一步步搭建:16.04虚拟机安装+Hadoop&Spark配置教程
需积分: 47 20 浏览量
更新于2024-07-18
1
收藏 4.85MB DOCX 举报
本篇文章详细记录了在虚拟机环境下,通过VMware安装Ubuntu 16.04操作系统,并进一步配置Hadoop和Spark平台的过程。首先,文章提供了VMware的安装教程,使用的是VMware Workstation的激活码。然后,作者推荐了下载Ubuntu 16.04的桌面版ISO镜像,以及Anaconda科学计算平台和PyCharm Python开发环境的安装包。
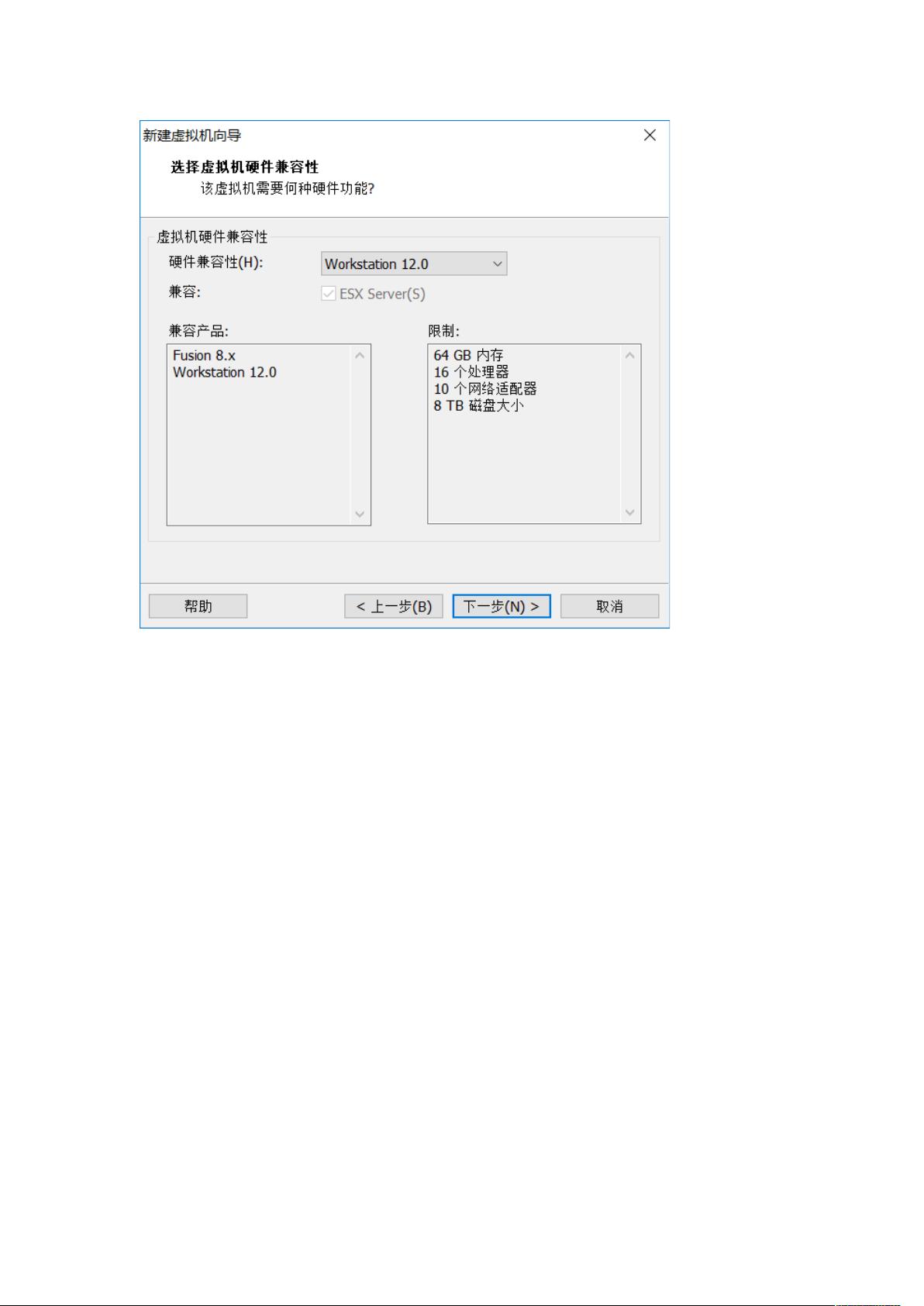
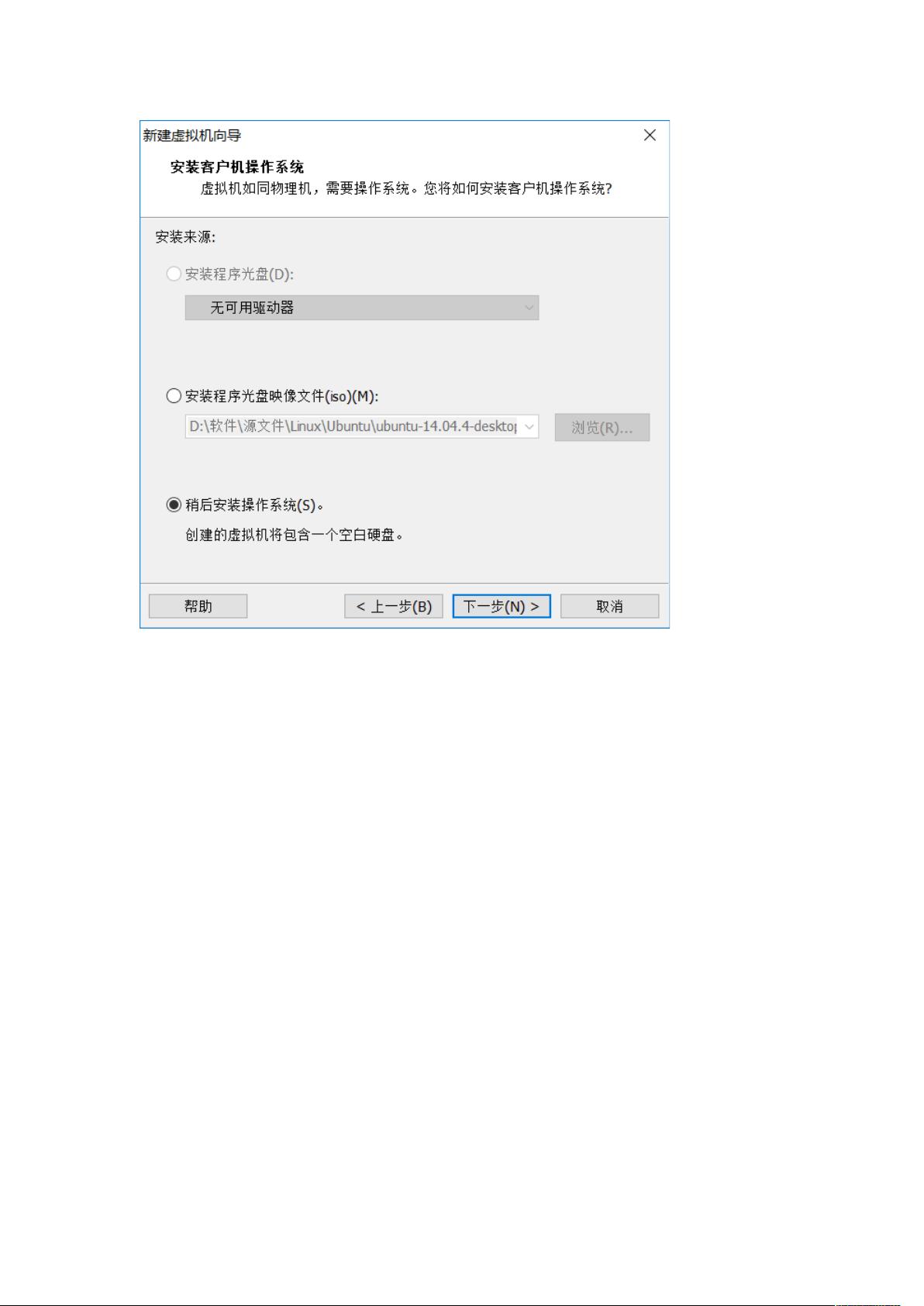
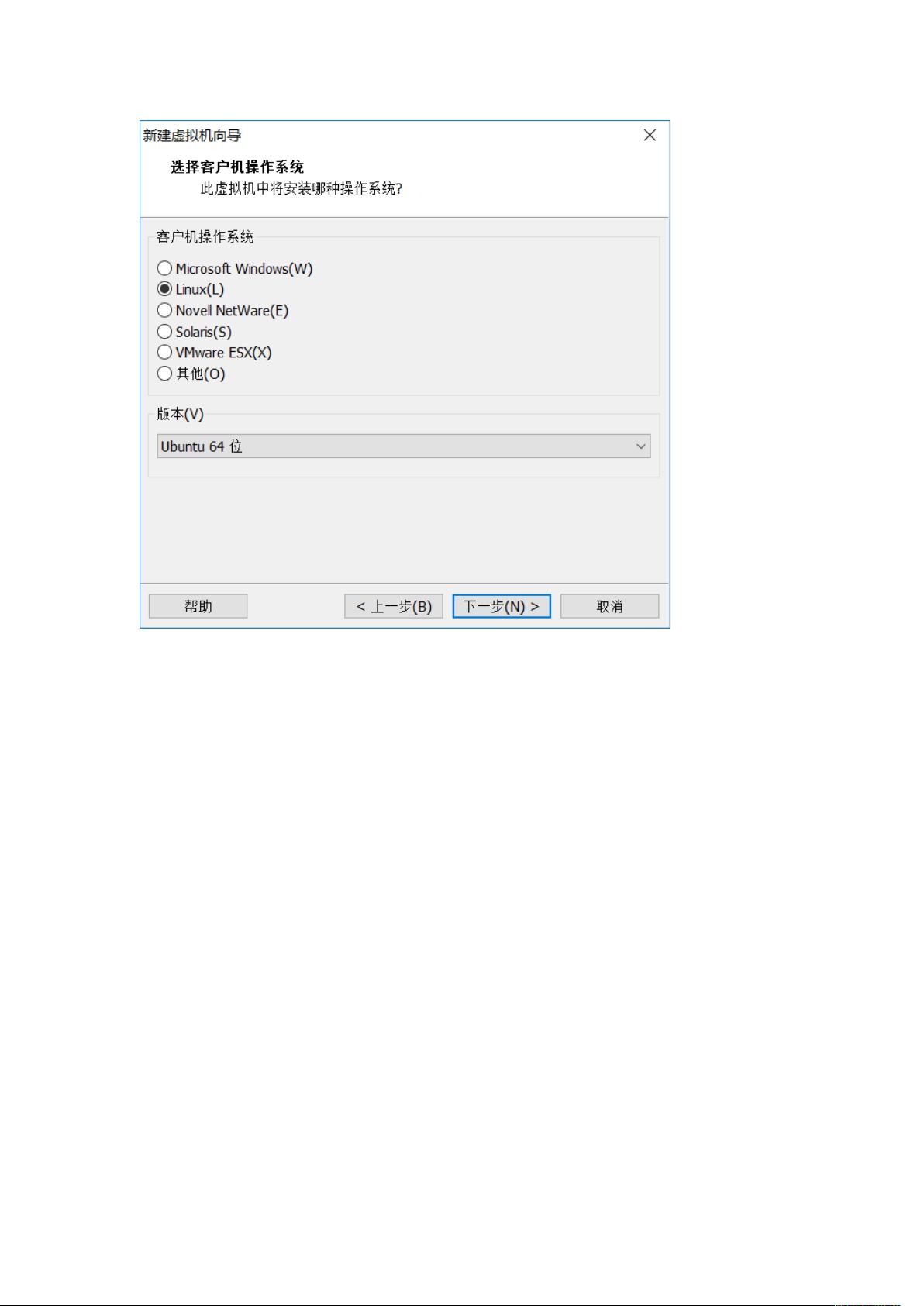
