Lucene源码剖析中文版:从入门到精通
需积分: 9 156 浏览量
更新于2024-07-23
收藏 1.24MB PDF 举报
"这是一份关于Lucene的中文文档,适合Lucene初学者,内容包括Lucene的基本介绍、索引文件结构及其创建过程等。"
Lucene是一个强大的全文搜索引擎库,由Apache软件基金会开发并维护。它允许开发者在自己的应用程序中实现高效、可扩展的搜索功能。这份中文文档详细解析了Lucene的源码,帮助读者深入理解其工作原理。
文档首先介绍了Lucene的主要特性,包括其高度可定制性、高性能以及对多种文本格式的支持。Lucene的API主要由几个核心组件构成,如Analyzer(分析器)用于处理文本输入,Document(文档)用于存储数据,IndexWriter(索引写入器)用于创建和更新索引,而Searcher(搜索器)则用于执行查询。
在“HelloWorld!”部分,初学者可以了解如何创建一个简单的Lucene索引和执行基本的搜索操作。接着,文档详细阐述了Lucene的roadmap,展示了Lucene未来的发展方向和改进计划。
接下来的部分,文档深入到Lucene的索引文件结构。索引数据主要由一系列术语和约定组成,如文档编号、字段种类、片断和倒排索引。倒排索引是Lucene的核心,它将文档中的词项映射到包含这些词项的文档列表。字段有多种类型,如存储字段(stored fields)用于存储原始数据,索引字段(indexed fields)用于搜索,以及分词字段(tokenized fields)用于分析和索引文本。
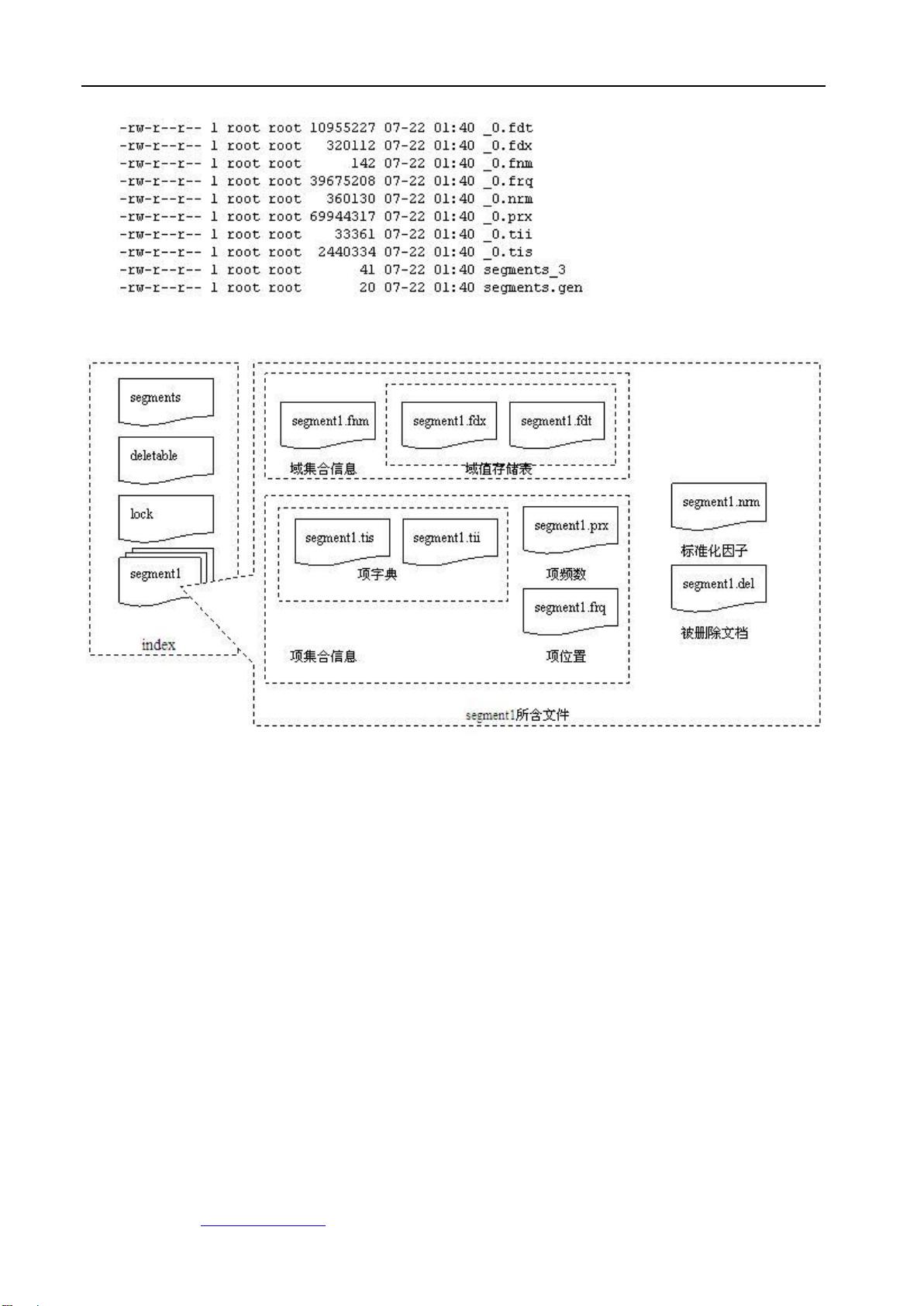
文档详细列出了各种索引文件,如Segments文件记录了索引的分片信息,Lock文件用于并发控制,Deletable文件标记已删除的文档,Compound文件(.cfs)用于合并多个小文件以提高性能。每个Segment包含的文件,如Field信息文件(.fnm),Field数据文件(.fdx和.fdt),Term字典(.tii和.tis),Term频率数据(.frq),Positions位置信息(.prx),Norms调节因子文件(.nrm),Term向量文件,以及删除文档标记(.del)等,这些都是构建和检索索引所必需的。
文档还讨论了Lucene的局限性,包括对大文件的处理限制、内存消耗问题以及某些特定场景下的性能瓶颈。
最后,文档通过一个索引创建示例,指导读者实践如何使用Lucene建立索引。这个过程涉及分析文本、创建文档对象、配置IndexWriter以及添加文档到索引。
通过这份详尽的中文文档,读者不仅能了解到Lucene的基本概念,还能深入到其内部机制,为日后的开发工作打下坚实基础。

