深入理解Apache Spark:核心技术与实践
"Mastering Apache Spark 是一本深入探讨Apache Spark技术的书籍,涵盖了Spark的核心组件、数据传输、网络服务、Web界面以及存储机制等多个方面。这本书详细解析了Spark的架构和工作原理,旨在帮助读者全面理解和高效使用Apache Spark进行大数据处理。"
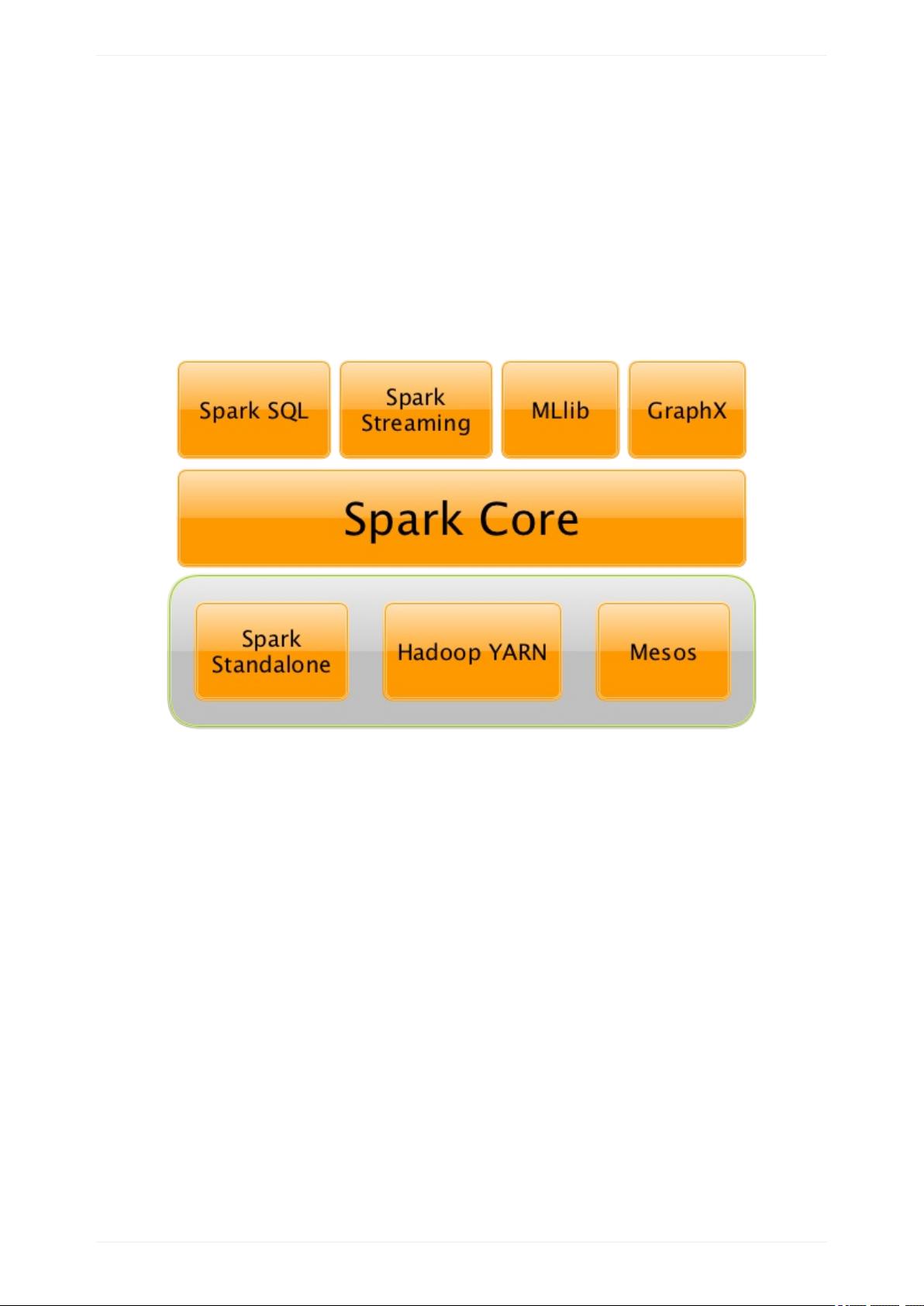
Apache Spark是一个开源的并行计算框架,其主要设计目标是提供快速、通用和可扩展的数据处理能力。书中首先介绍了Spark概述,讲解了Spark如何在分布式环境中处理大规模数据,并强调了其内存计算的特点,使得数据处理速度相比传统Hadoop MapReduce有了显著提升。
在Spark Core部分,书中详细讨论了数据块在Spark集群中的传输机制。ShuffleClient和BlockTransferService是核心组件,负责数据块的获取和上传。ShuffleClient定义了获取shuffle blocks的接口,而BlockTransferService则提供了可插拔的实现,如NettyBlockTransferService,用于通过Netty网络库进行数据传输。NettyBlockRpcServer作为服务端处理RPC请求,BlockFetchingListener、RetryingBlockFetcher、BlockFetchStarter等辅助类协同工作,确保数据传输的可靠性和效率。
Spark Core的Web UI是监控和诊断Spark应用的重要工具,它提供了Jobs、Stages、Storage、Environment和Executors等视图。Jobs Tab展示了所有作业的状态和进度,Stages Tab详细列出了作业中的执行阶段,Storage Tab显示数据存储情况,Environment Tab揭示了运行环境的配置信息,而Executors Tab则展示执行器的详细状态。这些功能帮助用户实时监控应用性能,定位问题并优化配置。
在存储机制方面,书本详细介绍了RDD(Resilient Distributed Datasets)的概念,它是Spark中最基本的数据抽象。RDD具有容错性,能够在数据丢失时自动恢复。StoragePage和RDDPage提供了查看和管理存储在内存或磁盘中的RDD的界面,而EnvironmentPage展示了存储配置,如缓存策略和持久化级别。
"Mastering Apache Spark"深入剖析了Spark的各个组件和工作流程,对想要掌握Spark的大数据专业人员来说,是一份非常有价值的参考资料。通过学习本书,读者能够更好地理解和利用Spark的强大功能,提升大数据处理的能力和效率。

