使用Vert.x和RxJava 2构建爬虫框架实践
110 浏览量
更新于2024-09-01
收藏 346KB PDF 举报
"本文主要介绍如何使用Vert.x和RxJava 2构建一个通用的爬虫框架,通过具体的示例和代码解析,展示了一个轻量级、高性能的爬虫解决方案。"
在现代Web开发中,爬虫框架对于数据采集和监控至关重要。本示例将讲解如何结合Vert.x和RxJava 2这两个强大的工具来创建一个灵活且高效的爬虫系统。Vert.x是一个轻量级的Java框架,专注于事件驱动和非阻塞I/O,它基于Netty服务器,提供了高并发能力。而RxJava 2则是一个用于处理异步数据流的库,它的响应式编程模型非常适合爬虫的异步请求和数据处理。
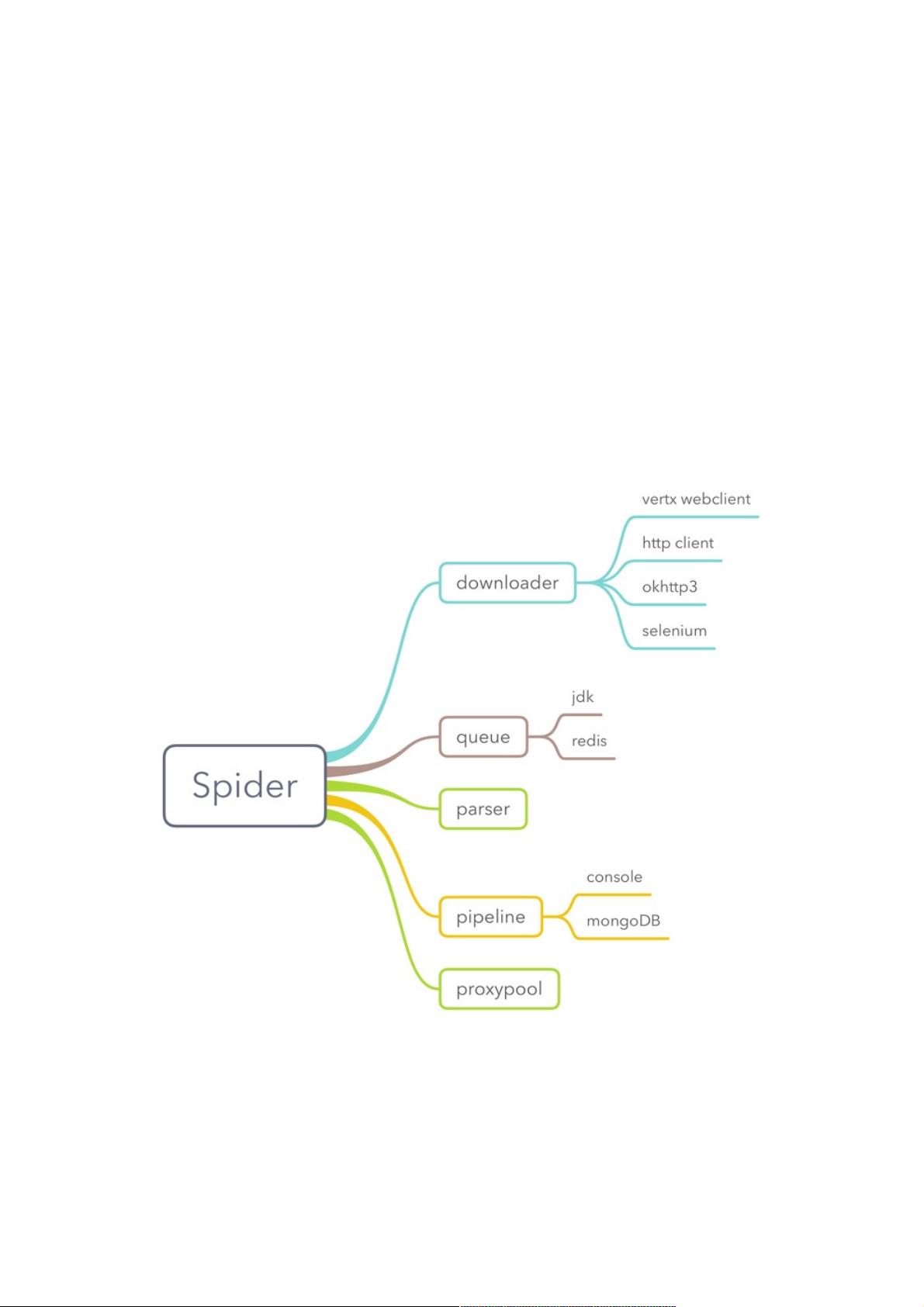
首先,爬虫框架的核心组件包括:
1. **SpiderEngine**:这是爬虫框架的管理器,它可以同时管理多个**Spider**实例,确保爬取任务的并行执行和资源的有效利用。
2. **Spider**:每个Spider负责具体的爬取任务,它包含了以下几个关键部分:
- **Downloader**:负责下载网页内容,本示例中提供了多种实现,如Vert.x的WebClient、HttpClient、OkHttp3以及Selenium,开发者可以根据需求选择或自定义下载器。Downloader的download方法返回一个`Maybe<Response>`,表示可能存在的响应结果,这体现了RxJava的反应式编程特性。
- **Queue**:存储待爬取URL的队列,确保按照特定策略进行爬取。
- **Parser**:解析下载的网页内容,提取所需信息。
- **Pipeline**:数据处理流水线,可以对抓取的数据进行清洗、转换等操作。
- **ProxyPool**(代理池):提供代理IP,对于需要频繁切换IP的爬虫任务十分有用,此项目是作者独立开发的,可以与爬虫框架集成。
在实现过程中,开发者可以利用Vert.x的事件循环机制,结合RxJava 2的流处理能力,轻松处理并发请求和结果的订阅。例如,Downloader中的`download`方法返回`Maybe<Response>`,可以方便地与其他RxJava操作符组合,实现错误处理、缓存、重试等逻辑。
此外,Vert.x提供的模块化设计使得扩展性极强,比如可以轻松添加新的下载器支持,或者通过事件总线(Event Bus)与其他模块通信,实现更复杂的分布式爬虫架构。对于大型爬虫项目,这种灵活性和可扩展性尤为重要。
总结来说,基于Vert.x和RxJava 2的爬虫框架利用了两者的优点,实现了轻量、高效、易扩展的爬虫系统。开发者可以根据具体需求定制各个组件,以适应不同场景的爬虫任务。GitHub上的项目源码提供了详细的实现细节,可供学习和参考。
基于基于Vert.x和和RxJava 2构建通用的爬虫框架的示例构建通用的爬虫框架的示例
主要介绍了基于Vert.x和RxJava 2构建通用的爬虫框架的示例,小编觉得挺不错的,现在分享给大家,也给大家
做个参考。一起跟随小编过来看看吧
最近由于业务需要监控一些数据,虽然市面上有很多优秀的爬虫框架,但是我仍然打算从头开始实现一套完整的爬虫框架。
在技术选型上,我没有选择Spring来搭建项目,而是选择了更轻量级的Vert.x。一方面感觉Spring太重了,而Vert.x是一个基于
