduce的对比中,MapReduce具有显著优势。MPI强调共享式计算,但容错性较差,而MapReduce采用非共享式设计,具有更好的容错性。此外,MapReduce通过使用廉价的PC机和分布式网络,降低了硬件成本,提高了扩展性。编程上,MapReduce的接口更简单,只需要关注“what”而不是“how”,降低了学习难度。
MapReduce的核心是其简化的工作流程,包括Map函数和Reduce函数。Map函数负责将输入数据划分为多个小任务,进行预处理,而Reduce函数则将Map阶段的结果进行汇总和聚合。这个模型极大地简化了并行处理的复杂性,适用于批处理和大规模数据分析,特别是对于非实时、数据密集型任务更为适用。
实例分析部分,可能会深入探讨如何使用MapReduce实现经典的WordCount任务,即统计文本中单词的频率。这将展示MapReduce在实际项目中的应用技巧。
最后,7.6章可能涵盖了MapReduce的编程实践,介绍如何在Hadoop等平台上编写和优化MapReduce程序,包括最佳实践和性能调优策略。
这份资料不仅提供了理论背景,还包含丰富的实践经验,对理解和应用MapReduce在大数据处理中的作用非常有帮助。
《大数据处理技术》 昆明理工大学计算机科学与技术系 周海河 18908715777@189.cn
