"Java程序设计实验一:搜索引擎倒排索引与分词"
 已收录资源合集
已收录资源合集
需积分: 0 90 浏览量
更新于2024-01-05
收藏 20.17MB PDF 举报
Java程序设计实验一帮助文档
2020/4/25
华中科技大学计算机学院Java语言程序设计课程组
# 1. 搜索引擎的倒排索引数据结构
搜索引擎是如何实现快速返回查询结果的呢?这涉及到搜索引擎使用的倒排索引数据结构。倒排索引是根据索引单位将文档组织起来的一种方式。索引单位在搜索引擎中通常指的是单词,也被称为"term"。
对于中文文本文档和其他语言(如英语)的文本文档,文本的内容都是由单词组成的。因此,在建立倒排索引之前,首先需要对文档进行分词处理。分词是将文本文档切分成单个单词的过程,也被称为"Tokenization"。
对于英文文档,分词相对简单,可以使用空格和标点符号作为分隔符。举例来说,对于以下英文文档:"In June, the dog likes to chase the cat in the bar;",可以将其切分成以下单词:"In", "June", "the", "dog", "likes", "to", "chase", "the", "cat", "in", "the", "bar"。
# 2. 预定义的抽象类及接口API说明
在Java程序设计实验一中,有一些预定义的抽象类和接口可以被使用。以下是这些类和接口的API说明:
### 1) AbstractIndexer
这是一个抽象类,用于实现索引器。索引器负责将文本文档进行分词,并将分词后的单词进行索引。AbstractIndexer包含以下方法:
- `abstract void tokenizer(String document)`: 用于将文本文档进行分词处理。需要注意的是,每个单词之间需要使用空格或标点符号进行分隔。
- `abstract void index(String term, int docId)`: 用于将分词后的单词进行索引,并关联到文档的ID。每个索引的单词和文档ID会被保存在索引器内部。
- `abstract List<Integer> search(String term)`: 用于根据关键词查询文档ID。返回一个包含符合查询条件的文档ID的列表。
### 2) InvertedIndex
这是实现AbstractIndexer的具体类,用于构建倒排索引。InvertedIndex包含以下方法:
- `void tokenizer(String document)`: 重写了AbstractIndexer中的tokenizer方法,用于将文本文档进行分词处理。
- `void index(String term, int docId)`: 重写了AbstractIndexer中的index方法,用于将分词后的单词进行倒排索引。
- `List<Integer> search(String term)`: 重写了AbstractIndexer中的search方法,用于根据关键词查询文档ID。
# 3. 本实验所涉及的JDK Java API说明
在完成Java程序设计实验一时,可能需要使用JDK Java API中的一些类和方法。以下是本实验所涉及的一些JDK Java API的说明:
### 1) java.util.HashMap
HashMap是Java集合框架中的一个类,用于实现散列表的数据结构。可以使用HashMap来实现倒排索引的存储。HashMap内部使用键值对的形式来存储数据,其中键表示单词,值表示文档ID的列表。
- `void put(K key, V value)`: 将指定的键值对存储到HashMap中。
- `V get(Object key)`: 根据键获取对应的值。
### 2) java.util.List
List是Java集合框架中的一个接口,用于定义有序的集合。在倒排索引中,可以使用List来存储符合查询条件的文档ID列表。
- `boolean add(E e)`: 将指定的元素添加到列表末尾。
- `E get(int index)`: 获取指定索引位置的元素。
以上是一些本实验所涉及的JDK Java API的说明,可以根据需要灵活使用。
总结:
本文档介绍了Java程序设计实验一中的一些帮助内容。首先解释了搜索引擎如何通过倒排索引实现快速返回查询结果的原理。然后详细讲解了索引单位的概念以及文本文档的分词处理方法。接着介绍了预定义的抽象类和接口,包括AbstractIndexer和InvertedIndex,并给出了它们的API说明。最后,给出了本实验所涉及的一些JDK Java API的说明,包括HashMap和List。通过学习和掌握这些内容,可以更好地完成Java程序设计实验一的任务。

