揭秘Spark内核:组件、调度与运行流程详解
需积分: 10 121 浏览量
更新于2024-07-16
收藏 2.08MB DOCX 举报
Spark内核解析文档深入探讨了Apache Spark这个强大的大数据处理框架的核心运行机制。Spark是一个基于内存计算模型的分布式计算系统,它以其高效性和可扩展性在大数据处理领域备受瞩目。本文档由作者章鹏撰写,旨在帮助学习者理解Spark的内核原理,以便更好地进行代码设计和问题诊断。
首先,Spark内核主要包括以下几个关键组件:
1. **Driver**:Spark作业的控制中心,它执行main方法并负责任务的转换(将用户程序转化为任务),任务调度(在Executor间分配任务),监控Executor执行状态,以及通过UI展示查询运行状况。Driver节点在整个Spark作业生命周期中起着核心作用。
2. **Executor**:每个Executor都是一个运行在集群中的JVM实例,负责执行具体的任务。它们是Spark并行计算的基础,每个Executor有自己的内存管理器(BlockManager),用于存储用户程序中的RDD(弹性分布式数据集)。RDD的缓存使得数据能在多个任务中重复利用,提高了计算效率。
Spark的通用运行流程如下:
- 用户提交任务到集群,Driver启动并注册应用程序。
- 集群管理器根据任务配置文件分配和启动Executor,确保Driver所需的资源可用。
- Driver开始执行用户提供的main函数,但Spark查询遵循懒加载策略,只有遇到action操作才会触发真正的计算。