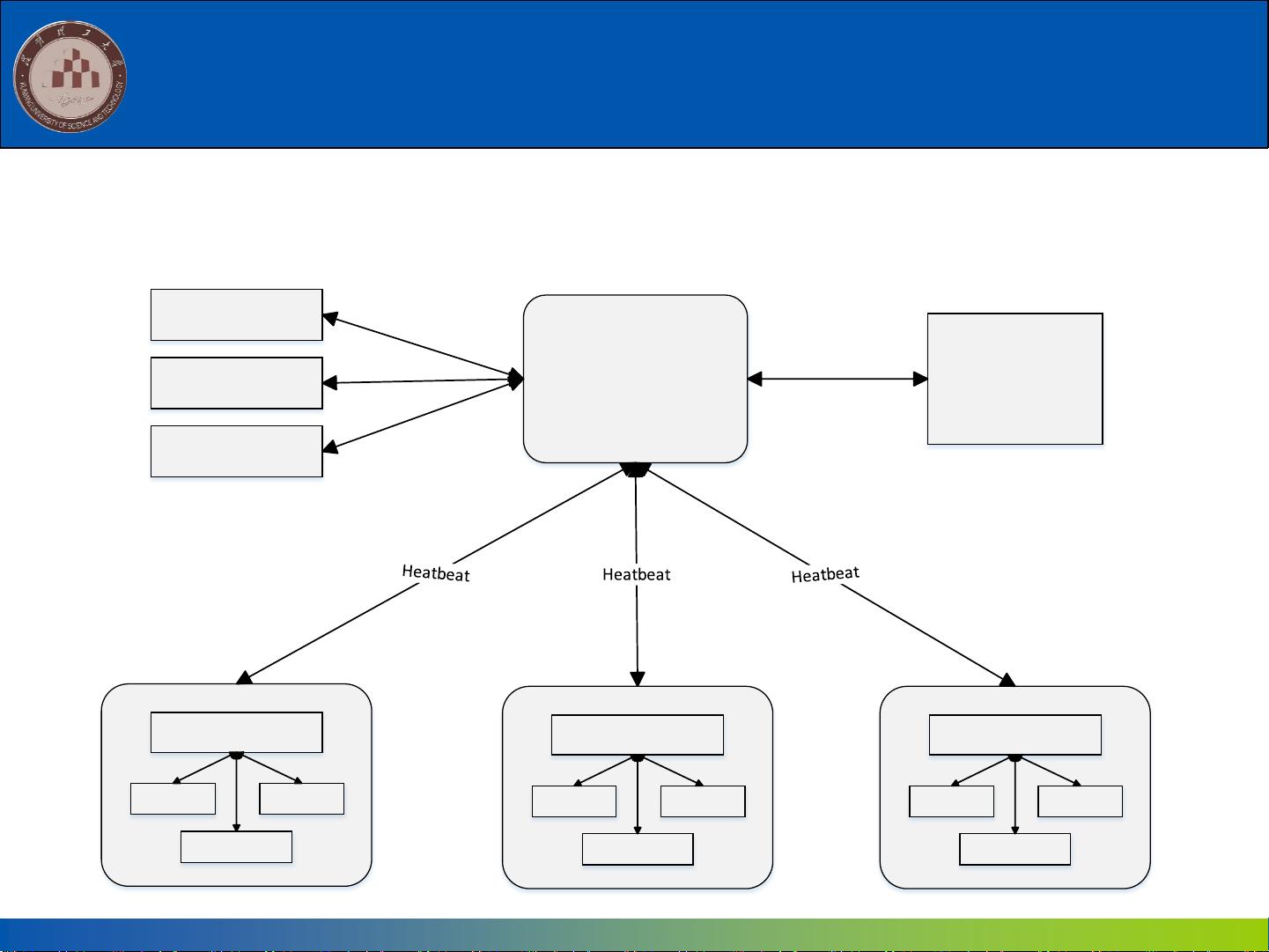
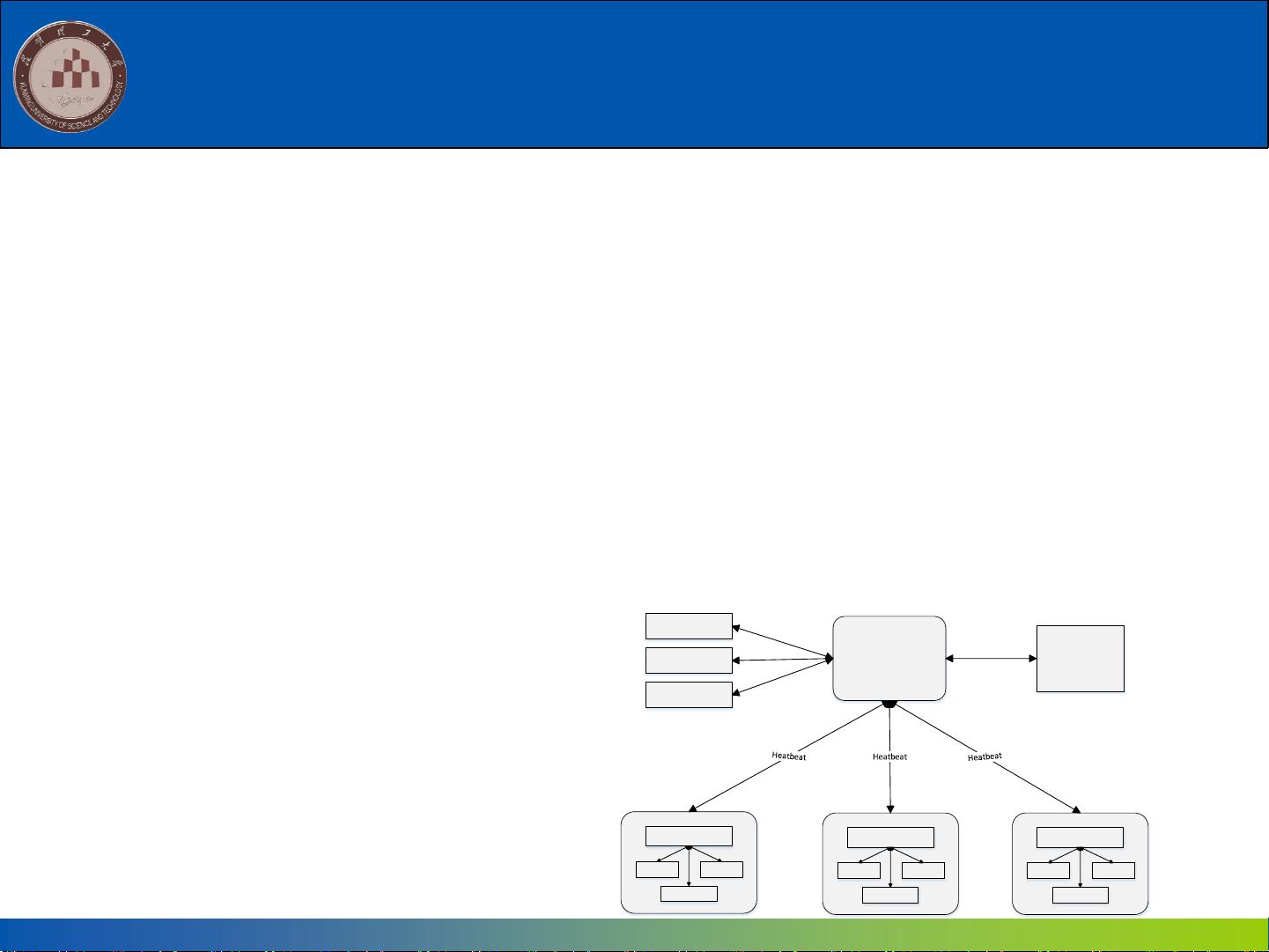
7.2 MapReduce的体系结构
Client
Client
Client
Task SchedulerJobTracker
TaskTracker
Map Task
Reduce Task
Map Task
TaskTracker
Map Task
Reduce Task
Map Task
TaskTracker
Map Task
Reduce Task
Map Task
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、
TaskTracker以及Task
剩余39页未读,继续阅读
2023-05-27 上传
2023-05-27 上传
2023-05-27 上传
2023-05-27 上传
2021-10-11 上传
2021-03-05 上传
2017-12-03 上传
2018-05-17 上传
2022-11-12 上传

kmzhouhaihe
- 粉丝: 0
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
