FedX: 无监督联邦学习中的跨知识蒸馏提升
65 浏览量
更新于2024-06-19
收藏 1.28MB PDF 举报
联邦学习(Federated Learning, FL) 是一种新兴的分布式机器学习范式,旨在保护数据隐私的同时实现模型的联合训练。本文主要关注的是"联邦学习中的交叉知识蒸馏方法",由Sungwon Han等人提出,发表于2022年的论文。该研究聚焦于无监督表示学习,这是一种在没有标签数据的情况下训练模型以学习数据内在结构和表示的技术。
FedX 是这个领域的创新框架,其核心特点是采用双边知识蒸馏和无偏表示学习。在传统的联邦学习中,通常依赖于监督信号,而在FedX中,模型通过对比学习机制进行自我指导,实现了在不泄露用户数据具体特性的前提下,促进各客户端设备之间模型的交流和提升。这种无监督的训练方式使得FedX能够在保护数据隐私的同时,增强模型的泛化能力和适应性。
模型的工作流程包括两个关键步骤:首先,通过局部知识提取,模型在每个客户端上逐步学习并扩展不变特征,这是通过增量学习实现的,保证了模型对局部数据的适应性;其次,通过全局知识提取,模型在不分享原始数据的情况下,利用跨客户端的模型间交互,进一步提炼和整合知识,强化整体的表示能力。这种设计使得FedX不仅适用于监督任务,还能作为联邦环境中现有无监督算法的补充模块。
实验结果显示,FedX相较于传统方法在性能上有显著提升,尤其是在数据隐私保护方面表现出色。文章关键词包括无监督表示学习、自监督学习、联邦学习、知识蒸馏以及数据隐私,这些都是FedX模型设计和评估的重要组成部分。
这篇论文提供了一种新颖的联邦学习解决方案,强调了在数据隐私保护和性能优化之间的平衡,并为未来的联邦学习研究开辟了新的可能性。
+v:mala2255获取更多论
文
C
−
−
BB
FedX:交叉知识蒸馏的无监督联邦学习5
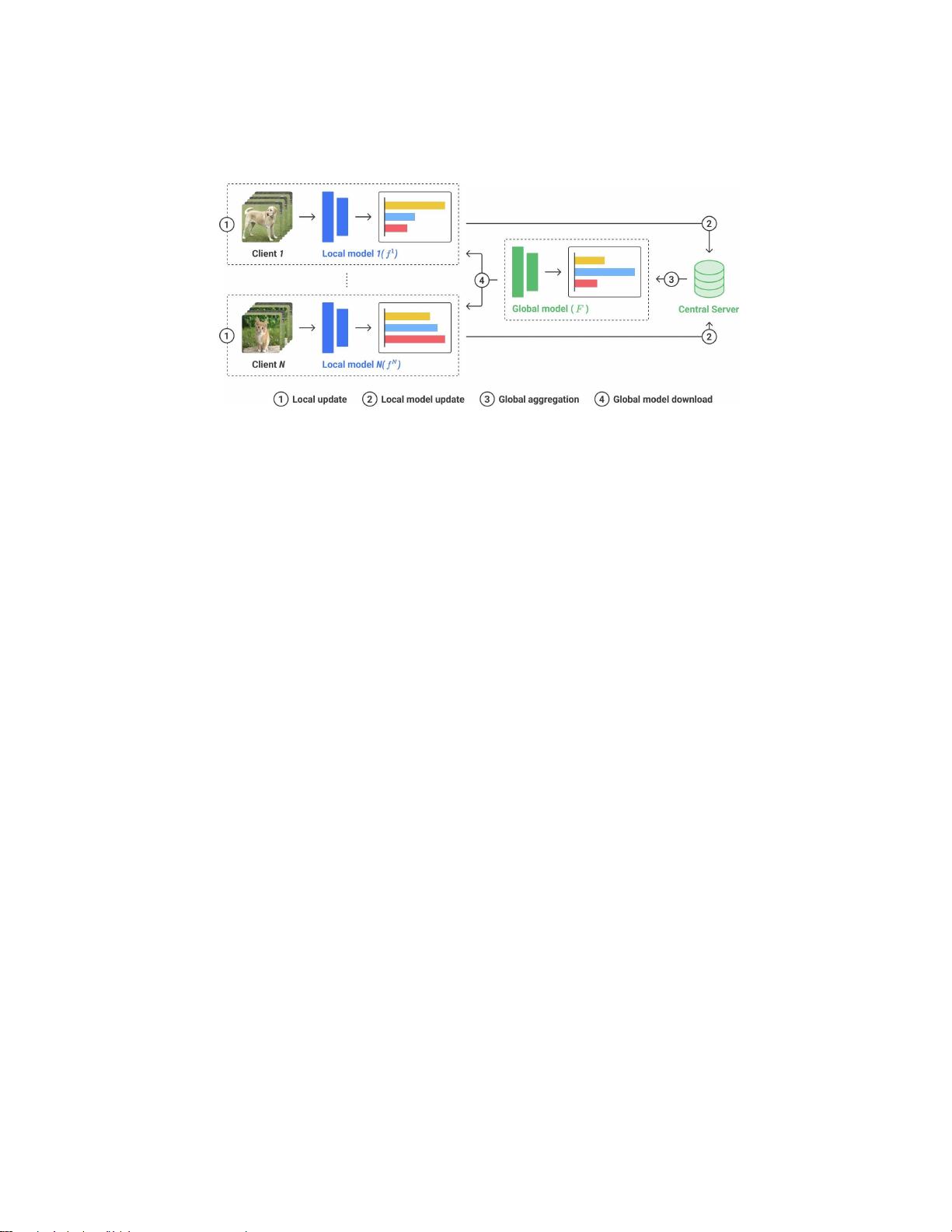
图2:FedAvg框架[ 23 ]的图示,它被用作
许多
联邦系统的基础结构。