JVM、轻量级、高性能的框架。它基于事件和异步,依托于全异步Java服务器Netty,并扩展了很多其他特性。
github地址:https://github.com/fengzhizi715/NetDiscovery
一一. 爬虫框架的功能爬虫框架的功能
爬虫框架包含爬虫引擎(SpiderEngine)和爬虫(Spider)。SpiderEngine可以管理多个Spider。
1.1 Spider
在Spider中,主要包含几个组件:downloader、queue、parser、pipeline以及代理池IP(proxypool),代理池是一个单独的项
目,我前段时间写的,在使用爬虫框架时经常需要切换代理IP,所以把它引入进来。
proxypool地址:https://github.com/fengzhizi715/ProxyPool
其余四个组件都是接口,在爬虫框架中内置了一些实现,例如内置了多个下载器(downloader)包括vertx的webclient、http
client、okhttp3、selenium实现的下载器。开发者可以根据自身情况来选择使用或者自己开发全新的downloader。
Downloader的download方法会返回一个Maybe<Response>。
package com.cv4j.netdiscovery.core.downloader;
import com.cv4j.netdiscovery.core.domain.Request;
import com.cv4j.netdiscovery.core.domain.Response;
import io.reactivex.Maybe;
/**
* Created by tony on 2017/12/23.
*/
下载后可阅读完整内容,剩余4页未读,立即下载
137 浏览量
点击了解资源详情
136 浏览量
136 浏览量
2024-11-28 上传
2024-04-08 上传
112 浏览量
112 浏览量
131 浏览量

weixin_38741759
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- R14平台上的VLISP - 提升Lisp编程体验
- MySQL5.7数据库管理完全学习手册
- 使用vaadin-material-styles定制Vaadin材料设计主题
- VB点对点聊天与文件传输系统设计及源代码下载
- 实现js左侧竖向二级导航菜单功能及源代码下载
- HTML5实战教程:.NET开发者提升技能指南(英文版)
- 纯bash脚本实现:Linux下的程序替代方案
- SLAM_Qt:简易SLAM模拟器的构建与研究
- 解决Windows 7升级至Windows 10报错0x80072F8F问题
- 蓝色横向二级导航菜单设计及js滑动动画实现
- 轻便实用的tcping网络诊断小工具教程
- DiscordBannerGen:在线生成Discord公会横幅工具介绍
- GMM前景检测技术在vs2010中的实现与运行
- 剪贴板查看工具:文本与二进制数据的终极查看器
- 提升CUBA平台开发效率:集成cuba-file-field上传组件
- Castlemacs: 将简约Emacs带到macOS的Linux开发工具
