利用LSTM与U检验建模:大流行预测与无症状感染者分布
需积分: 0 175 浏览量
更新于2024-07-15
5
收藏 909KB PDF 举报
"这篇文档是关于2020年广州数模联赛的参赛论文,主要研究如何预测传染病大流行、无症状感染者的分布建模以及相应的防控策略。论文使用了LSTM时序网络进行大流行预测,通过多重分层抽样和U检验分析无症状感染者的分布,并利用遗传算法解决隔离委员会的选址和工作路径优化问题。"
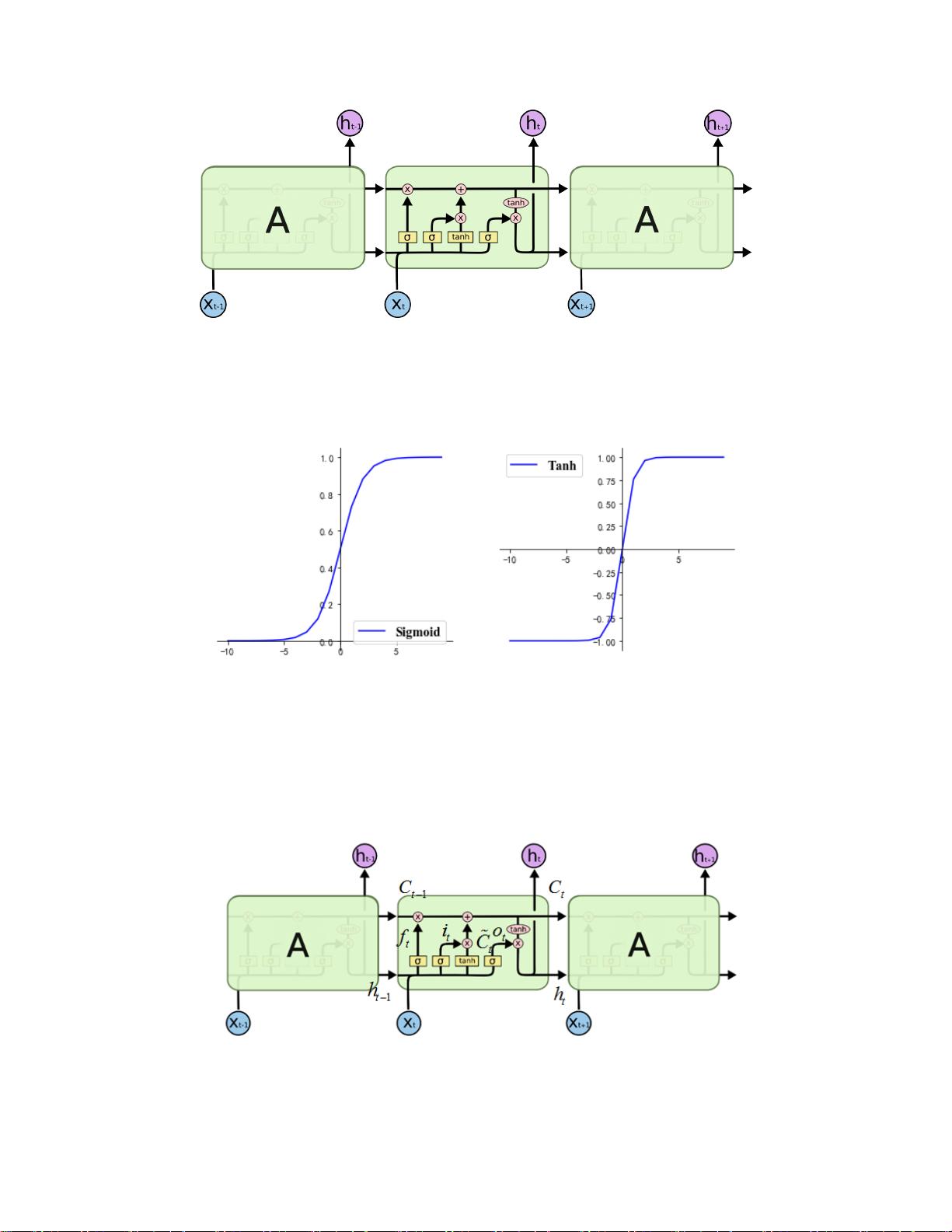
在这篇论文中,作者们深入探讨了两个关键问题。首先,他们利用LSTM(长短时记忆网络)构建时序预测模型,以预测全球疫情的发展趋势。LSTM是一种特殊的循环神经网络,特别适合处理时间序列数据,如历史疫情数据,它能够捕获数据中的长期依赖关系。通过结合经济、人口等多种因素,预处理后的数据被标记,使得模型能够学习到导致大流行的特征,从而预测未来的疫情发展。
其次,论文提出了一个基于多重分层抽样的方法来确定无症状感染者的分布。多重分层抽样允许在不同层次(如地域、年龄段)上进行系统性采样,确保样本的代表性和时序性。通过对各区域病毒传播的评估,结合U检验(一种假设检验方法),可以识别高风险区域,进一步构建无症状感染者的分布模型。这种模型有助于制定更精确的防控策略,例如在高危区域实施局部的全民检测。
此外,论文还引入了遗传算法来解决多旅行商问题,以优化隔离委员会的选址及工作小组的路径规划。遗传算法是一种模拟自然选择和遗传机制的全局优化方法,能有效寻找多目标优化问题的近似最优解。在这个场景下,它帮助确定最佳的隔离委员会位置,以及工作小组在执行任务时最有效的路径,以最大化资源分配效率。
论文结尾部分,作者总结了建模过程中的优点和不足,并提出了改进方案和未来的研究方向。关键词涵盖了序列预测、LSTM神经网络、多重分层抽样、U检验、多旅行商问题和遗传算法,这些都反映了论文的核心技术和研究内容。
这篇论文展示了如何综合运用数据科学、统计学和优化方法来应对公共卫生挑战,对于理解和预防类似新冠病毒这样的大流行病具有重要的参考价值。

剩余35页未读,继续阅读
2018-10-21 上传
2021-11-08 上传
2021-11-30 上传
2022-05-21 上传
2021-11-01 上传

zhuo木鸟
- 粉丝: 2599
- 资源: 25
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