MasteringApacheSpark(2.3.1)
WelcometoMasteringApacheSparkgitbook!I’mveryexcitedtohaveyouhereandhope
youwillenjoyexploringtheinternalsofApacheSpark(Core)asmuchasIhave.
IwritetodiscoverwhatIknow.
—FlanneryO'Connor
I’mJacekLaskowski,anindependentconsultant,softwaredeveloperandtechnicalinstructor
specializinginApacheSpark,ApacheKafkaandKafkaStreams(withScala,sbt,
Kubernetes,DC/OS,ApacheMesos,andHadoopYARN).
Ioffersoftwaredevelopmentandconsultancyserviceswithveryhands-onin-depth
workshopsandmentoring.Reachouttomeatjacek@japila.plor@jaceklaskowskito
discussopportunities.
ConsiderjoiningmeatWarsawScalaEnthusiastsandWarsawSparkmeetupsinWarsaw,
Poland.
Tip
I’malsowritingMasteringSparkSQL,MasteringKafkaStreams,ApacheKafka
NotebookandSparkStructuredStreamingNotebookgitbooks.
Expecttextandcodesnippetsfromavarietyofpublicsources.Attributionfollows.
Now,letmeintroduceyoutoApacheSpark.
Introduction
16

剩余1351页未读,继续阅读
2017-01-14 上传
2017-12-06 上传
2018-02-08 上传
452 浏览量
2016-12-11 上传
2018-04-03 上传
2018-03-24 上传
103 浏览量

隐分隔符对象
- 粉丝: 10
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







