揭秘HDFS:低成本大容量分布式文件系统详解
100 浏览量
更新于2024-08-28
收藏 1.08MB PDF 举报
本文将深入探讨分布式文件系统Hadoop Distributed File System (HDFS),它是Hadoop框架的核心组成部分。HDFS旨在利用廉价硬件实现高度容错性和大文件处理能力,适用于大规模数据集的存储和访问。
首先,分布式文件系统的基础是计算机集群,由众多节点组成,这些节点主要分为两类:主节点(NameNode)和从节点(DataNode)。NameNode是系统的核心,负责管理全局文件系统的命名空间,记录文件系统的目录结构和块分配信息,确保数据的一致性。另一方面,DataNode负责实际的数据存储,它们接收来自NameNode的文件块复制指令,并存储和检索数据。
HDFS的特点包括:
1. **兼容廉价硬件**:HDFS设计初衷是为了在经济高效的硬件上运行,减少硬件成本,特别适合大规模数据处理场景。
2. **流式读写**:HDFS强调数据的连续读取和写入,而不是随机访问,这在处理大量一次性输入输出操作时效率极高。
3. **大数据集处理**:HDFS针对大文件设计,通过将文件划分为固定大小的块(默认64MB),能够轻松处理超出单个节点容量的文件。
4. **简单文件类型**:HDFS专注于基本文件类型,不支持复杂的元数据管理或并发写入,适合对文件复杂性要求不高的应用场景。
然而,HDFS也存在局限性:
- **低延迟访问**:由于其设计目标,HDFS并不适合对实时响应时间有严格要求的应用,如在线事务处理。
- **小文件存储**:HDFS对于大量小文件的存储效率不高,因为每个块的大小固定,过多的小文件会占用大量空间且管理不便。
- **并发写入限制**:由于NameNode的单点故障风险,HDFS不支持多用户并发写入或随意修改文件,需考虑数据一致性策略。
在实现机制上,NameNode和SecondaryNameNode作为名称节点,共同维护系统状态,提供高可用性。NameNode负责主控,而SecondaryNameNode用于定期备份和检查NameNode的状态,确保在主节点出现故障时可以快速切换。
HDFS是大数据时代的重要基石,理解其架构、特点和局限性对于在实际项目中有效利用分布式存储至关重要。通过合理配置和优化,HDFS能够满足大规模数据处理和存储的需求。
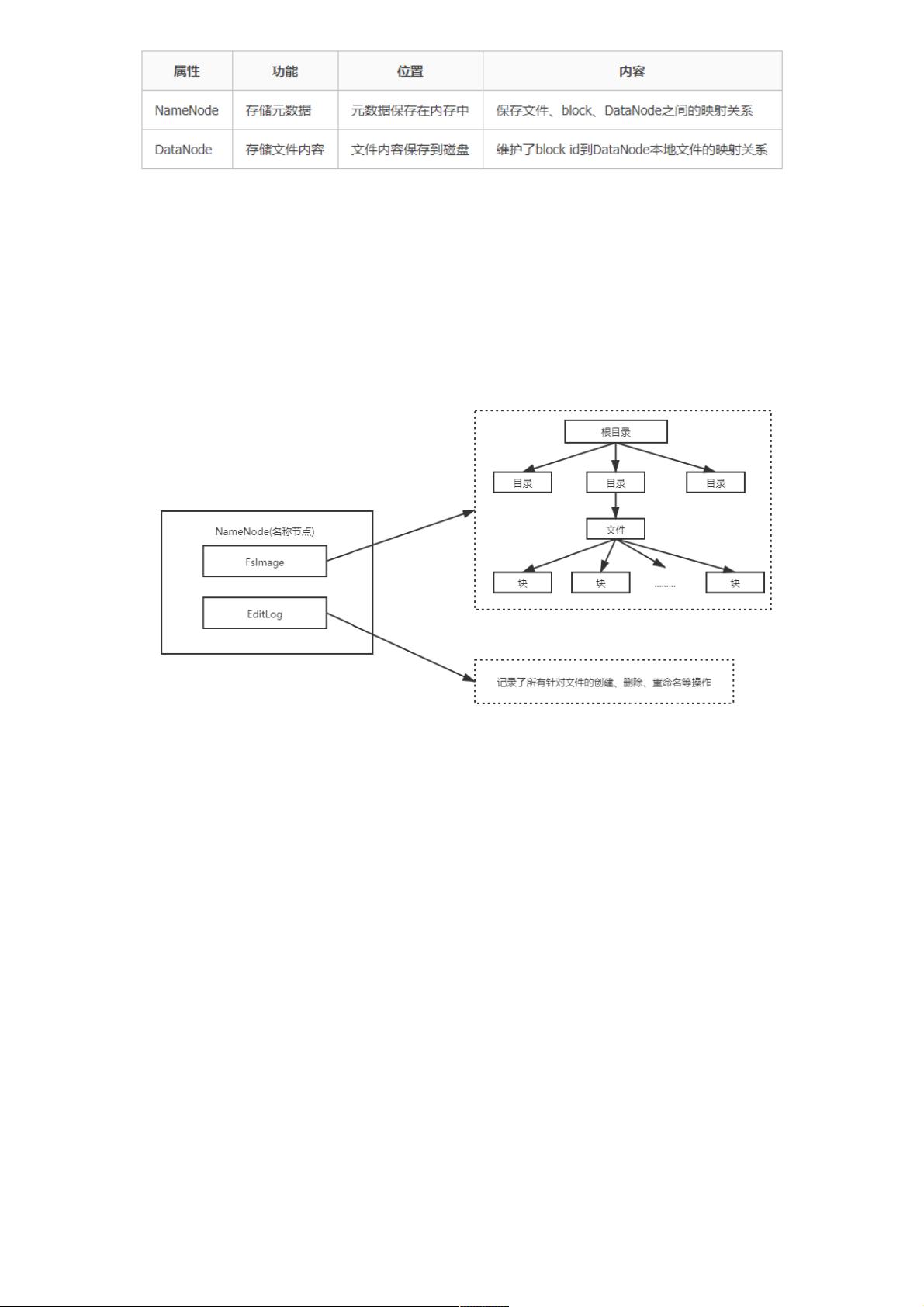
名称节点的数据结构
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间 (Namespace),保存了两个核心的数据结构,
即FsImage和EditLog 。名称节点记录了每个文件中各个块所在的数据节点的位置信息。
FsImage
用于维护文件系统树以及文件树中所有的文件和文件夹的元数据 。
EditLog
操作日志文件,其中记录了所有针对文件的创建、删除、重命名等操作 。
FsImage
FsImage文件包含文件系统中所有目录和文件inode的序列化形式。每个inode是一 个文件或目录的元数据的内部表示,并包含
此类信息:文件的复制等级、修改和访问 时间、访问权限、块大小以及组成文件的块。对于目录,则存储修改时间、权限和
配 额元数据 。
FsImage文件没有记录块存储在哪个数据节点。而是由名称节点把这些映射保留在 内存中,当数据节点加入HDFS集群时,数
