Flink容错机制详解:检查点(Checkpoint)与Exactly-once保证
需积分: 0 86 浏览量
更新于2024-08-05
收藏 1.45MB PDF 举报
"这篇文档主要介绍了Apache Flink的容错机制,特别是检查点(checkpoint)的概念,以及如何通过检查点实现exactly-once语义。文章通过数珠子的类比来解释检查点的工作原理,并给出了一个简单的Flink程序示例来说明检查点在实际应用中的作用。"
在分布式流处理系统Apache Flink中,容错机制是其核心功能之一,以确保系统在面临故障时能够恢复到一致的状态,继续进行准确无误的计算。Flink的exactly-once语义保证了在发生故障时,系统可以重新处理数据并得到与无故障情况下完全一样的结果。检查点是实现这一目标的关键技术。
检查点是Flink系统在特定时间点创建的一份全局一致性快照,它记录了所有任务的状态。类比于数珠子的例子,检查点就像是项链上的皮筋,当珠子(数据)被处理时,皮筋(检查点)也会随之移动,记录当前处理的进度。如果在计数过程中出错,系统可以通过回到最近的皮筋(检查点)处,利用保存的检查点状态重新开始计数,而无需从头开始。
Flink的检查点算法包括以下几个关键步骤:
1. **触发检查点**:定时器或者某些特定事件触发检查点的创建。
2. **状态保存**:在触发检查点时,所有任务暂停处理新的输入,将当前状态保存到持久化存储中,如HDFS或分布式缓存。
3. **传播屏障**:系统在数据流中插入名为checkpoint barrier的特殊数据包,这些barrier会随着数据一起流动,标记出哪些数据是在某个检查点之前处理的,哪些是在之后处理的。
4. **等待确认**:所有任务接收到并处理完所有在barrier之前的记录后,会发送确认消息给JobManager。
5. **完成检查点**:当JobManager收到所有任务的确认消息后,宣布检查点完成,此时系统认为已经有一份完整的状态备份。
在上述的Scala程序示例中,`keyBy`操作将数据流按照键进行分区,而`mapWithState`则是有状态的转换,它维护着每个键的累计计数。当遇到checkpoint barrier时,`mapWithState`会保存当前的计数状态,以便在故障恢复时能够恢复到正确的状态。
检查点的频率和保存策略可以根据应用需求进行配置,以平衡容错能力与系统性能。更高级的特性如增量检查点和异步检查点可以进一步减少对处理性能的影响。
Flink的检查点机制是其强大容错能力的基础,它允许系统在不丢失处理进度的情况下从故障中快速恢复,保证了exactly-once语义的实现,这对于许多业务场景来说至关重要。理解并掌握检查点的工作原理,可以帮助开发者更好地设计和优化Flink应用程序,提高系统的稳定性和可靠性。
保持自信和微笑
Flink之容错机制chekpoint
检查点(checkpoint)
Flink具体如何保证exactly-once呢? 它使用一种被称为"检查点"(checkpoint)的特性,在出现故障
