SinGAN:从单张图像学习生成模型
需积分: 5 72 浏览量
更新于2024-08-03
收藏 9.68MB PDF 举报
"SinGAN是一种深度学习模型,专为从单个自然图像中学习生成模型而设计。该模型由Tamar Rott Shaham等人提出,它能够捕捉图像内部的补丁分布,并生成高质量、多样化的样本,这些样本具有与原始图像相同的视觉内容。SinGAN采用多尺度对抗性训练策略,由一系列全卷积GAN构成的金字塔结构,每个GAN负责学习图像在不同尺度上的补丁分布,从而可以生成任意大小的新样本。"
在当前的计算机视觉和图像生成领域,SinGAN(Single Image GAN)是一个创新性的深度学习模型,它打破了传统的生成对抗网络(GANs)需要大量数据进行训练的限制。SinGAN的核心思想是通过单一的训练图像来学习图像的内在分布,然后生成与原始图像风格一致的新图像样本。
文献《SinGAN: Learning a Generative Model from a Single Natural Image》详细阐述了SinGAN的架构和训练过程。模型采用了一个自底向上的金字塔结构,每个层级对应一个全卷积的GAN,每个GAN专注于学习图像在特定尺度上的纹理和模式。这种分层学习方法使得模型能捕捉到从细节到全局的各种特征。
在训练过程中,SinGAN使用逐级对抗性损失函数,确保生成的图像在每个尺度上都与原始图像的局部统计特性相匹配。此外,模型还引入了随机采样策略,使生成的样本在保持原有风格的同时,能创造出新的对象配置和结构,增加了多样性。
SinGAN的应用范围广泛,包括图像修复、风格迁移、分辨率提升等。它可以用于恢复损坏或低质量的图像,或者将低分辨率图像转换为高分辨率。此外,SinGAN还可以用于创造艺术作品,例如,根据单张照片生成不同的艺术风格图像,或者对现有图像进行创意修改。
SinGAN是深度学习领域的一个重要突破,它提供了一种新的方法,能够在数据有限的情况下,有效地学习和生成逼真的图像。这对于那些难以获取大量训练数据的场景,如罕见事件的模拟或者对特定环境的虚拟再现,具有重要的实用价值。
RealFake
Effective
Patch Size
Mult-scale Patch
Discriminator
Mult-scale Patch
Generator
Training Progression
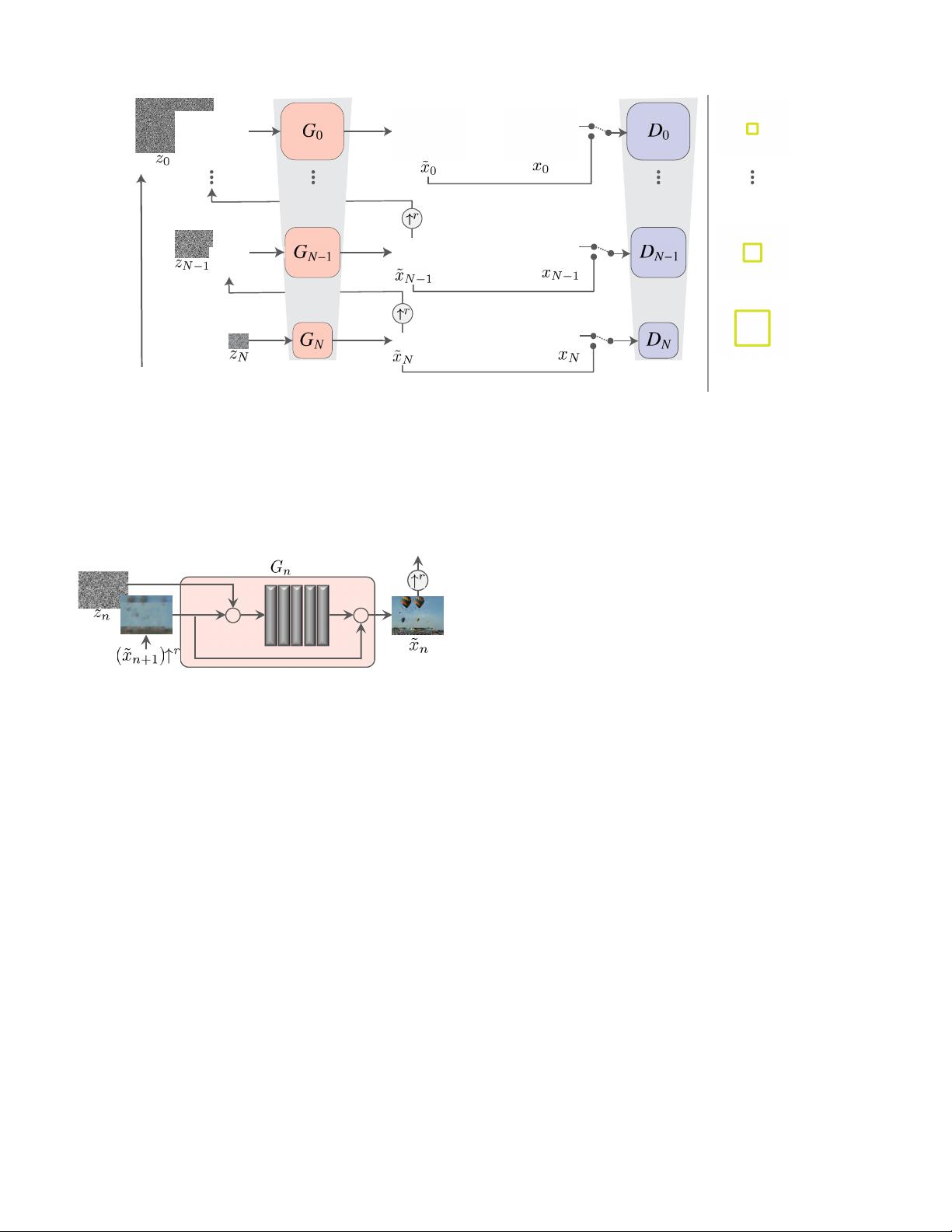
Figure 4: SinGAN’s multi-scale pipeline. Our model consists of a pyramid of GANs, where both training and inference are
done in a coarse-to-fine fashion. At each scale, G
n
learns to generate image samples in which all the overlapping patches
cannot be distinguished from the patches in the down-sampled training image, x
n
, by the discriminator D
n
; the effective
patch size decreases as we go up the pyramid (marked in yellow on the original image for illustration). The input to G
n
is a
random noise image z
n
, and the generated image from the previous scale ˜x
n
, upsampled to the current resolution (except for
the coarsest level which is purely generative). The generation process at level n involves all generators {G
N
. . . G
n
} and all
noise maps {z
N
, . . . , z
n
} up to this level. See more details at Sec. 2.
…
++
…
