使用Transformer进行人体姿态估计的测试时间个性化
版权申诉
109 浏览量
更新于2024-07-06
收藏 5.65MB PDF 举报
"Test-Time Personalization with a Transformer for Human Pose Estimation"
本文提出了一种使用Transformer进行人体姿态估计的测试时间个性化方法。在不依赖任何手动注释的情况下,仅通过一组测试图像,该方法能对特定个体进行人体姿态估计算法的个性化调整。尽管近年来人体姿态估计领域取得了显著进步,但模型在不同未知环境和未见过的个体上泛化仍然是一个挑战。作者们摒弃了传统的为每个测试案例使用固定模型的方式,转而在测试过程中让姿态估计器自适应地利用个人特有的信息。
首先,他们将模型训练在多样化的数据集上,同时结合监督学习和自我监督的目标进行联合训练。这里,Transformer模型被用来建立自我监督关键点与监督关键点之间的转换关系。在测试阶段,通过自我监督目标的微调,对模型进行个性化和适应。然后,通过应用这种转换,改进原始估计的姿势,从而提高准确性和鲁棒性。
Transformer模型在自然语言处理领域的成功已经被广泛认可,本文将其应用于计算机视觉领域,特别是在人体姿态估计上,这是个创新的应用。Transformer的注意力机制使其能够捕获图像中不同部分之间的长期依赖关系,这对于识别和理解人体的姿态至关重要。在没有额外标注信息的情况下,这种自我监督的微调策略允许模型根据新的测试数据自我调整,以适应个体间的差异。
此外,通过在测试时进行微调,这种方法可以有效地解决跨场景和跨个体的泛化问题。这不仅提高了模型的适应性,也降低了对大规模、多样化的注释数据集的依赖。在实际应用中,如监控系统、体育分析或医疗影像等领域,这样的个性化姿态估计可能带来更精确的结果,进而提升用户体验和分析准确性。
"用于人体姿势估计的变压器测试时间个性化"是一种针对人体姿态估计任务的新型方法,它利用Transformer的强大能力和自我监督学习来提升模型在未知环境和个体上的表现。通过在测试阶段进行模型的微调和个性化,此方法有望在实际应用中实现更高效和准确的人体姿态估计。
𝜙
Transformer
𝜙
!""
𝐹
!
"##
𝜓
#$%&
𝐹
'
𝐻
#("
𝐻
#$%&
Concatenate
Product
𝐹
$
%#
𝜙
)$*+$)
targetsource
Value 𝐹
'
ℒ
#$%&
ℒ
#("
reconstruction
Self-supervised Task
Supervised Task
Query 𝑄
#("
Key 𝐹
'
𝑊
𝐼
'
𝐼
,
)
𝐼
'
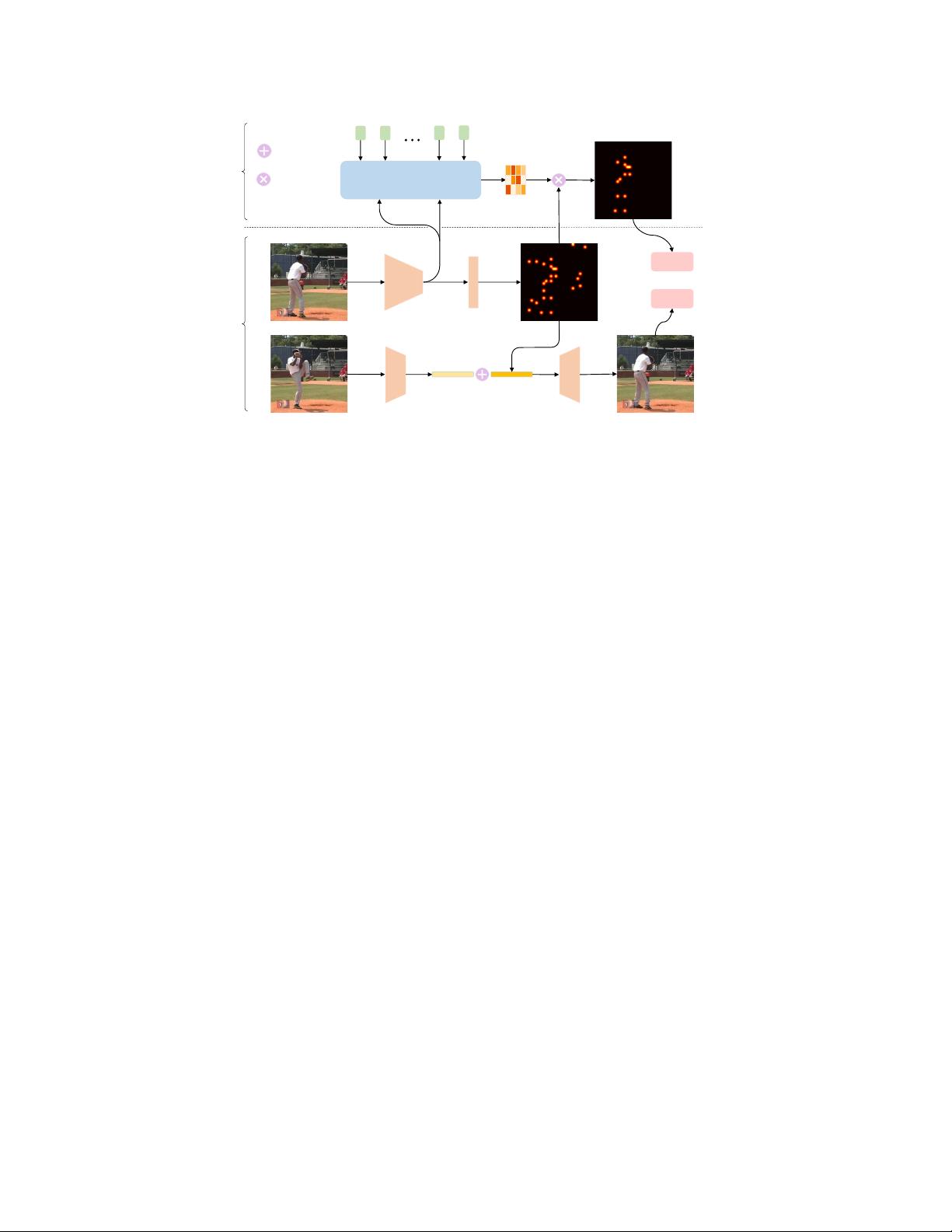
Figure 2: The proposed pipeline. 1)
Self-supervised task for personalization.
