Word2vec深入解析与应用实践
"这篇报告是Hendrik Heuer在Stockholm NLP Meetup上关于Word2vec的分享,深入浅出地介绍了Word2vec从理论到实际应用的各个方面。"
在自然语言处理领域,Word2vec是一种流行且重要的工具,它由Mikolov、Sutskever、Chen、Corrado和Dean等人在Google开发,并在2013年的NAACL会议上首次提出。Word2vec的核心思想是通过分析大量文本语料库,将每个单词转化为高维空间中的向量表示,这些向量能够捕获词汇之间的语义和关系。J.R. Firth的名言“一个词的意义在于它所处的上下文”在此得到体现,即“词的含义可以通过它周围的词来理解”。
Word2vec模型主要包含两种学习算法:连续词袋(CBOW)和连续滑窗(Skip-gram)。CBOW算法的目标是基于单词的上下文(即周围的词)来预测当前单词,它忽略了词序信息,适用于大文本语料的快速训练。而Skip-gram则相反,它试图最大化根据目标词来分类上下文中其他词的能力,从而更侧重于捕捉单词间的局部依赖关系,对于捕捉词汇的相对位置信息更为敏感。
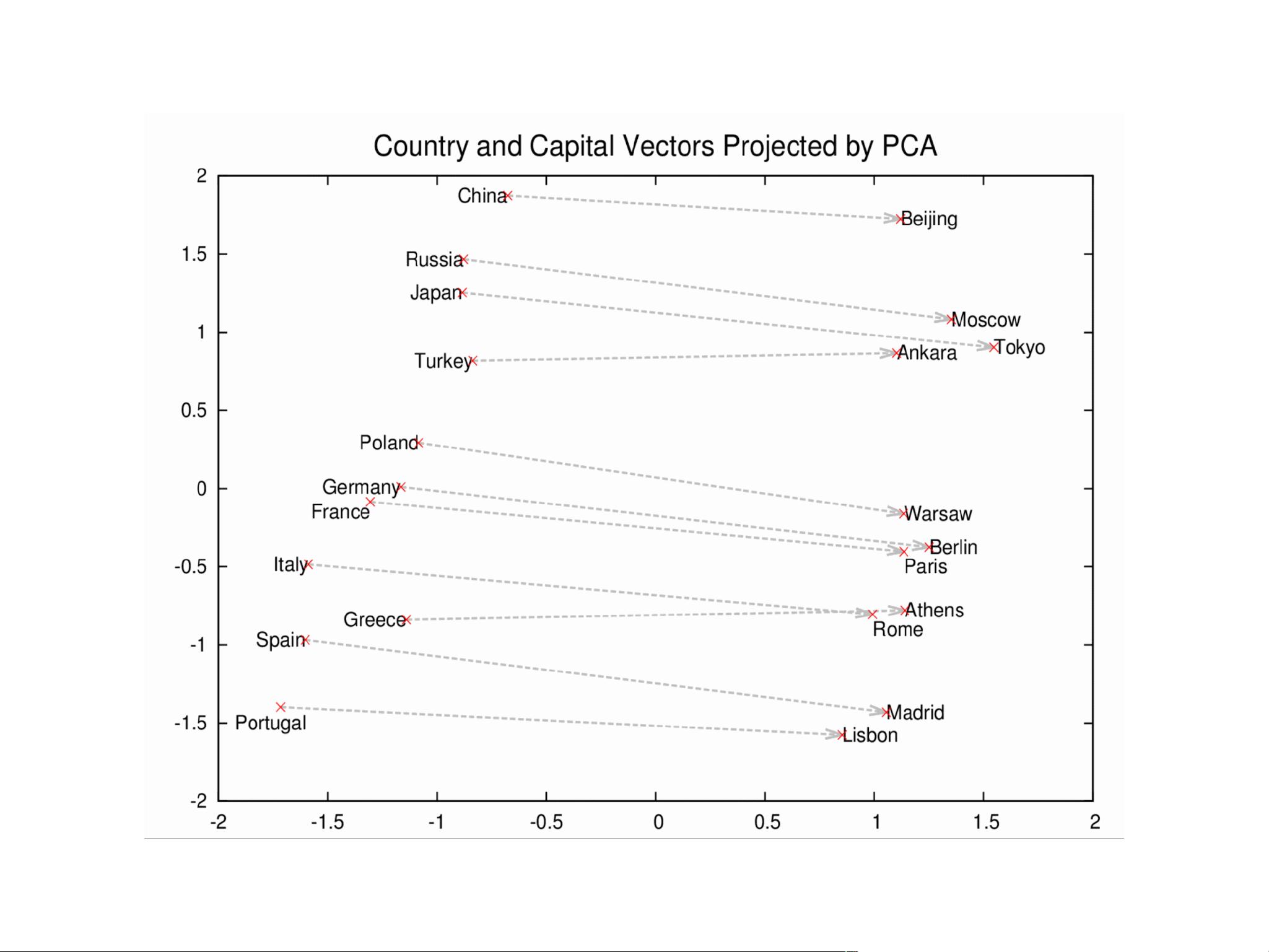