- 查询执行时,通过宽依赖分析(Wide Dependency)将任务划分为多个Stage,每个Stage包含一个TaskSet,TaskSet中的任务按本地化原则分发到合适的Executor执行。
- 在任务执行过程中,Executor负责执行任务并将结果返回给Driver,同时维护内存中RDD的缓存,以支持后续计算的快速访问。
理解这些核心组件和运行流程对于优化Spark应用程序性能至关重要,掌握它们有助于避免性能瓶颈,提升大数据处理的效率和准确性。此外,通过学习Spark内核,开发者可以更好地定位和解决在项目中遇到的问题,实现更高效的分布式计算。
———————————————
尚硅谷大数据课程之 Spark 内核解析
——————————————
【更多 Java、HTML5、Android、python、大数据 资料下载,可访问尚硅谷(中国)官
网下载区】
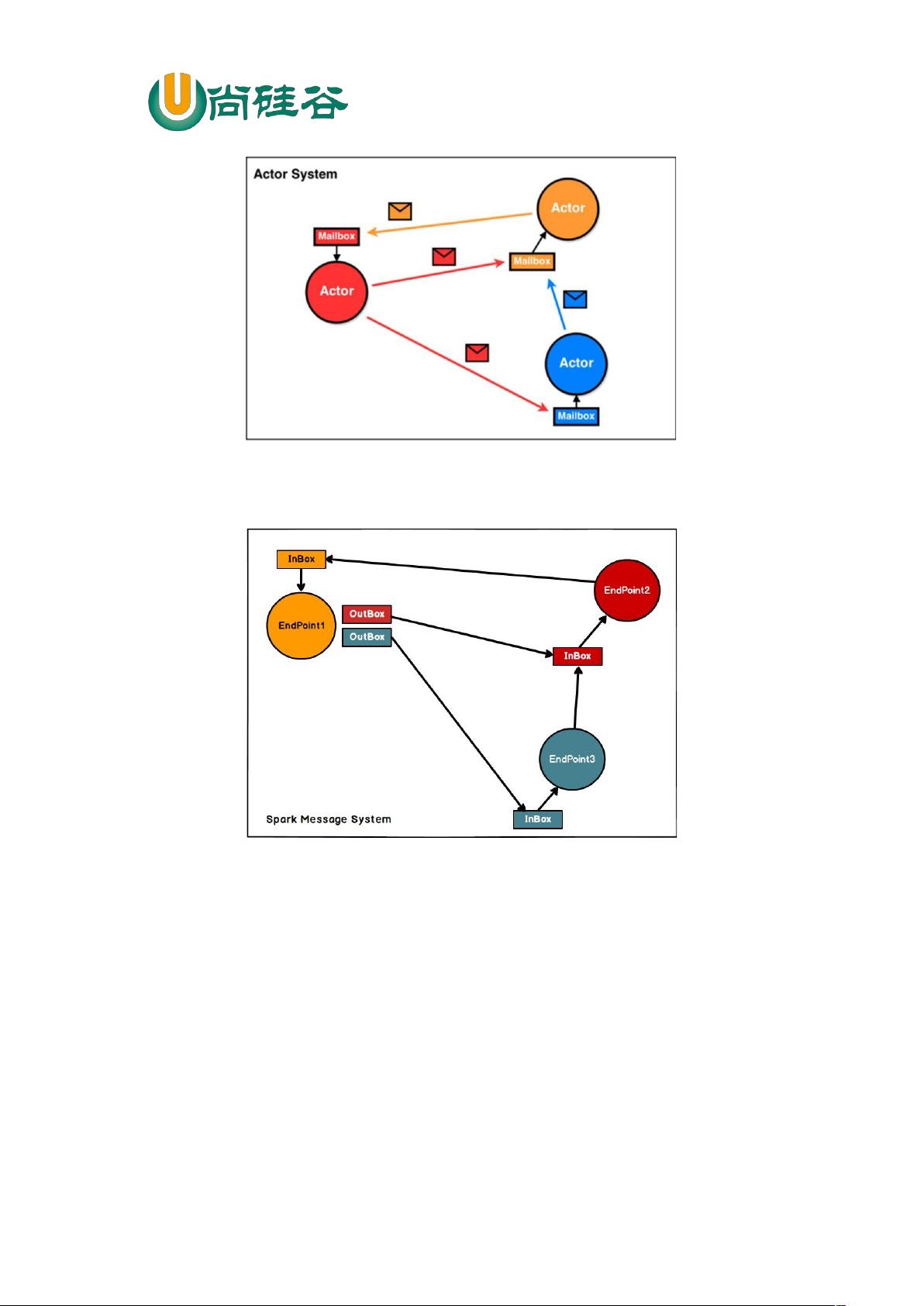
图 4-1 Actor 模型
Spark 通讯框架中各个组件( Client/Master/Worker)可以认为是一个个独立的实
体,各个实体之间通过消息来进行通信。具体各个组件之间的关系图如下:
图 4-2 Spark 通讯架构
Endpoint( Client/Master/Worker) 有 1 个 InBox 和 N 个 OutBox( N>=1,N 取决
于当前 Endpoint 与多少其他的 Endpoint 进行通信, 一个与其通讯的其他 Endpoint 对
应一个 OutBox) , Endpoint 接收到的消息被写入 InBox , 发送出去的消息写入
OutBox 并被发送到其他 Endpoint 的 InBox 中。
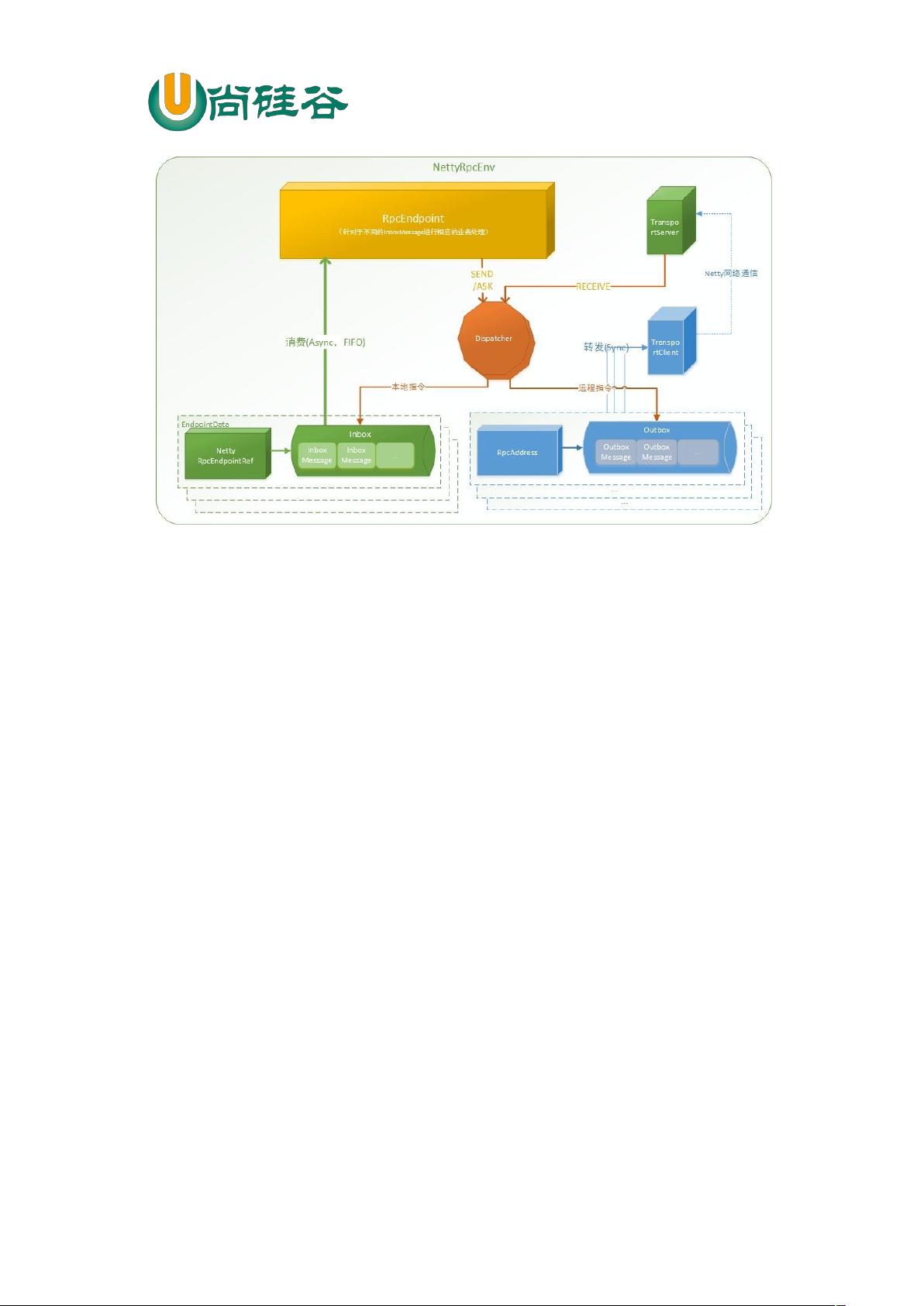
3.2 Spark 通讯架构解析
Spark 通信架构如下图所示:
剩余40页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-05-26 上传
2022-12-18 上传

wzcwangxiaozhang
- 粉丝: 1
- 资源: 46
 我的内容管理
展开
我的内容管理
展开







最新资源
- AMQPStorm-2.2.2-py2.py3-none-any.whl.zip
- box-stacking-game:使用HTML,CSS和JS制作的盒装游戏
- 基于java记账管理系统软件程序设计源码+WORD毕业设计论文文档.zip
- es:博客介绍
- Data_Structure
- asme:流行病学高级统计方法注释
- Tcl Ad Banner System-开源
- AMQPStorm-1.3.0-py2.py3-none-any.whl.zip
- crowd.hyoo.ru:拥挤-类似于CRDT,但效果更好
- android_platform_frameworks_opt_colorpicker:android_platform_frameworks_opt_colorpicker
- VB.NET通过摄像头读取二维码实例
- NetFSDProjects:此存储库适用于.Net FSD程序。 (Simplilearn)
- typora-setup-x64.rar
- mongodb集成
- AMQPStorm-2.7.2-py2.py3-none-any.whl.zip
- jsculpt-tools:搅拌机雕刻通用插件
