




NLP预训练模型解析:Bert与上下文语义
版权申诉
85 浏览量
更新于2024-06-20
收藏 7.24MB PPTX 举报
"本次介绍的是自然语言处理领域的预训练模型,特别是以Bert及其相关模型为核心的深度学习技术。这些模型通过在大规模语料库上进行训练,以获取通用的语义知识,从而能在各种自然语言任务中表现出色。"
在自然语言处理(NLP)中,预训练模型如Bert及其衍生物已经成为处理文本的关键工具。这些模型在海量无标注的文本数据上进行训练,学习语言的基本规律,以创建能够捕捉词汇和句子含义的向量表示。例如,word2vec是早期的一种词嵌入模型,它将每个词映射到一个固定向量,但无法体现一词多义的现象。而Bert等模型则引入了更先进的思想来克服这个问题。
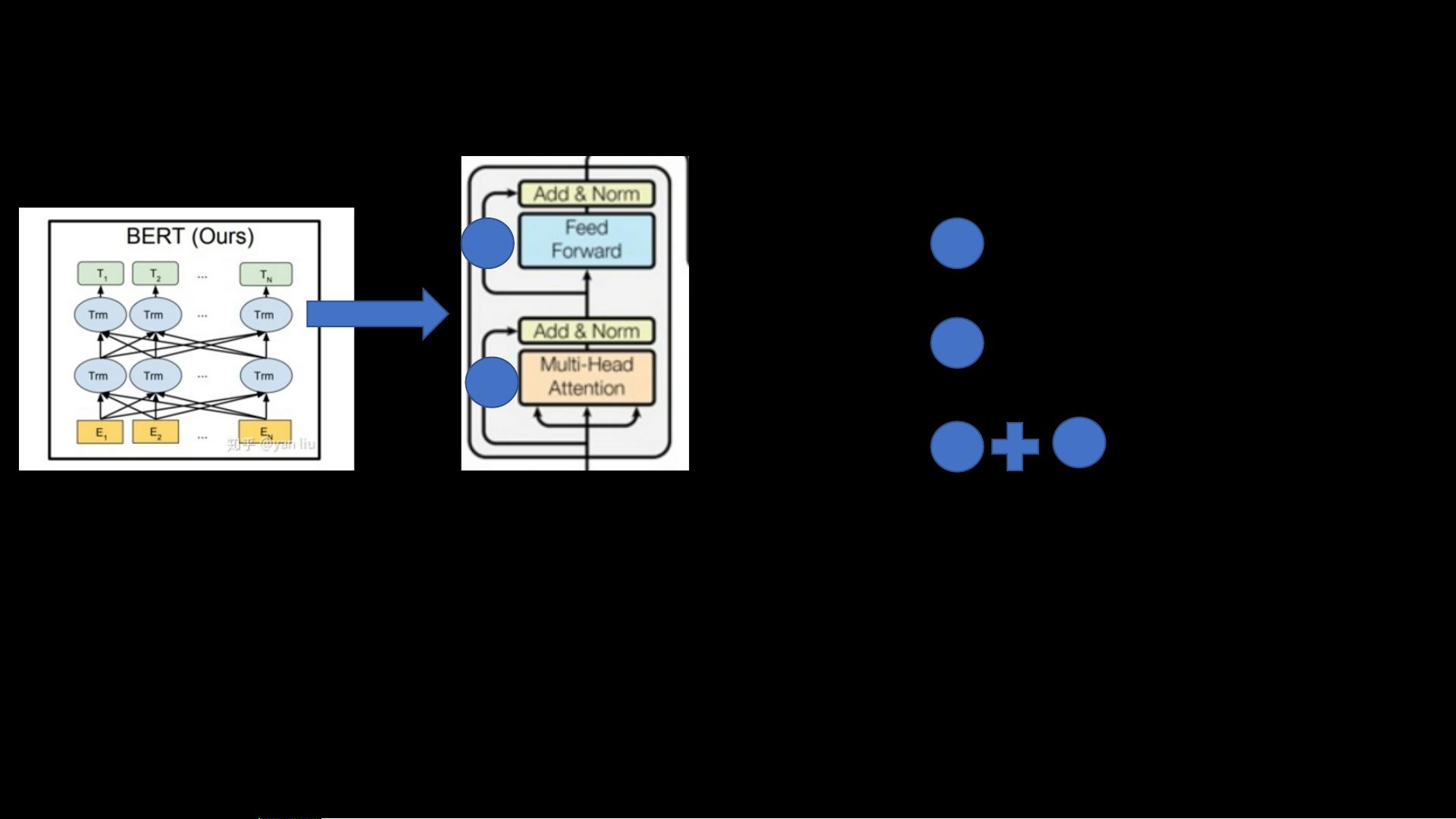
Bert全称为Bidirectional Encoder Representations from Transformers,它的创新之处在于利用Transformer架构,尤其是其多头注意力机制,捕捉上下文信息。在Bert中,每个词的向量不仅与自身相关,还受到前后文的影响,这使得模型能够理解词汇的多种含义。为了实现这一目标,Bert在训练时采用了两种任务:Masked Language Model (MLM) 和 Next Sentence Prediction (NSP)。
MLM类似于完形填空,模型会随机遮蔽一些输入序列中的单词,然后尝试预测这些被遮蔽的单词。这种方法迫使模型依赖上下文信息来恢复被遮蔽的词,从而学习到词汇的语境依赖性。而NSP则是预测两个连续句子是否为实际的相邻句子,帮助模型学习句子级别的连贯性。
在具体应用时,Bert可以先对输入文本进行处理,添加特殊标记如[CLS],用于捕获整个句子的特征。多层Transformer网络处理后,每个位置的词都会得到一组向量,这些向量包含了丰富的上下文信息。在下游任务(如文本分类、问答等)中,可以利用这些向量作为基础,构建附加的小模型进行微调。
除了Bert,还有其他模型如ELMo,它是一个基于自回归模型的预训练方法,每个词的向量也会根据上下文动态变化。而ALBERT作为Bert的一个轻量化版本,通过减少模型参数量,实现了更高的效率和性能。
这些预训练模型通过深度学习技术,极大地推动了NLP领域的发展,使得机器能够更好地理解和生成自然语言,为聊天机器人、机器翻译、情感分析等应用提供了强大的支持。通过不断的研究和改进,预训练模型将继续为理解和生成人类语言提供更高效、更准确的解决方案。


928 浏览量
2024-03-24 上传
2023-10-12 上传
352 浏览量
767 浏览量

地理探险家
- 粉丝: 1316
 我的内容管理
展开
我的内容管理
展开








最新资源
- C语言深度解剖:嵌入式面试必知要点
- MFC模拟实现进程间自定义消息通信
- ReactOutsideClick2: 处理React中外部点击事件的方法
- 点击速度测试工具的开发与实践
- 深入探究Android百度地图API源码实现
- C#语言下的skyline二次开发实践教程
- ADS2008安装破解完全指南
- 全面收集UML教程与资源,让你学得无坑
- DeepSpot服务:利用机器学习优化AWS Spot市场深度学习作业
- Jackson 2.4压缩包内容与使用方法
- 掌握Firefox XPI文件结构与开发工具
- SQLtools安全特供版发布:正月初五免杀版本
- Java增强for循环及其在1.5版本后的迭代应用
- 深入探究Firefox XPI包的内部结构
- 屏蔽任务栏右键操作的实现方法
- 自动创建Google SiteMap的程序工具






