时将系统重置回正确状态。下面通过简单的类比来解释检查点的作用。
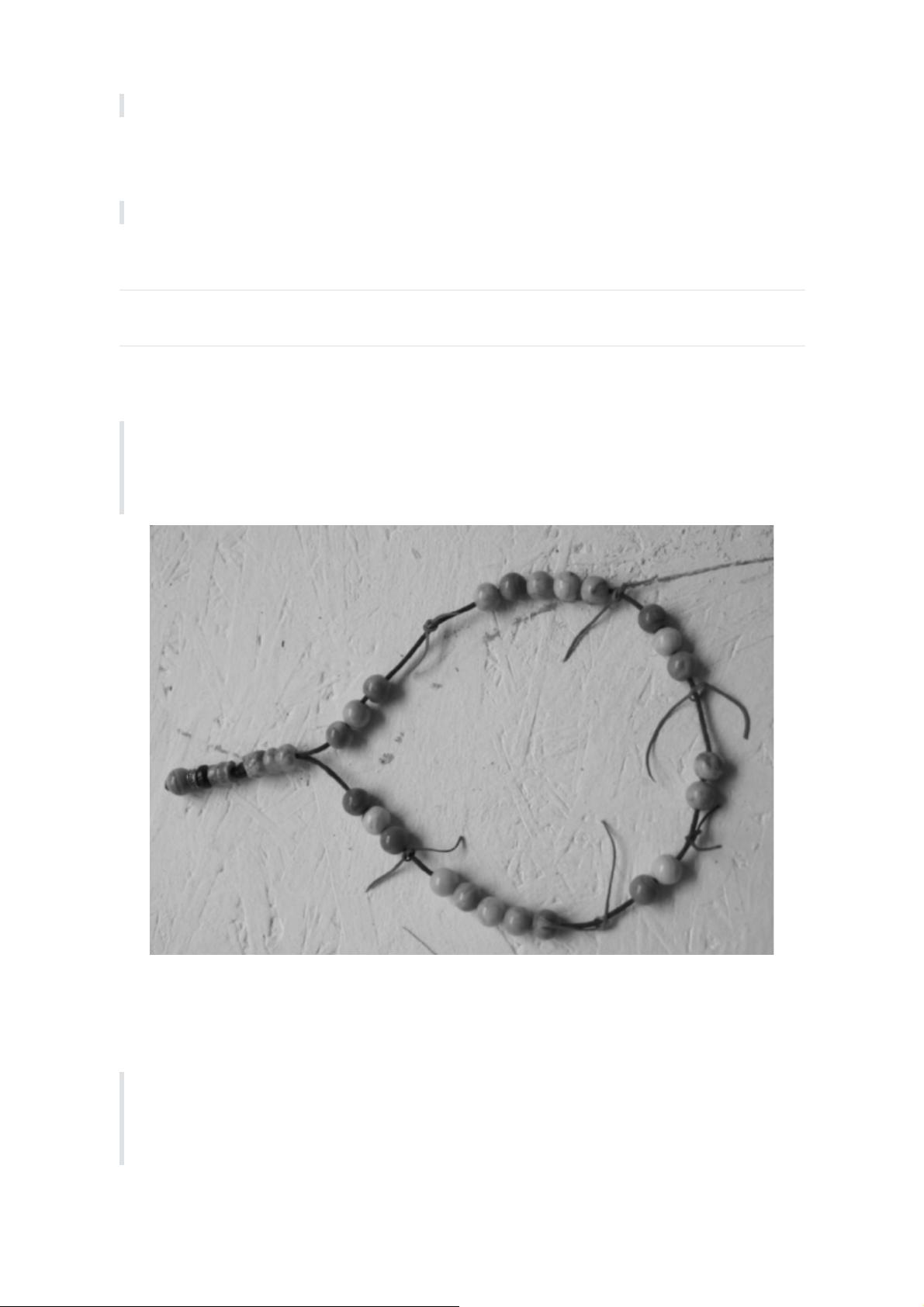
假设你和两位朋友正在数项链上有多少颗珠子,如下图所示。你捏住珠子,边数边拨,每拨过
一颗珠子就给总数加一。你的朋友也这样数他们手中的珠子。当你分神忘记数到哪里时,怎么办
呢? 如果项链上有很多珠子,你显然不想从头再数一遍,尤其是当三人的速度不一样却又试图合作
的时候,更是如此(比如想记录前一分钟三人一共数了多少颗珠子,回想一下一分钟滚动窗口)。
于是,你想了一个更好的办法: 在项链上每隔一段就松松地系上一根有色皮筋,将珠子分隔开; 当珠子
被拨动的时候,皮筋也可以被拨动; 然后,你安排一个助手,让他在你和朋友拨到皮筋时记录总数。用
这种方法,当有人数错时,就不必从头开始数。相反,你向其他人发出错误警示,然后你们都从上一根
皮筋处开始重数,助手则会告诉每个人重数时的起始数值,例如在粉色皮筋处的数值是多少。
Flink检查点的作用就类似于皮筋标记。数珠子这个类比的关键点是: 对于指定的皮筋而言,珠子
的相对位置是确定的; 这让皮筋成为重新计数的参考点。总状态(珠子的总数)在每颗珠子被拨动之
后更新一次,助手则会保存与每根皮筋对应的检查点状态,如当遇到粉色皮筋时一共数了多少珠
子,当遇到橙色皮筋时又是多少。当问题出现时,这种方法使得重新计数变得简单。
检查点算法
下载后可阅读完整内容,剩余9页未读,立即下载
2018-12-07 上传
2024-11-11 上传
2022-08-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

傅融
- 粉丝: 32
- 资源: 333
 我的内容管理
展开
我的内容管理
展开







最新资源
- 解决微服务Fegin调用压缩问题-若依
- 参考资料-中国书法批评史.zip
- 豪华别墅建筑主题网站模板下载
- ParsecTOP:用于TouchDesigner的Parsec纹理流客户端操作员。 使用CPulsPuls运算符进行构建。 基于https
- 算法:C ++中的竞争编程算法
- NewbeeGuide-frontend:学习路线指南(Web 前端篇)
- JSON和API
- tabToMXL
- PyPI 官网下载 | mushroom_rl-1.4.0-py3-none-any.whl
- Natural Reader Text to Speech-crx插件
- AR.zip_matlab例程_matlab_
- 对Vercel的useSWR挂钩具有本机/React导航兼容性。-JavaScript开发
- md-starter:降价参考
- rpds:Rust持久性数据结构
- torch_sparse-0.6.11-cp38-cp38-macosx_10_14_x86_64whl.zip
- ffxiv:用于FF XIV