在实际应用中,Word2vec产生的向量能够反映出词汇间的语义相似性,例如,"Sweden" 和 "Denmark" 可能具有相近的向量表示,因为它们在地理和文化上都属于北欧国家;同样,"Harvard" 和 "Yale" 作为著名的大学,其向量也可能会很接近。这种相似性可以用于各种任务,如词汇关联发现、情感分析、机器翻译等。
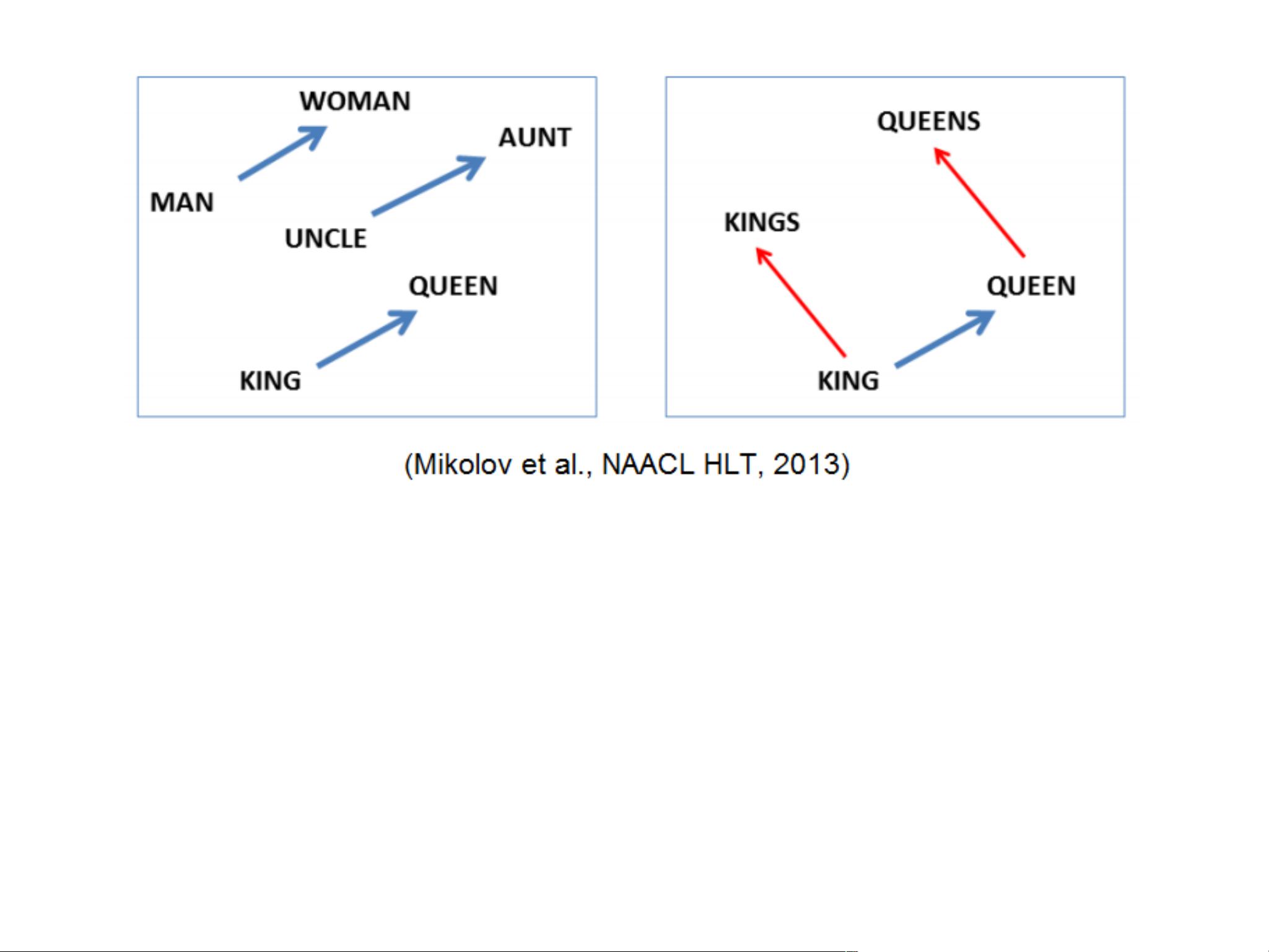
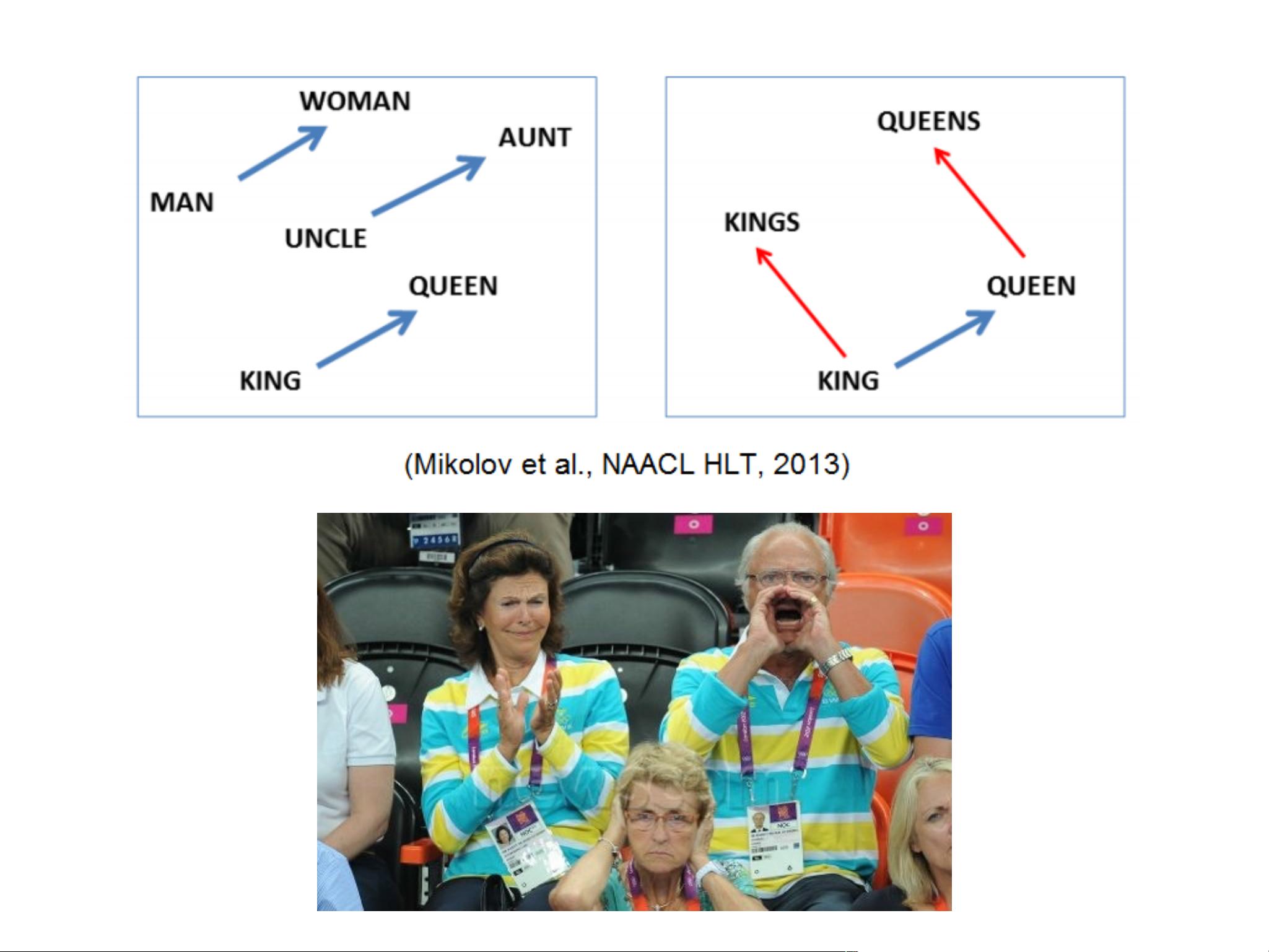
此外,Word2vec的向量表示还能揭示抽象的词汇关系,例如,"king" - "man" + "woman" 往往会指向 "queen" 的向量,这展示了模型如何编码了性别转换的关系。这种能力使得Word2vec在许多NLP任务中表现出色,如问答系统、信息检索、推荐系统等。
在实践中,优化Word2vec模型参数,如窗口大小、学习率、迭代次数以及词汇表大小等,对模型性能有显著影响。同时,预处理步骤,如停用词去除、词干提取和词形还原,也是提升模型效果的关键环节。在大型数据集上,可以使用分布式计算框架如MapReduce进行并行训练,以提高效率。
Word2vec通过学习词汇的上下文关系,生成了具有丰富语义信息的向量表示,成为NLP研究和应用领域的一个基石。其理论与实践的结合,不仅加深了我们对自然语言的理解,也为众多自然语言处理任务提供了强大的工具。
258 浏览量
115 浏览量
2024-12-29 上传
126 浏览量
2024-12-27 上传
148 浏览量
2024-11-09 上传

周建丁
- 粉丝: 1218
- 资源: 150
 我的内容管理
展开
我的内容管理
展开







最新资源
- Windows下Apache+Tomcat+MySQL+jsp+php的服务器整合配置经验总结
- Delphi下用IntraWeb开发WEB程序应用实战
- Jsp+tomcat+mysql for WindowsXP
- microsoft c# 认证题库
- Eigenfaces for Face Detection
- Linux网络文件系统分析(NFS)
- 数据通信基础知识.pdf
- 最佳46款免费软件(同步精译版)
- JAVA语言版数据结构与算法
- PC_MODBUS;PC与PLC.doc
- DWR 入門與應用-林信良
- 关于spring的pdf书
- 学习oracle笔记
- 基于Matlab的遗传算法实现
- 12学会FreeBSD安装笔记
- proteus完整教程(英文版).pdf
