Ubuntu虚拟机中Hadoop2.6.0详装指南:单机至完全分布式
需积分: 12 158 浏览量
更新于2024-07-21
收藏 3.1MB DOC 举报
"虚拟机中hadoop2.6.0的安装与配置,包括单机模式、伪分布式和完全分布式,在Ubuntu操作系统上的详细步骤。"
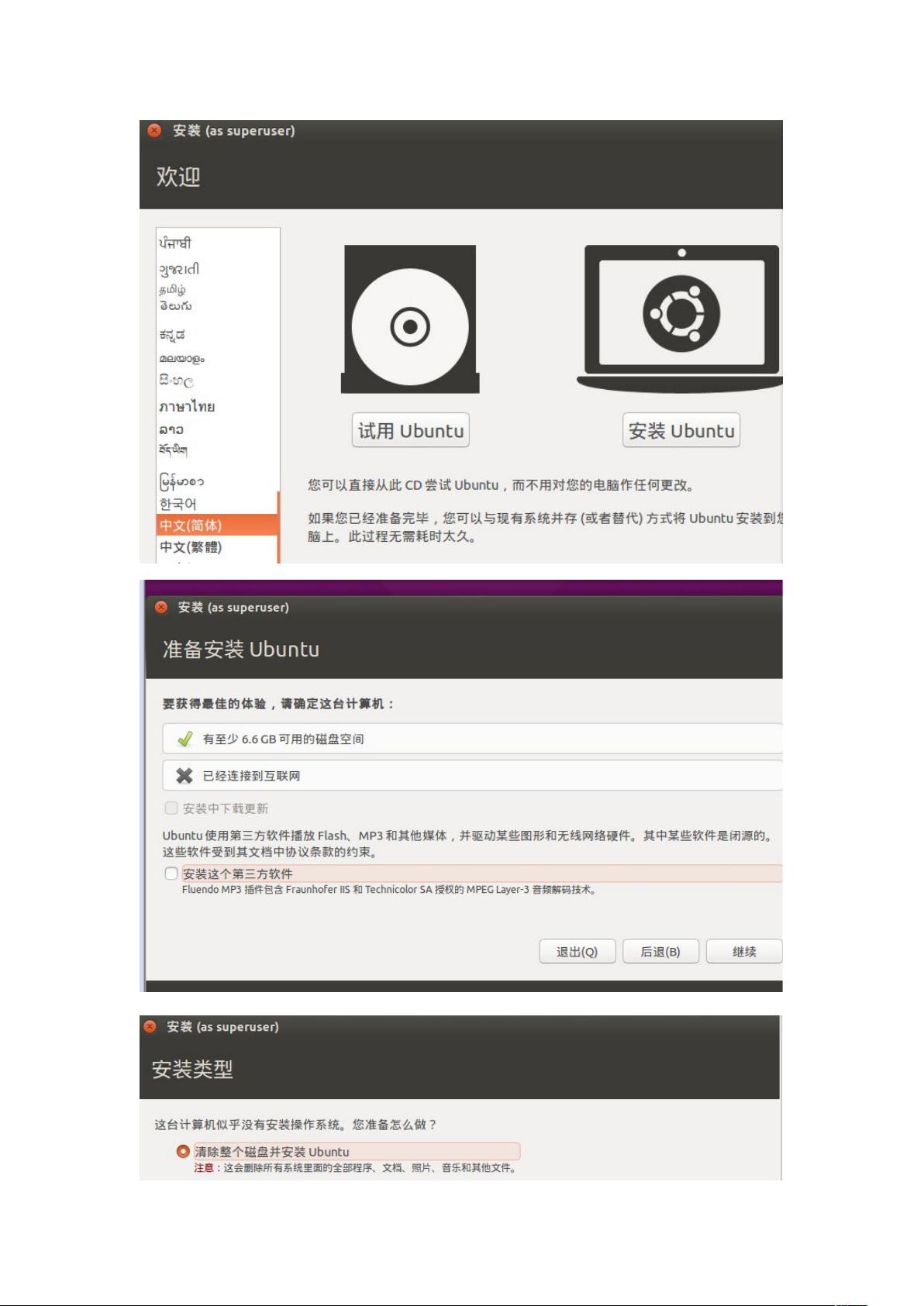
在虚拟机环境中安装和配置Hadoop 2.6.0是大数据处理的基础工作,本指南将详述在Ubuntu系统下的具体操作。首先,我们需要安装虚拟机软件VMware,选择典型安装并设定虚拟机参数,如内存大小和硬盘容量。虚拟机的Linux系统,这里选用Ubuntu,可以在不联网的情况下完成安装。安装完成后,修改虚拟机设置,确保有足够的磁盘空间,并安装VMware Tools,以优化虚拟机性能。
接着,创建一个名为hadoop的新用户组和同名用户,用于执行Hadoop相关操作。通过运行命令`groupadd hadoop`创建用户组,然后使用`sudo adduser hadoop --ingroup hadoop`创建用户,并为其设置密码。这一步骤是出于安全考虑,限制对系统的访问权限。
安装Hadoop前,需要配置环境。在新创建的hadoop用户下,下载Hadoop 2.6.0的tarball文件,并将其解压到合适的目录,如 `/usr/local/`。解压后,通过修改环境变量文件`~/.bashrc`来配置Hadoop的环境变量,包括`HADOOP_HOME`、`PATH`等,确保可以全局访问Hadoop的可执行文件。
配置Hadoop的运行模式,首先是单机模式。在Hadoop的配置文件中(如`core-site.xml`和`hdfs-site.xml`),设置`fs.defaultFS`为本地文件系统,并关闭`dfs.replication`以避免复制数据。启动Hadoop的NameNode和DataNode服务,即可在单机上运行Hadoop。
接下来是伪分布式模式,这需要在配置文件中指定HDFS和YARN的运行模式为`local`,同时设置`dfs.datanode.data.dir`指向本地的某个目录作为数据存储位置。启动所有相关服务,Hadoop将在当前节点模拟分布式环境。
最后是完全分布式模式,此模式下需要多台机器协同工作。在每台机器上重复上述步骤,配置文件中需指定主机名和各节点的角色。例如,设置`dfs.nameservices`、`dfs.namenode.rpc-address`、`dfs.namenode.http-address`等属性。还需在NameNode节点上格式化HDFS,并在所有节点上启动服务。
在所有配置完成后,使用`jps`命令检查各节点的服务是否正常运行。至此,Hadoop 2.6.0已在虚拟机的Ubuntu环境中成功安装并配置,可以进行大数据处理和分析任务。
在完全分布式模式下,还需要考虑Hadoop集群的安全性,可能涉及kerberos认证和其他安全策略的配置。此外,监控工具如Ambari可以帮助管理和监控Hadoop集群的健康状态和性能指标。在实际生产环境中,定期维护和更新Hadoop组件也至关重要,以确保系统的稳定性和安全性。
剩余22页未读,继续阅读
2017-03-05 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2016-06-15 上传

zh86411988
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