在虚拟机的创建过程中,作者按照步骤安装Ubuntu 16.04,参考了百度经验上的入门教程,确保系统的基础配置。增强工具方面,提到了TensorFlow的安装,虽然没有提供直接的链接,但暗示是基于Ubuntu环境下的安装指南,可能涉及到了必要的依赖库和配置。
对于Hadoop的安装,文章引用了厦大数据库实验室的博客,介绍了Hadoop 2.6.0在Ubuntu 14.04上的单机或伪分布式配置方法。这包括设置Hadoop用户(hadoop)、分配权限、更新和安装必要的软件(如Vim和OpenSSH服务器),并通过SSH进行安全连接。最后,文章指导如何生成SSH密钥对,以方便后续的远程登录。
Spark的准备工作部分,提到使用`sudo`命令更新包列表,安装Vim和OpenSSH服务,然后通过SSH连接到本地主机并执行一些基本操作,如创建SSH密钥对。这部分强调了对Spark环境的初步配置,但并未详细列出Spark的具体安装步骤,可能假设读者已经具备了基本的Spark环境配置知识。
这篇文章为想要在虚拟机上搭建Hadoop和Spark环境的读者提供了一个实用且详细的指南,涵盖了从安装基础环境到配置关键组件的整个流程。对于IT专业人员或者希望学习大数据处理技术的人来说,这是一个宝贵的参考资源。
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-05-25 上传
2016-10-25 上传
2024-07-22 上传
2022-09-18 上传
2021-06-15 上传
2024-03-20 上传

csdn使用者
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