In the middle stream,
the encoder
φ
encodes the target image into feature
F
t
. Then
F
t
is fed into the self-supervised
head
ψ
self
obtaining self-supervised keypoint heatmaps
H
self
. Passing
H
self
into a keypoint encoder
(skipped in the figure) leads to keypoint feature
F
kp
t
. In the bottom stream, a source image is
forwarded to an appearance extractor
φ
app
which leads to appearance feature
F
app
t
. Together, a
decoder reconstructs the target image using concatenated
F
app
s
and
F
kp
t
. 2)
Supervised task with
Transformer.
On the top stream, a Transformer predicts an affinity matrix given learnable keypoint
queries
Q
sup
and
F
t
. The final supervised heatmaps
H
sup
is given as weighted sum of
H
self
using
W
.
simple extractor
φ
app
(see the bottom stream in Figure 2). The extraction of keypoints information
from the target image follows three steps as below (also the see the middle stream in Figure 2).
Firstly, the target image
I
t
is forwarded to the encoder
φ
to obtain shared feature
F
t
. The self-
supervised head
ψ
self
further encodes the shared feature
F
t
into heatmaps
H
self
t
. Note the number of
channels in the heatmap
H
self
t
is equal to the number of self-supervised keypoints. Secondly,
H
self
t
is
normalized using a
Softmax
function and thus becomes condensed keypoints. In the third step, the
heatmaps are replaced with fixed Gaussian distribution centered at condensed points, which serves as
keypoint information
F
kp
t
. These three steps ensure a bottleneck of keypoint information, ensuring
there is not enough capacity to encode appearance features to avoid trivial solutions.
The objective of the self-supervised task is to reconstruct the target image with a decoder using both
appearance and keypoint features:
ˆ
I
t
= φ
render
F
app
s
, F
kp
t
. Since the bottleneck structure from the
target stream limits the information to be passed in the form of keypoints, the image reconstruction
enforces the disentanglement and the network has to borrow appearance information from source
stream. The Perceptual loss [29] and L2 distance are utilized as the reconstruction objective,
L
self
= PerceptualLoss
I
t
,
ˆ
I
t
+
I
t
−
ˆ
I
t
2
(1)
Instead of self-supervised tasks like image rotation prediction [
18
] or colorization [
70
], choosing an
explicitly related self-supervised key-point task in joint training naturally preserves or even improves
performance, and it is more beneficial to test-time personalization. Attention should be paid that our
method requires only label of one single image and unlabeled samples belonging to the same person.
Compared to multiple labeled samples of the same person or even more costly consecutively labeled
video, acquiring such data is much more easier and efficient.
3.1.2 Supervised Keypoint Estimation with a Transformer
A natural and basic choice for supervised keypoint estimation is to use an unshared supervised head
ψ
sup
to predict supervised keypoints based on
F
t
. However, despite the effectiveness of multi-task
learning on two pose estimation tasks, their relation still stays plain on the surface. As similar tasks
do not necessarily help each other even when sharing features, we propose to use a Transformer
decoder to further strengthen their coupling. The Transformer decoder models the relation between
4
剩余17页未读,继续阅读
107 浏览量
328 浏览量
2021-03-21 上传
327 浏览量
2023-09-18 上传
2021-04-23 上传
132 浏览量
187 浏览量
101 浏览量


易小侠
- 粉丝: 6646
 我的内容管理
展开
我的内容管理
展开







最新资源
- Openaea:Unity下开源fanmad-aea游戏开发
- Eclipse中实用的Maven3插件指南
- 批量查询软件发布:轻松掌握搜索引擎下拉关键词
- 《C#技术内幕》源代码解析与学习指南
- Carmon广义切比雪夫滤波器综合与耦合矩阵分析
- C++在MFC框架下实时采集Kinect深度及彩色图像
- 代码研究员的Markdown阅读笔记解析
- 基于TCP/UDP的数据采集与端口监听系统
- 探索CDirDialog:高效的文件路径选择对话框
- PIC24单片机开发全攻略:原理与编程指南
- 实现文字焦点切换特效与滤镜滚动效果的JavaScript代码
- Flask API入门教程:快速设置与运行
- Matlab实现的说话人识别和确认系统
- 全面操作OpenFlight格式的API安装指南
- 基于C++的书店管理系统课程设计与源码解析
- Apache Tomcat 7.0.42版本压缩包发布
