HashMap数据结构与工作原理深度解析
需积分: 34 13 浏览量
更新于2024-09-13
收藏 97KB DOCX 举报
"HashMap是Java编程中的一种重要数据结构,它是数组和链表的结合体,也称为链表散列。HashMap在初始化时会创建一个数组,每个数组元素实际上是一个链表,用于存储键值对。键值对通过键的hashCode()计算存储位置,而值被视为键的附属。HashMap的put()方法主要依赖于键来确定存储位置,不考虑值。计算存储位置的方法是通过hash()函数得到hash码,然后通过indexFor()方法计算出在数组中的索引,索引值总是由hashcode与数组长度减一进行位运算得到。由于HashMap的数组长度总是2的幂,这种设计能确保分布均匀。"
HashMap是Java集合框架中的一种高效容器,它允许以键值对的形式存储数据。在HashMap中,数据存储的核心是数组和链表的组合。数组提供了快速访问的性能,而链表则解决了哈希冲突的问题。当多个键映射到相同的索引位置时,这些键值对会在数组的同一位置形成一个链表。
HashMap的内部实现主要基于`Map.Entry`接口,`Map.Entry`代表了一个键值对,每个`Map.Entry`包含一个键和一个值,并且还持有指向下一个`Map.Entry`的引用,这样就形成了一个链表。当插入新的键值对时,HashMap首先计算键的hashCode,然后通过`hash()`函数将其转换为适合数组索引的值。`hash()`函数通常是基于hashCode()的结果进行一些数学运算,目的是确保具有相同hashCode的对象能够均匀地分布在数组中。
计算索引的过程由`indexFor(int h, int length)`方法完成,它使用位运算`(h & (length - 1))`来确定键值对在数组中的位置。这个操作的巧妙之处在于,由于HashMap的数组长度是2的幂,位运算结果会落在0到length-1之间,有效地将哈希值映射到数组的合法索引上。这使得哈希冲突的概率减小,提高了查找效率。
当两个键的hashCode相同,它们会被放置在同一个数组索引位置的链表中。通过遍历这个链表,HashMap可以找到正确的键值对。由于HashMap不保证元素的顺序,因此在迭代遍历时,元素的顺序可能与插入顺序不同。
在实际使用HashMap时,需要注意其线程安全性。默认情况下,HashMap不是线程安全的,如果需要在多线程环境中使用,可以考虑使用`ConcurrentHashMap`。此外,HashMap对null键和null值的支持也有限制,一个HashMap只能有一个null键,但可以有多个null值。
HashMap通过高效的哈希算法和链表结构实现了快速的存取和解决哈希冲突,是Java开发中广泛使用的数据结构之一。理解其工作原理对于优化代码性能和解决潜在问题至关重要。
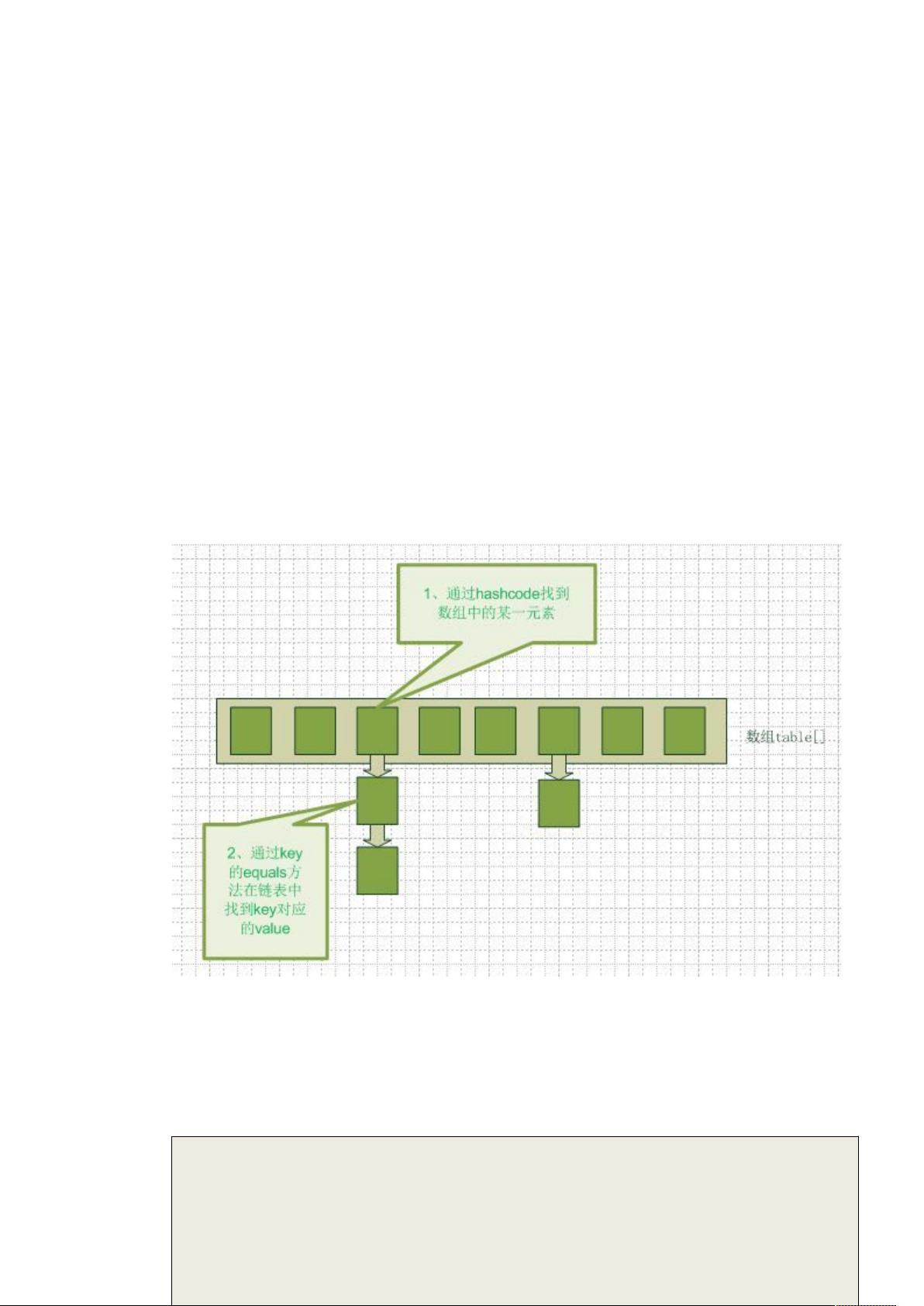
HashMap 的数据结构
要知道 HashMap 是什么,首先要搞清楚它的数据结构,在 java 编程语言中,最基本的结构就是两
种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造
的,HashMap 也不例外。HashMap 实际上是一个数组和链表的结合体(在数据结构中,一般称之
为“链表散列“),请看下图(横排表示数组,纵排表示数组元素【实际上是一个链表】)。
从图中我们可以看到一个 HashMap 就是一个数组结构,当新建一个 HashMap 的时候,就会初始化
一个数组。就像引用类型的数组一样,当我们把 JAVA 对象放入数组之时,并不是真正的把 JAVA 对
象放入数组中,只是把对象的引用放入数组中,每个数组元素都是一个引用变量
HashMap 数组定义
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
//定义 HashMap 底层数组
transient Entry[] table;
//定义数组中存储的元素(key-value 对)
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next; //指向下一个元素的引用
下载后可阅读完整内容,剩余6页未读,立即下载
1180 浏览量
174 浏览量
382 浏览量
520 浏览量
682 浏览量
490 浏览量









