亚马逊全网爬虫:抓取Top100类目排名,稳定高效
需积分: 0 72 浏览量
更新于2024-06-30
收藏 420KB DOCX 举报
亚马逊全网爬虫文档详细介绍了如何开发一个稳定、高效的爬虫系统,以满足智干电子商务有限公司在境外电商运营中的数据抓取需求。主要目标是抓取亚马逊美国站各级类目的Top100商品排名,并将这些信息存储在数据库中,以便于后续的数据分析和业务人员使用。以下是从文档中提炼出的关键知识点:
1. **需求分析**:
- 爬虫功能:主要针对亚马逊美国站,抓取商品排名数据,包括最小类目Top100。
- 稳定性与效率:要求爬虫设计时考虑稳定性,避免对网站造成过大的负担,同时确保爬取速度适中,不影响正常用户浏览体验。
- 技术栈:初始采用Python进行开发,后续计划优化至Golang或Java。
- 扩展性:除了亚马逊,还将开发京东等其他电商平台的爬虫。
2. **软件设计**:
- **类目管理**:需要设计合理的类目结构,确保爬虫能准确定位和抓取指定类目的数据。
- **存储方案**:选择MySQL作为数据库,强调数据存储的性能和安全性。
- **反爬策略**:面对可能的反爬机制,需要考虑使用代理IP轮换、User-Agent多样化等技术手段来提高匿名性和稳定性。
- **分布式爬虫**:为了提高爬取效率,将针对分类目数量众多的情况,设计分布式爬虫系统,支持并行抓取。
3. **软件使用与配置**:
- **配置文件**:详细说明了全局配置和日志配置的重要性,确保爬虫运行的稳定性和可维护性。
- **数据库操作**:包括创建smart_base和smart_item等基础数据库表,用于存储抓取到的商品数据。
- **爬虫工具**:提供了多种辅助工具,如proxyfiletool.py、proxymysqltool.py等,用于处理IP管理和数据库操作。
4. **服务器规划与管理**:
- 确定了服务器的规划,涉及服务器的基本命令、行为准则以及维护工作,确保系统的稳定运行。
- 数据存储架构强调了外部文件的管理和组织方式。
5. **开发流程**:
- 分阶段开发,首先抓取亚马逊美国站商品分类下的排名数据,然后逐步优化工具和技术,扩展到其他平台和数据分析。
6. **合规与准则**:
- 提供了服务器行为准则,包括基本命令的使用、代码规范以及维护计划,以遵循网络安全和法律法规。
总结来说,这份文档围绕亚马逊全网爬虫的开发,涵盖了需求分析、系统设计、配置管理、数据库操作、工具开发、服务器规划以及行为准则等多个方面,为公司构建了一套完整且高效的电商数据抓取和分析解决方案。
4
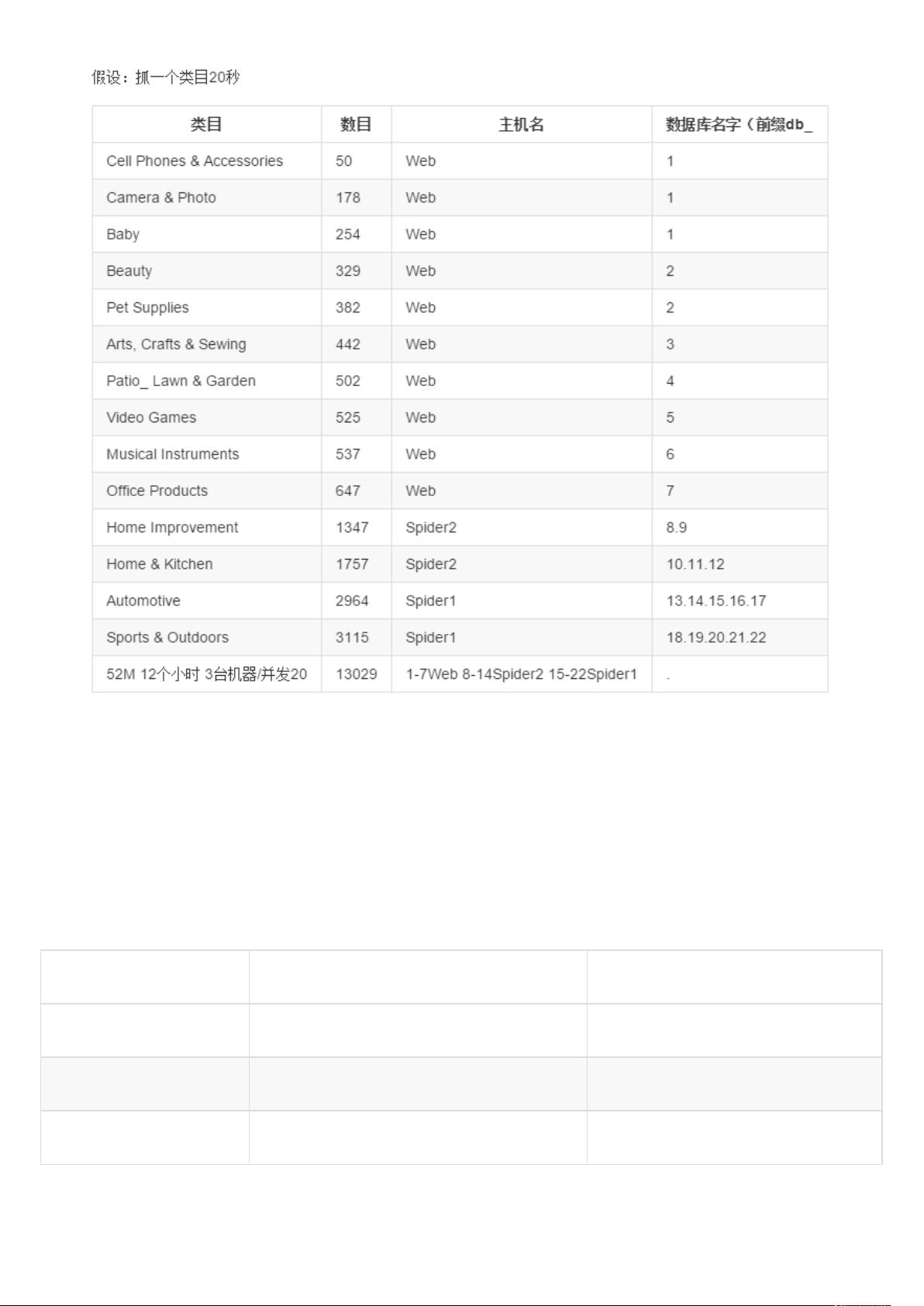
2. 存储(空间)
总共 18312 个最小类目,每个类目 100 件商品,根据抓取的存储来看,每个类目一天占用 4K 的数据库存储空间,
本地文件占用 92M,计算所得,一天抓取的数据超过 180 万,占用数据库空间 73M,占用本地存储空间 1.68T(本
地文件要定时清理)
计算所得:
时长
数据库数据量
本地数据量
1 天
73M
1.68T
一个月
2.19G
50.4T
一年
26.645G
613.2T
剩余34页未读,继续阅读
2022-08-03 上传
2024-01-20 上传
2024-03-08 上传
2024-05-12 上传
2023-07-29 上传
2023-05-30 上传









