深入探讨:Spark集群与Elasticsearch的结合使用
需积分: 5 13 浏览量
更新于2024-04-13
收藏 2.63MB PDF 举报
The document "藏经阁-Spark Cluster with Elasticsearch Inside.pdf" discusses the integration of Spark Cluster with Elasticsearch, a powerful combination that allows for efficient data processing and analysis. The author, Oscar Castañeda-Villagrán from Universidad del Valle de Guatemala, is a researcher with interests in program transformation, programming education research, and online learning to rank.
The integration of Spark Cluster and Elasticsearch offers a powerful solution for big data processing and analytic tasks. Spark Cluster is a distributed computing framework that provides fast data processing capabilities, while Elasticsearch is a distributed search and analytics engine that offers real-time analytics and search capabilities. By combining these two technologies, users can harness the power of both platforms to efficiently process and analyze large volumes of data.
The document provides insights into the implementation and configuration of Spark Cluster with Elasticsearch. It discusses the benefits of using these technologies together, including improved performance, scalability, and fault tolerance. The author also highlights the steps involved in setting up the integration, including installing and configuring Spark Cluster and Elasticsearch, as well as loading and querying data.
Overall, the integration of Spark Cluster with Elasticsearch offers a powerful solution for data processing and analysis tasks. By combining the strengths of both platforms, users can leverage the scalability and performance of Spark Cluster with the real-time analytics and search capabilities of Elasticsearch. This document serves as a valuable resource for those looking to implement this integration and harness the full potential of these technologies for their data processing needs.
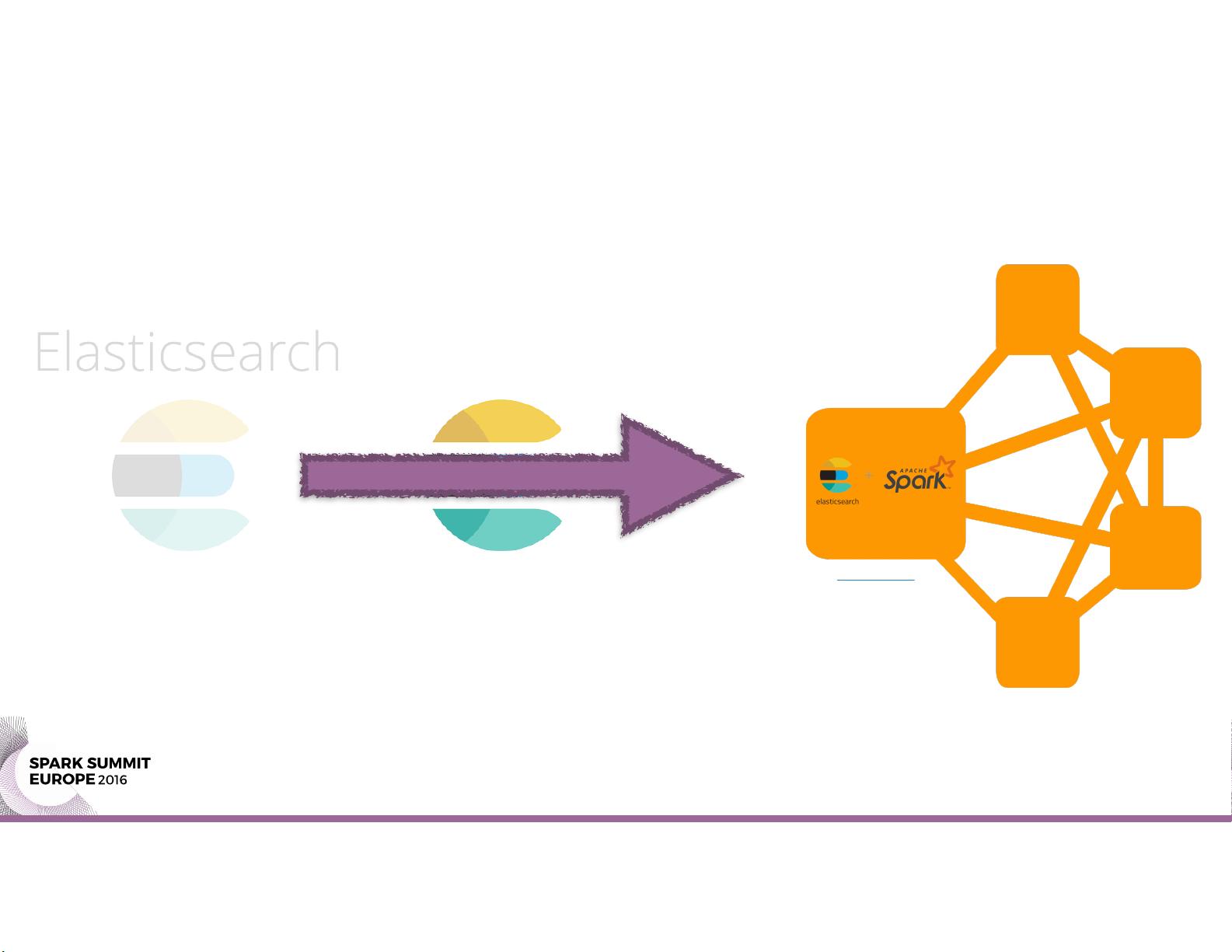
Spark cluster with Elasticsearch
http://bit.ly/2em6RUK
下载后可阅读完整内容,剩余27页未读,立即下载
2023-08-30 上传
2023-08-30 上传
2023-08-30 上传
2023-08-26 上传
2023-08-28 上传
2023-08-30 上传
2023-09-04 上传

weixin_40191861_zj
- 粉丝: 92
 我的内容管理
展开
我的内容管理
展开








最新资源
- 简易XP登录界面定制工具发布
- 掌握Create React App:开发与部署个人网站指南
- JAVA员工信息管理系统源码及数据库下载
- 掌握sysbench 0.5:性能测试工具的使用与MySQL测试方案
- 嵌入式Linux实验代码详解:驱动与硬件交互
- JSP+SQL+2000网上书店系统实现与毕业设计指南
- Windows 7 WiFi热点创建与配置指南
- 新一代Socket通讯测试工具的使用与介绍
- UPX源码在Win32平台的C++实现与优化
- Ubuntu机器自动化安装脚本指南
- 超级导航条的实现与应用
- 深入探索自定义ActionBar及其功能按钮
- 防火墙视觉化工具Gressgraph:探索与交流平台
- 小巧实用的Web开发文本编辑器
- IE工具v1.00:恢复经典6.0界面的实用工具
- VC MFC实例解析:SID与MDI全屏显示技术