Javen-Studio 咖啡小屋 – Annotated Lucene(源码剖析中文版)
作者
naven
网站
http://javenstudio.org/
- 9 -
3.1.5 文档编号(document numbers)
在内部(internally), Lucene 通过一个整数的(interger)文档编号(document number)来表示文档。第一
篇被添加到索引中的文档编号为 0(be numbered zero),每一篇随后(subsequent)被添加的 document 获得一
个比前一篇更大的数字(a number one greater than the previous)。
需要注意的是一篇文档的编号(document’s number)可以更改,所以在 Lucene 之外(outside of)存储这
些编号时需要特别小心(caution should be taken)。详细地说(in particular),编号在如下的情况(following
situations)可以更改:
1. 存储在每个 segment 中的编号仅仅是在所在的 segment 中是唯一的(unique),在它能够被使用在(be
used in)一个更大的上下文(a larger context)中前必须被转变(converted)。标准的技术(standard
technique)是给每一个 segment 分配(allocate)一个范围的值(a range of values),基于该 segment
所使用的编号的范围(the range of numbers)。为了将一篇文档的编号从一个 segment 转变为一个扩展
的值(an external value),该片断的基础的文档编号(base document number)被添加(is added)。 为
了将一个扩展的值(external value)转变回一个 segment 的特定的值(specific value),该 segment 将
该扩展的值所在的范围标识出来(be indentified),并且该 segment 的基础值(base value)将被减少
(substracted)。例如,两个包含 5 篇文档的 segments 可能会被合并(combined),所以第一个 segment
有一个基础的值(base value)为 0,第二个 segment 则为 5。在第二个 segment 中的第 3 篇文档(document
three from the second segment)将有一个扩展的值为 8。
2. 当文档被删除的时候,在编号序列中(in the numbering)将产生(created)间隔段(gaps)。这些最
后(eventually)在索引通过合并演进时(index evolves through merging)将会被清除(removed)。 当
segments 被合并后(merged),已删除的文档将会被丢弃(dropped),一个刚被合并的(freshly-merged)
segment 因此在它的编号序列中(in its numbering)不再有间隔段(gaps)。
3.1.6 索引结构概述
每一个片断的索引(segment index)管理(maintains)如下的数据:
1. Fields 名称:这包含了(contains)在索引中使用的一系列 fields 的名称(the set of field names)。
2. 已存储的 field 的值:它包含了,对每篇文档来说,一个属性-值数据对(attribute-value pairs)的清单
(a list of),其中属性即为 field 的名字。这些被用来存储关于文档的备用信息(auxiliary information),
比如它的标题(title)、 url、或者一个访问一个数据库(database)的唯一标识(identifier)。这套存储
的 fields 就是那些在检索时对每一个命中的(hits)文档所返回的(returned)信息。这些是通过文档
编号(document number)来做为 key 得到的。
3. Term 字典(dictionary):一个包含(contains)所有 terms 的字典,被使用在所有文档中所有被索引
的 fields 中。它还包含了该 term 所在的文档的数目(the number of documents which contains the term),
并且指向了(pointer to)term 的频率(frequency)和接近度(proximity)的数据(data)。
4. Term 频率数据(frequency data): 对字典中的每一个 term 来说,所有包含该 term(contains the term)
的文档的编号(numbers of all documents),以及该 term 出现在该文档中的频率(frequency)。
5. Term 接近度数据(proximity data): 对字典中的每一个 term 来说,该 term 出现在(occur)每一篇
文档中的位置(positions)。
6. 调整因子(normalization factors):对每一篇文档的每一个 field 来说,为一个存储的值(a value is stored)
用来加入到(multiply into)命中该 field 的分数(score for hits on that field)中。
7. Term 向量(vectors): 对每一篇文档的每一个 field 来说,term 向量(有时候被称做文档向量)可以

剩余52页未读,继续阅读
2022-07-12 上传
2022-07-13 上传
2016-04-13 上传
2023-08-09 上传
2008-10-03 上传
2011-12-03 上传
2018-08-25 上传
2009-11-18 上传

qq_14995607
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- lianjia-spider:链家二手房爬虫,支持爬取指定城市,户型,价位二手仓库,并通过电子提供跨平台UI,可记录历史价格,售出仓库等信息
- NetCDF数据在ArcMap中的使用
- spark-ifs:使用Apache Spark在大型数据集上基于迭代过滤器的特征选择
- quazip 压缩解压库 qt c++
- my-max-gps
- elastic
- 图像相似度识别比较案例
- WuBinCPP-MCU_Font_Release-master.zip
- eslint-plugin-no-es2015:一些禁用es2015的eslint规则
- 购物
- DotNetHomeWork:武汉大学周三上软件构造基础作业仓库
- linkedin-clone:LinkedIn Clone由React和Redux制作
- 实用数据分析:利用python进行数据分析
- Noobi:一个执行Shellcode的简单工具,能够检测鼠标移动
- Codecademy项目:学习数据科学时完成的项目
- separator-escape
