机器学习驱动的电子设计自动化综述:进展与挑战
需积分: 10 144 浏览量
更新于2024-07-15
收藏 3.48MB PDF 举报
随着CMOS技术的缩小,大规模集成电路(VLSI)的设计复杂性呈现出显著增长。自20世纪90年代起,机器学习(Machine Learning, ML)技术在电子设计自动化(Electronic Design Automation, EDA)领域的应用就已萌芽,但近期ML技术的突破和EDA任务的日益复杂,使得人们对其在解决ED设计问题上的潜力产生了更大的兴趣。本篇综述论文由清华大学的汪玉等人撰写,涵盖了中国香港科技大学的研究团队,共同探讨了ML在EDA中的应用。
该研究旨在提供一个全面的ML在EDA领域的回顾,按照EDA流程的层级结构进行组织。EDA是一个广泛的领域,主要包括功能设计、综合、验证、物理设计(包括布局、布线、版图设计规则检查等)。在这个框架下,论文作者回顾了历史上的ML应用案例,重点关注了神经网络等机器学习模型在各个环节的潜在贡献与挑战。
机器学习在EDA中的应用可以分为以下几个方面:
1. **功能设计**:ML可以通过模式识别和预测分析帮助设计者优化电路行为,提升设计效率,尤其是在处理大规模数据集和复杂系统时。
2. **综合**:通过自动化工具,ML可以学习电路拓扑结构和约束条件,以减少手工干预,实现更高效的电路整合。
3. **验证**:ML技术可用于自动检测电路设计中的错误,提高验证的准确性和速度,减少设计迭代周期。
4. **物理设计**:布局和布线是EDA中的关键步骤,ML能支持智能路径规划、优化布局策略,甚至通过生成对抗网络(GANs)改进版图质量。
5. **设计规则检查**:ML可以协助制定更精确的设计规则,确保设计满足工艺规格,并通过模式识别快速定位和修复违规问题。
值得注意的是,论文还提到了一些额外的关键词和短语,如“电子设计自动化”、“机器学习”以及“神经网络”,这些关键词反映了文章的核心关注点。整体而言,这篇综述论文不仅梳理了ML在EDA中的历史进展,还展望了未来可能的发展趋势和面临的挑战,为研究人员和工程师提供了宝贵的参考资源。
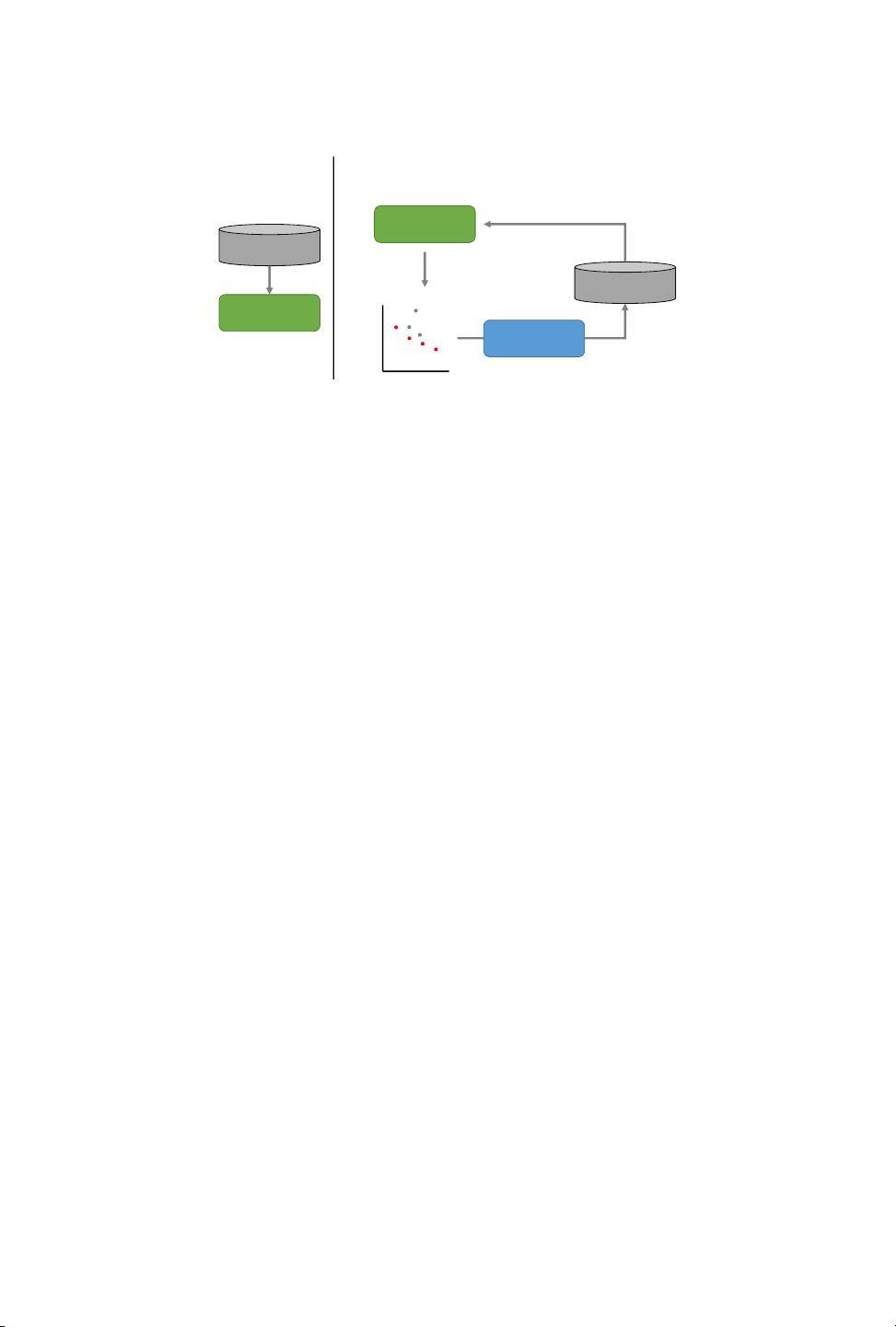
x:8 G. Huang et al.
