K近邻算法详解:监督分类与决策规则
版权申诉
28 浏览量
更新于2024-06-27
收藏 2.18MB PPTX 举报
机器学习__K近邻.pptx 文件主要介绍了K近邻(K-Nearest Neighbors, KNN)算法,这是一种有监督的学习方法,主要用于分类和回归任务。KNN算法的基本原理源自“物以类聚,人以群分”的概念,即通过分析一个未知样本与其训练集中最相似样本的类标签来做出预测。
KNN分类器的核心要素包括:
1. **有标签的样本集**:这是算法的基础,包含已知类别标签的数据点,用于在新样本上进行预测。
2. **距离度量**:如Minkowski距离(默认为p=2的欧氏距离)、曼哈顿距离等,用于计算样本间的相似性或差异。
3. **k值(k-Nearest Neighbors)**:指定的最近邻数量,是算法的关键参数。通常较小的k值更倾向于局部决定,而较大的k值会更加平滑,减少噪声影响。
KNN分类的过程如下:
- 对于未知样本,计算它与所有训练样本之间的距离。
- 确定k个最近的邻居,即距离最近的k个训练样本。
- 依据这k个邻居的类别,应用决策规则(多数投票制)来确定未知样本的类别。如果邻居中有多个类别,就选择出现次数最多的类别作为预测结果。
标准化处理(如规范化数据)也是KNN分类器的一个关键步骤,有助于确保不同特征间具有可比性。Python中的sklearn库提供了`KNeighborsClassifier`类,用于实现KNN算法,其中包含了许多可调整的参数,如`n_neighbors`(默认为5)、`weights`(可以为'uniform'或'distance')、`algorithm`(如'ball_tree'、'kd_tree'等)等,以及支持多线程处理的选项。
在具体应用中,K近邻算法被广泛应用于鸢尾花数据集(如山鸢尾、变色鸢尾和维吉尼亚鸢尾)等,以展示其分类能力。给定一个待预测样本时,只需创建一个`KNeighborsClassifier`实例,并调用其方法对新样本进行预测。例如:
```python
from sklearn.neighbors import KNeighborsClassifier
# 创建KNN分类器,k值为5
knn = KNeighborsClassifier(n_neighbors=5)
# 使用训练数据拟合模型
knn.fit(X_train, y_train)
# 预测新样本
prediction = knn.predict(X_test)
```
KNN算法虽然简单直观,但在处理大规模数据集时可能效率较低,因为它需要存储整个训练集。此外,k值的选择需要经验和交叉验证来优化,以找到最佳的性能平衡。然而,对于小型问题或者简单的分类任务,KNN仍是一种强大的工具。
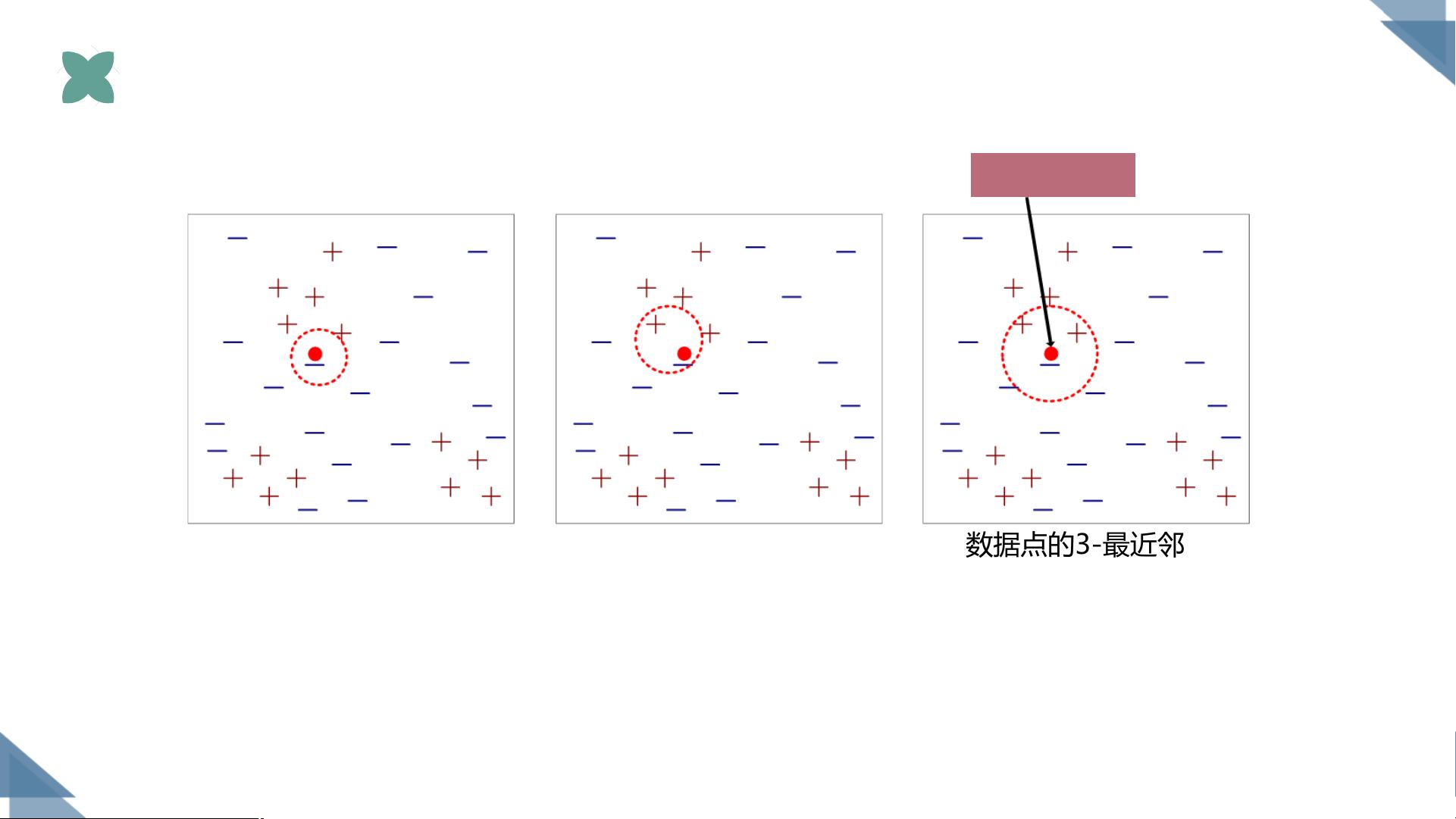
K近邻分类器
未知样本
数据点的3-最近邻
数据点的2-最近邻
数据点的1-最近邻
数据点根据其近邻的类标记号进行分类。如果数据点的近邻中含有多
个类标号,则将该数据点指派到其最近邻的多数类。
剩余14页未读,继续阅读
5871 浏览量
103 浏览量
2023-01-14 上传
2023-01-14 上传
2023-01-14 上传
2021-12-18 上传
154 浏览量

知识世界
- 粉丝: 375
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







