Kylin操作指南:从创建Project到构建Cube
需积分: 50 43 浏览量
更新于2024-07-18
收藏 720KB DOCX 举报
"这篇文档提供了一个关于Apache Kylin的操作实例,包括如何创建项目、添加数据源、构建模型以及创建立方体的关键步骤。Kylin是一个开源的、高性能的在线分析处理(OLAP)系统,用于大数据分析。通过这个实例,用户可以快速上手并理解Kylin的基本操作流程。"
在深入探讨Kylin操作实例之前,让我们先了解下Apache Kylin的基本概念。Kylin是一个预计算框架,旨在提供亚秒级的查询性能在PB级别的大数据上。它主要面向Hadoop生态系统,利用立方体技术进行大数据分析,提供SQL接口,使得用户可以方便地进行大数据查询。
### 创建Project
项目(Project)是Kylin中的基本组织单元,用于管理不同的业务分析。在Kylin的管理界面中,你可以创建新的Project,为不同的业务需求设定独立的环境。填写Project Name,可选填Description,然后提交即可创建。
### 添加数据源
数据源(DataSource)是Kylin连接到Hive表的桥梁。在项目中加载Hive表,需要指定库名和表名,同步后,数据源会被导入到Kylin中,便于后续的建模操作。
### 创建Model
Model是Kylin中数据建模的核心。首先定义Model Name,然后选择事实表和可能存在的查找表。维度(Dimension)和指标(Metric)是模型的关键部分。Partition Date Column用于指定时间分区字段,而DateFormat则定义时间的解析格式。模型创建完成后,可以添加过滤条件(Filter)来限制数据源中的数据。
### 创建Cube
Cube是预计算的数据结构,用于加速查询。选择已创建的Model,输入Cube Name,可选填报警邮件列表。在维度和指标选择阶段,可以手动添加或自动生成维度,并选择相应的指标函数,如SUM。Kylin对字段类型有特定要求,维度字段应为String,聚合字段需为bigint或decimal。设置Merge时间可以帮助优化存储和查询性能。Partition Start Date定义了数据的起始时间。
### 设置Mandatory Dimensions
Mandatory Dimensions是指在每次查询时都会用到的维度,例如时间分区字段。这些维度将被强制包含在每个查询中,有助于提高查询效率。
总结来说,这个操作实例详细介绍了Kylin的基本操作流程,对于初学者来说,是一个很好的学习资源,可以帮助他们快速掌握Kylin的使用方法,进行高效的大数据分析。
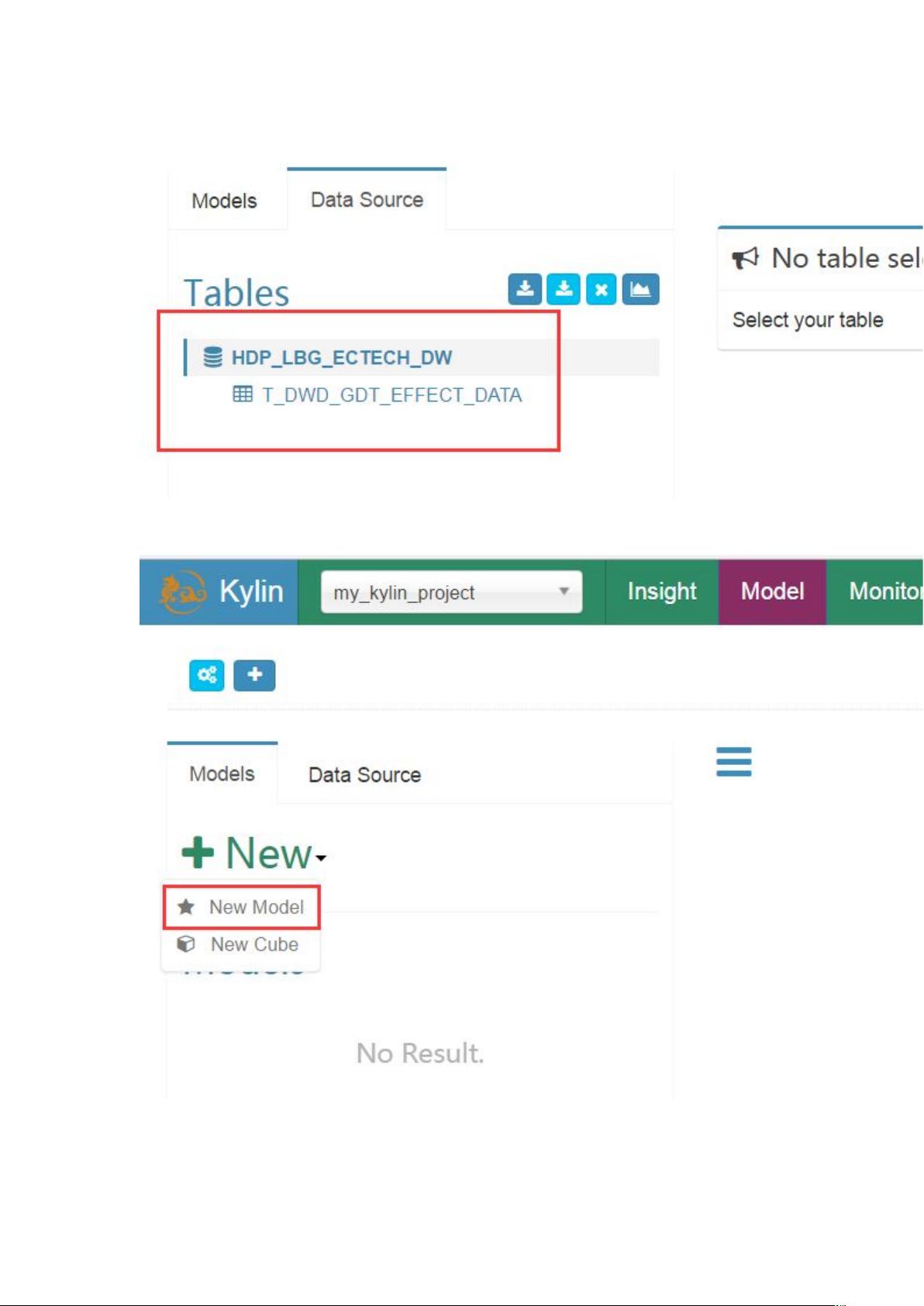
然后点击 sync,导入数据源成功,可以看到如下信息:
3.创建 model
3
剩余14页未读,继续阅读
219 浏览量
226 浏览量
280 浏览量
729 浏览量
148 浏览量
点击了解资源详情
点击了解资源详情

libinv789
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- DirectX高级动画技术探索
- Fedora 10安装指南:从升级到Yum配置
- 2009考研数学大纲解析:数一关键考点与连续函数详解
- OMRON CS1D: 双CPU可编程控制器提升系统可靠性
- Linux初学者指南:操作系统的入门与优化
- 嵌入式硬件工程师宝典:全面指南与设计艺术
- 中国UTN-SMGIP 1.2:短信网关接口协议详解
- 网上图书馆管理系统的需求分析与设计详解
- BEA Tuxedo入门教程:Jolt组件与编程详解
- X3D虚拟现实技术入门与教程
- 项目监控:关键活动与流程及问题应对
- JSP调用JavaBean实现Web数据库访问:JDBC-ODBC桥接Access
- 项目规划详解:目标、流程与关键步骤
- Oracle数据库教程:从基础到实践
- InstallShield快速入门指南:打造专业Windows安装程序
- SQL优化技巧:提升查询速度