据节点会把自己所包含的块列表告知给名 称节点,此后会定期执行这种告知操作,以确保名称节点的块映射是最新的。
名称节点的启动
在名称节点启动的时候,它会将FsImage文件中的内容加载到内存中,之后再执行 EditLog文件中的各项操作,使得内存中的
元数据和实际的同步,存在内存中的元数 据支持客户端的读操作。
一旦在内存中成功建立文件系统元数据的映射,则创建一个新的FsImage文件和一个空的EditLog文件。
名称节点起来之后,HDFS中的更新操作会重新写到EditLog文件中,因为FsImage 文件一般都很大(GB级别的很常见),如
果所有的更新操作都往FsImage文件中添 加,这样会导致系统运行的十分缓慢,但是,如果往EditLog文件里面写就不会这样
,因为EditLog 要小很多。每次执行写操作之后,且在向客户端发送成功代码之前, edits文件都需要同步更新。
名称节点运行期间EditLog不断变大的问题
在名称节点运行期间,HDFS的所有更新操作都是直接写到EditLog中,久而久之, EditLog文 件将会变得很大 。
虽然这对名称节点运行时候是没有什么明显影响的,但是,当名称节点重启的时候,名称节点 需要先将FsImage里面的所有
内容映像到内存中,然后再一条一条地执行EditLog中的记录,当EditLog文件非常大的时候,会导致名称节点启动操作非常
慢,而在这段时间内HDFS系统处于安全模式,一直无法对外提供写操作,影响了用户的使用。
名称节点运行期间EditLog不断变大的问题,如何解决?答案是:SecondaryNameNode第二名称节点。
第二名称节点是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS元数据信息的备份,并减少名称节点重启的
时间。SecondaryNameNode一般是单独运行在一台机器上。
剩余11页未读,继续阅读
2017-09-13 上传
2020-06-14 上传
点击了解资源详情
2022-07-11 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38725426
- 粉丝: 6
- 资源: 936
 我的内容管理
展开
我的内容管理
展开







最新资源
- NIST REFPROP问题反馈与解决方案存储库
- 掌握LeetCode习题的系统开源答案
- ctop:实现汉字按首字母拼音分类排序的PHP工具
- 微信小程序课程学习——投资融资类产品说明
- Matlab犯罪模拟器开发:探索《当蛮力失败》犯罪惩罚模型
- Java网上招聘系统实战项目源码及部署教程
- OneSky APIPHP5库:PHP5.1及以上版本的API集成
- 实时监控MySQL导入进度的bash脚本技巧
- 使用MATLAB开发交流电压脉冲生成控制系统
- ESP32安全OTA更新:原生API与WebSocket加密传输
- Sonic-Sharp: 基于《刺猬索尼克》的开源C#游戏引擎
- Java文章发布系统源码及部署教程
- CQUPT Python课程代码资源完整分享
- 易语言实现获取目录尺寸的Scripting.FileSystemObject对象方法
- Excel宾果卡生成器:自定义和打印多张卡片
- 使用HALCON实现图像二维码自动读取与解码