FedX
改进
了本地校准
过程
○
1
。
我们使用FedAvg [23]作为底层结构,并描述了数据流
图
二
、
在
每个
通信回合
中
运行
的四
个过程
:
过程
○
1
对当地
更新是当每个本地客户端用其数据Dm训练模型
f
m
时
对于
E
本地
ep
oc
hs;当
客户
端
共享
经过
训练
与
服务器进行对话;
过程
○
3
对 全球 聚集 时发生
中央服务器对接收到的模型权重进行平均
全局模型F
;
程序
○
4
在全局模型下载中,
局部模型与下载的全局模型(即,平均重量)。这些进程运行
R
通信
轮。
F
edX
修改
了
程序
○
1
通过重新设计损失目标,
地方和全球范围的知识。以下部分介绍我们的无监督联邦学习模型的
设计组件。
3.2
地方知识蒸馏
第一个重要的变化发生在本地客户端,他们的目标是
从本地
数据中学习
有意义的表示。
让
我们
定义
一
个
数据
对;
x
i
和
x
i
是同一数据实例的两个
增强视图。局部
对比损失
L
local
通过最大化
xi
和
x
i
之间的一致性
,同时
最小化
来自
不同
实例
的视图的一致性来学习语义表示
(即
,阴性
样品)。我们展示
了两种无监督表示学习方法的对比损失作为香草基线。
Simplified [3]利用基于InfoNCE损失的对比目标[26]。提供一批 在
大小
为
N
及其扩充版本为
N的情况下
,每个锚点具有单个正样本,
并将所有其他(2
N
2)个数据点视为负样本。以下是这种(
2n1
)
路实例辨别损失的定义,其中
τ
是用于控制熵
∗
剩余20页未读,继续阅读
2024-01-24 上传
2021-07-20 上传
2024-07-05 上传
2024-10-09 上传
2023-07-29 上传
2023-08-13 上传
2023-08-05 上传
2023-06-13 上传
2023-06-09 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