2020/4/25 8
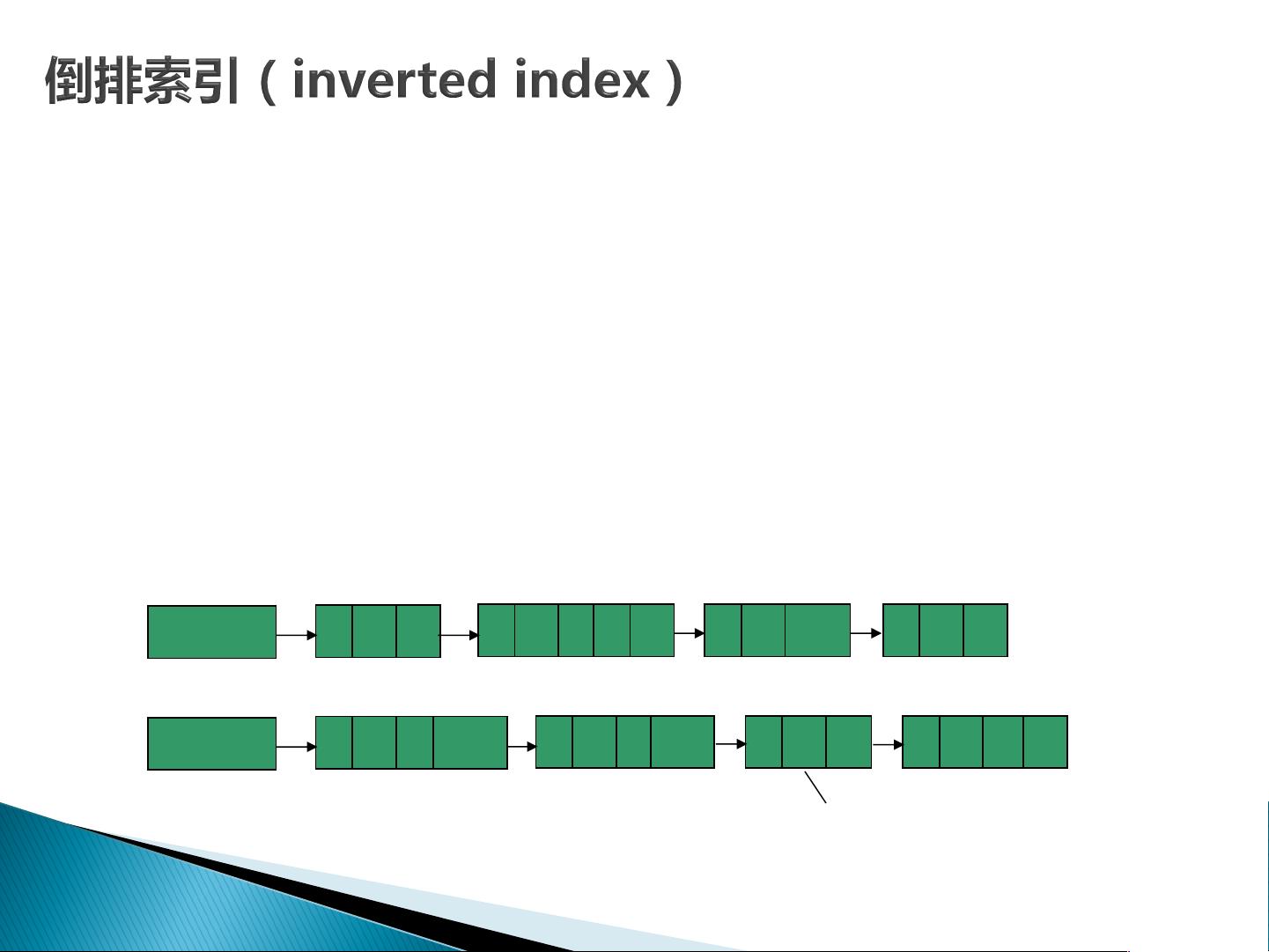
} 字典(Dictionary)
} 通俗地讲,字典就是对文档集合里每个文档分词后得到的单
词集合取并集
} 对于一个文档集合
C
= {
d
1
,
d
2
, … ,
d
n
},
C
包含
n
个文档
d
1
,
d
2
, … ,
d
n
。
} 对文档
d
i
(
i
=
1
, …,
n
)进行分词并进行分词后的处理, 得到的terms集
合记为
Terms
d
i
} 则文档集合
C
对应的字典
D
C
=每个文档分词得到的terms集合的并集,
即
D
C
=
Terms
d
1
∪
Terms
d
2
∪… ∪
Terms
d
n
} 当文档集合的字典构建好后,就可以对分词后的每个文档构建倒排索引
剩余44页未读,继续阅读
2022-08-03 上传
103 浏览量
103 浏览量
107 浏览量
123 浏览量
2021-10-06 上传

嘻嘻哒的小兔子
- 粉丝: 35
 我的内容管理
展开
我的内容管理
展开







最新资源
- DeepFreeze密码移除工具6.x版本使用教程
- MQ2烟雾传感器无线报警器项目解析
- Android实现消息推送技术:WebSocket的运用解析
- 利用jQuery插件自定义制作酷似Flash的广告横幅通栏
- 自定义滚动时间选择器,轻松转换为Jar包
- Python环境下pyuvs-rt模块的使用与应用
- DLL文件导出函数查看器 - 查看DLL函数名称
- Laravel框架深度解析:开发者的创造力与学习资源
- 实现滚动屏幕背景固定,提升网页高端视觉效果
- 遗传算法解决0-1背包问题
- 必备nagios插件压缩包:实现监控的关键
- Asp.Net2.0 Data Tutorial全集深度解析
- Flutter文本分割插件flutter_break_iterator入门与实践
- GD Spi Flash存储器的详细技术手册
- 深入解析MyBatis PageHelper分页插件的使用与原理
- DELPHI实现斗地主游戏设计及半成品源码分析
