神经网络优化:交叉熵代价函数的作用和公式推导
需积分: 0 46 浏览量
更新于2024-08-05
收藏 1.89MB PDF 举报
交叉熵代价函数的作用及公式推导
交叉熵代价函数(Cross-entropy cost function)是一种用于衡量人工神经网络(ANN)预测值与实际值的差异的方式。它与二次代价函数相比更有效地促进ANN的训练。
在介绍交叉熵代价函数之前,我们需要了解二次代价函数的不足之处。二次代价函数的设计目的是使机器可以像人一样学习知识。但是,在实际应用中,二次代价函数存在一些缺陷。例如,在二类分类训练中,如果预测值与实际值的误差越大,参数调整的幅度可能更小,训练更缓慢。
交叉熵代价函数的公式推导可以分为以下步骤:
1. 首先,我们需要定义交叉熵代价函数的公式:H(y, y') = -∑[y log(y') + (1-y) log(1-y')]
其中,y是实际值,y'是预测值。
2. 然后,我们需要推导交叉熵代价函数的梯度:∂H/∂y' = -y/y' + (1-y)/(1-y')
3. 最后,我们可以使用梯度下降算法来最小化交叉熵代价函数。
交叉熵代价函数的优点是,它可以更好地衡量预测值与实际值的差异,从而使ANN的训练更加快速和准确。例如,在二类分类训练中,交叉熵代价函数可以使参数调整的幅度更大,训练更快收敛。
在实际应用中,交叉熵代价函数广泛应用于机器学习领域,例如图像分类、语音识别、自然语言处理等。它是ANN训练的核心组件之一,能够使ANN模型更加准确和可靠。
交叉熵代价函数是一种非常重要的机器学习技术,广泛应用于各种领域。它可以使ANN模型更加准确和可靠,提高机器学习的效率和效果。
2018/10/20 交叉熵代价函数(作用及公式推导) - Arthur-Chen的专栏 - CSDN博客
https://blog.csdn.net/u014313009/article/details/51043064?utm_source=blogxgwz0 1/9
博客 学院 下载 图文课 TinyMind 论坛 APP 问答 商城 VIP会员 活动 招聘 ITeye GitChat
搜博主文章
写博客 发Chat
原
交叉熵代价函数(作用及公式推导)
2016年04月02日 18:22:52 __鸿 阅读数:65167
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u014313009/article/details/51043064
交叉熵代价函数(Cross-entropy cost function)是用来衡量人工神经网络(ANN)的预测值与实际值的一种方式。与二次代价函数相
更有效地促进ANN的训练。在介绍交叉熵代价函数之前,本文先简要介绍二次代价函数,以及其存在的不足。
1. 二次代价函数的不足
ANN的设计目的之一是为了使机器可以像人一样学习知识。人在学习分析新事物时,当发现自己犯的错误越大时,改正的力度就越
投篮:当运动员发现自己的投篮方向离正确方向越远,那么他调整的投篮角度就应该越大,篮球就更容易投进篮筐。同理,我们希望
