Kettle连接Hadoop配置指南
"这份文档主要介绍了如何使用Kettle连接Hadoop,包括软件版本、Windows和Linux系统的操作步骤,以及配置Hadoop的相关参数。"
在大数据处理领域,Kettle(也称为Pentaho Data Integration,简称PDI)是一款强大的ETL工具,能够方便地从各种数据源抽取、转换和加载数据。本教程重点讲解了如何配置Kettle以连接到Hadoop集群,特别是CDH5.5版本。
首先,确保你的系统已经安装了Java环境,这是运行Kettle的基础。对于不同操作系统,如Windows和Linux,连接Hadoop的步骤略有差异。
对于Windows系统,按照以下步骤操作:
1. 下载Kettle 6.1 STABLE版本,可以从提供的社区链接获取。
2. 解压缩下载的文件,进入`data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\cdh55`目录。
3. 使用文本编辑器(推荐Notepad++)打开`config`文件,添加`authentication.superuser.provider=NO_AUTH`行并保存。
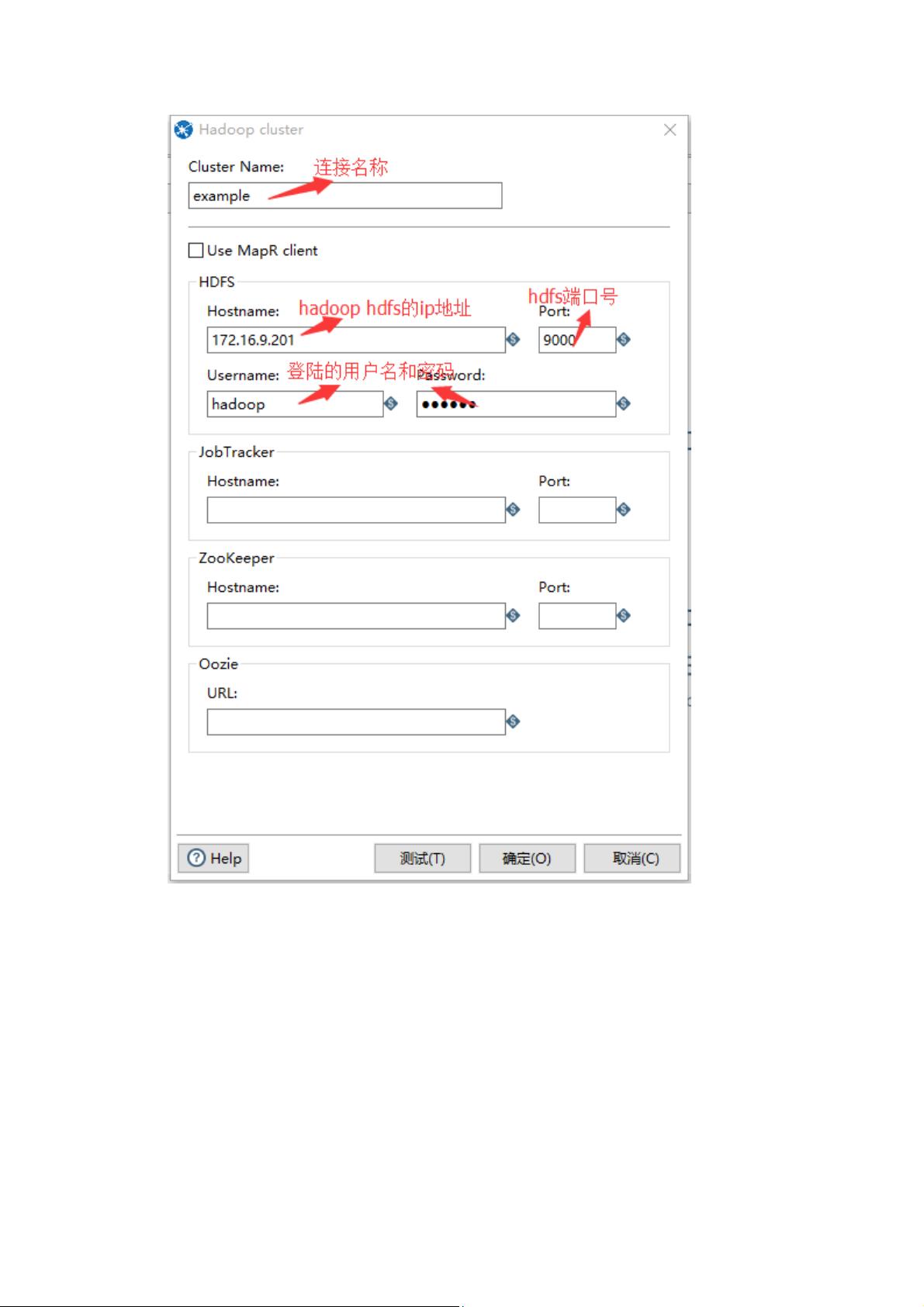
4. 编辑`core-site.xml`文件,增加`hadoop.tmp.dir`和`fs.default.name`属性,其中`fs.default.name`应设置为Hadoop HDFS的路径(例如:`hdfs://172.16.9.201:9000`)。
对于Linux系统,操作步骤通常与Windows类似,但可能需要通过命令行进行文件编辑和配置。具体步骤如下:
1. 安装Java环境,确保系统可以识别`java`命令。
2. 解压缩Kettle,然后在相应的目录下进行配置。
3. 使用文本编辑器(如`vi`或`nano`)编辑`config`文件,添加相同的配置项。
4. 对于`core-site.xml`和可能不存在的`hdfs-core.xml`,同样进行编辑或新建,并配置对应的Hadoop参数。
在配置Hadoop参数时,`core-site.xml`中的`hadoop.tmp.dir`设定临时目录,而`fs.default.name`指定HDFS的默认名称节点。此外,`hdfs-core.xml`中的`dfs.replication`参数用于设置HDFS副本数量,这里设置为2,以保证数据冗余和容错性。
完成上述步骤后,Kettle应该能成功连接到Hadoop集群,允许你在Kettle的工作流中执行对Hadoop的数据操作,如读取、写入HDFS文件,或者利用Hadoop MapReduce进行更复杂的转换和处理。
请注意,实际操作时需根据你的Hadoop集群配置和Kettle版本进行相应调整。如果遇到问题,可以通过搜索引擎查询解决方案或参考官方文档。
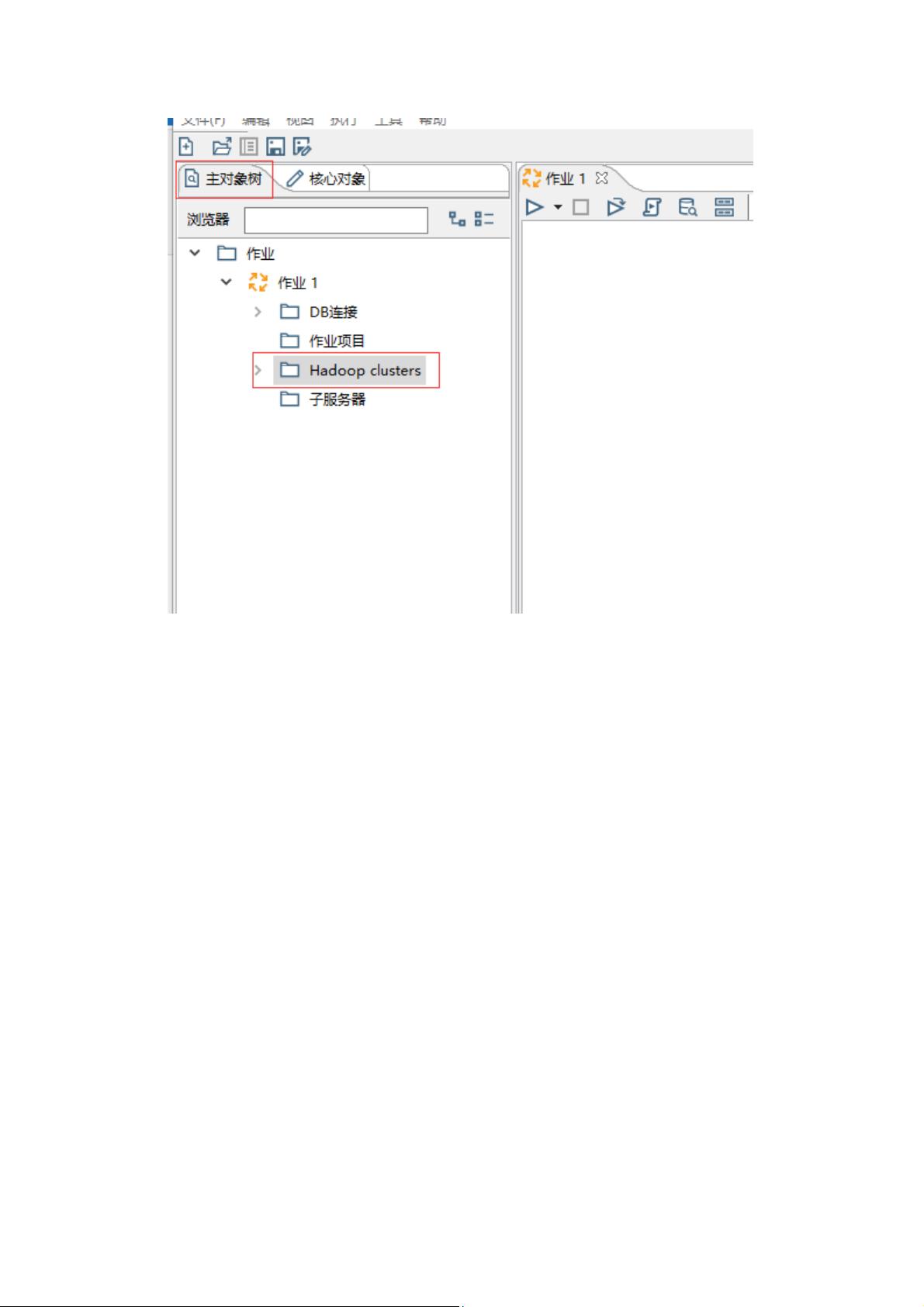
7
9. 填写连接信息
剩余42页未读,继续阅读
2015-05-26 上传
2023-05-11 上传
2023-11-29 上传
2023-07-25 上传
2023-07-22 上传
2023-06-02 上传
2023-08-12 上传
2024-04-10 上传

寒沧
- 粉丝: 270
- 资源: 161
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