Initial Training
Initial Samples
ML Predictor
training
Active Learning
ML Predictor
Predicting results
for all design points
Refinement
samples
training
Explorer /
Sampler
Fig. 4. The iterative-refinement DSE framework (reproduced from [93]).
Pareto Frontier Curve, on which every point is not fully dominated by any other points under all
the metrics.
Classical search algorithms have been applied in HLS DSE, such as Simulated Annealing (SA) and
Genetic Algorithm (GA). But these algorithms are unable to learn from the database of previously
explored designs. Many previous studies use an ML predictive model to guide the DSE. The models
are trained on the synthesis results of explored design points, and used to predict the quality of
new designs (See more discussions on this active learning workow in Section 9.1). Typical studies
are elaborated in Section 3.2.1. There is also a thread of work that involves learning-based methods
to improve the inecient or sensitive part of the classical search algorithms, as elaborated in
Section 3.2.2. Some work included in this subsection focuses on system-level DSE rather than HLS
design [74], or general active learning theories [177].
3.2.1 Active Learning. The four papers visited in this part utilize the active learning approach to
perform DSE for HLS, and use predictive ML models to surrogate actual synthesis when evaluating
a design. Liu and Schäfer
[92]
propose a design space explorer which selects new designs to
implement through an active learning approach. Transductive Experimental Design (TED) [
93
]
focuses on seeking the samples that describes the design space accurately. Pareto Active learning
(PAL) [
177
] proposed an active learning algorithm that samples the design which the learner
cannot clearly classify. Instead of focusing on how accurately the model describes the design space,
Adaptive Threshold Non-Pareto Elimination (ATNE) [
109
] estimates the inaccuracy of the learner
and achieves better performance than TED and PAL.
Liu and Schäfer
[92]
propose a dedicated explorer to search for Pareto-optimal HLS designs for
FPGAs. The explorer iteratively selects potential Pareto-optimal designs to synthesize and verify.
The selection is based on a set of important features, which are adjusted during the exploration. The
proposed method runs 6.5
×
faster than an exhaustive search, and runs 3.0
×
faster than a restricted
search method but nds results with higher quality.
The basic idea of TED [
93
] is to select representative as well as the hard-to-predict samples from
the design space, instead of the random sample used in previous work. The target is to maximize
the accuracy of the predictive model with the fewest training samples. The authors formulate the
problem of nding the best sampling strategy as follows: TED assumes that the overall number
of knob settings is
𝑛
(
|K | = 𝑛
), from which we want to select a training set
˜
K
such that
|
˜
K| = 𝑚
.
Minimizing the prediction error
𝐻 (𝑘) −
˜
𝐻 (𝑘)
for all
𝑘 ∈ K
is equivalent to the following problem:
𝑚𝑎𝑥
˜
K
𝑇 [K
˜
K
𝑇
(
˜
K
˜
K
𝑇
+ 𝜇𝐼 )
−1
˜
KK
T
] 𝑠.𝑡 .
˜
K ⊂ K, |
˜
K| = 𝑚,
ACM Trans. Des. Autom. Electron. Syst., Vol. x, No. x, Article x. Publication date: January 0000.

剩余43页未读,继续阅读
2022-11-19 上传
2021-09-02 上传
2021-10-07 上传
2018-03-12 上传
2009-06-25 上传
2023-09-29 上传

syp_net
- 粉丝: 158
- 资源: 1187
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