练时,如果预测值与实际值的误差越大,那么在反向传播训练的过程中,各种参数调整的幅度就要更大,从而使训练更快收敛。然而
次代价函数训练ANN,看到的实际效果是,如果误差越大,参数调整的幅度可能更小,训练更缓慢。
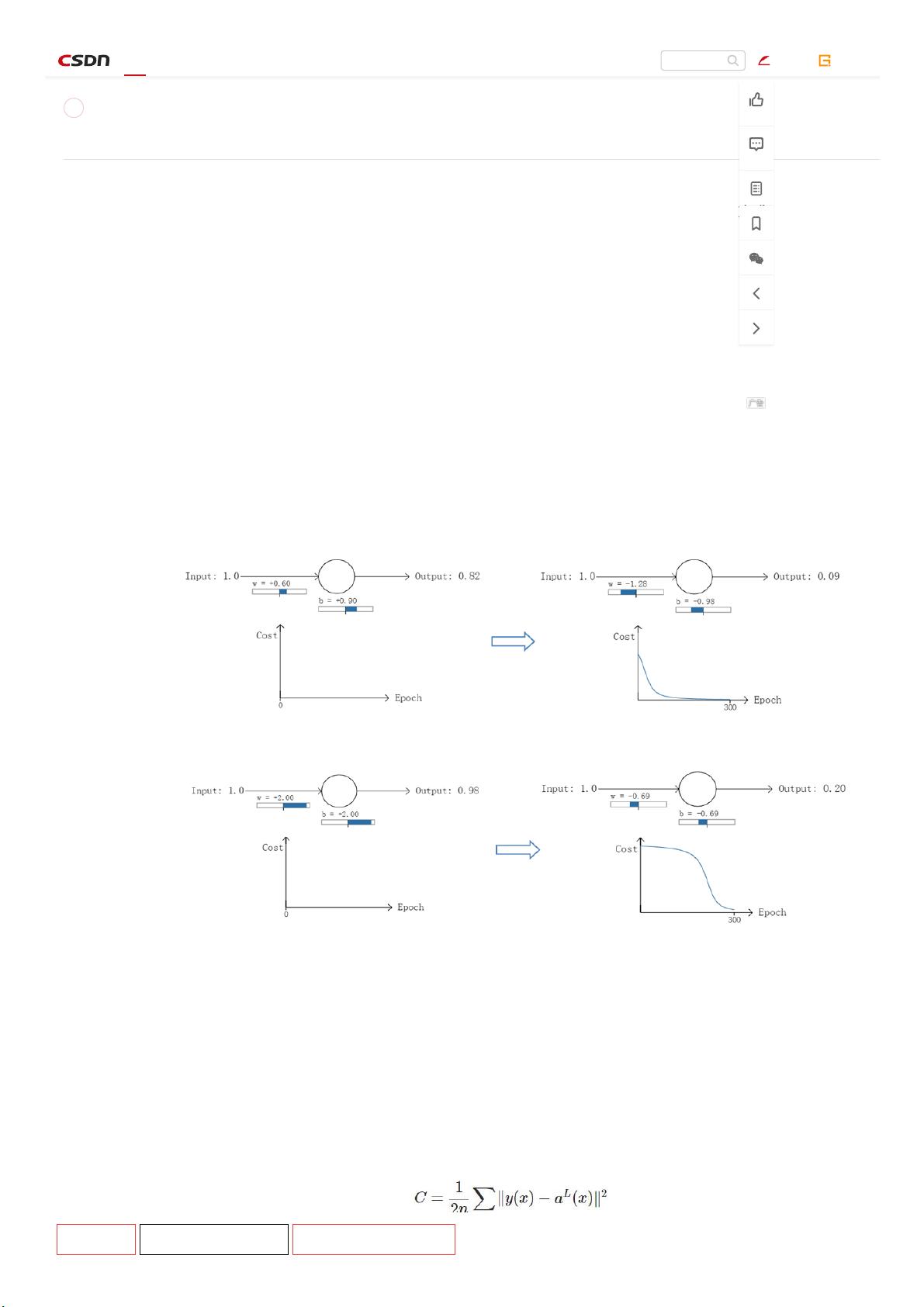
以一个神经元的二类分类训练为例,进行两次实验(ANN常用的激活函数为sigmoid函数,该实验也采用该函数):输入一个相同
x=1.0(该样本对应的实际分类y=0);两次实验各自随机初始化参数,从而在各自的第一次前向传播后得到不同的输出值,形成不同的
差):
实验1:第一次输出值为0.82
实验2:第一次输出值为0.98
在实验1中,随机初始化参数,使得第一次输出值为0.82(该样本对应的实际值为0);经过300次迭代训练后,输出值由0.82降到
实际值。而在实验2中,第一次输出值为0.98,同样经过300迭代训练,输出值只降到了0.20。
从两次实验的代价曲线中可以看出:实验1的代价随着训练次数增加而快速降低,但实验2的代价在一开始下降得非常缓慢;直观上
的误差越大,收敛得越缓慢。
其实,误差大导致训练缓慢的原因在于使用了二次代价函数。二次代价函数的公式如下:
62
23
开发者调查 AI开发者大会日程曝光 告别知识焦虑,即刻启程
涨停选股公式 日语培训
下载后可阅读完整内容,剩余8页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-03-16 上传
2021-05-23 上传
2020-02-12 上传
2015-09-22 上传
2021-04-30 上传
2022-04-06 上传

神康不是狗
- 粉丝: 39
- 资源: 336
 我的内容管理
展开
我的内容管理
展开







最新资源
- sentry-ssdb-nodestore:Sentry的SSDB NodeStore后端
- 附近JavaScript:适用于JavaScript的ArcGIS API应用程序可查找附近的地点并路由到最近的位置
- aiap-field-guide:每周Aiap课程
- Ambit Components Collection-开源
- Glider Screen-crx插件
- PCB_FDTD.zip_matlab例程_C++_Builder_
- 快速收集视图的自定义蜂窝布局-Swift开发
- js-pwdgen-wannabe
- facebook-sdk:适用于Facebook Graph API的Python SDK
- markdown文档转pdf工具
- lucy:基于键值存储网络的聊天机器人
- Year Clock-crx插件
- goodmobileirisrecognition.rar_matlab例程_matlab_
- matlab人脸检测框脸代码-opencv4nodeJs-4.5.2:适用于Node.js的OpencvBuild
- CTI110:CTI110存储库
- L-one-crx插件