Figure 5: Single scale generation. At each scale n, the im-
age from the previous scale, ˜x
n+1
, is upsampled and added
to the input noise map, z
n
. The result is fed into 5 conv
layers, whose output is a residual image that is added back
to (˜x
n+1
) ↑
r
. This is the output ˜x
n
of G
n
.
sider a different source of training data – all the overlapping
patches at multiple scales of a single natural image. We
show that a powerful generative model can be learned from
this data, and can be used in a number of image manipula-
tion tasks.
2. Method
Our goal is to learn an unconditional generative model
that captures the internal statistics of a single training im-
age x. This task is conceptually similar to the conven-
tional GAN setting, except that here the training samples
are patches of a single image, rather than whole image sam-
ples from a database.
We opt to go beyond texture generation, and to deal
with more general natural images. This requires capturing
the statistics of complex image structures at many different
scales. For example, we want to capture global properties
such as the arrangement and shape of large objects in the
image (e.g. sky at the top, ground at the bottom), as well
as fine details and texture information. To achieve that, our
generative framework, illustrated in Fig. 4, consists of a hi-
erarchy of patch-GANs (Markovian discriminator) [31, 26],
where each is responsible for capturing the patch distribu-
tion at a different scale of x. The GANs have small recep-
tive fields and limited capacity, preventing them from mem-
orizing the single image. While similar multi-scale archi-
tectures have been explored in conventional GAN settings
(e.g. [28, 52, 29, 52, 13, 24]), we are the first explore it for
internal learning from a single image.
2.1. Multi-scale architecture
Our model consists of a pyramid of generators,
{G
0
, . . . , G
N
}, trained against an image pyramid of x:
{x
0
, . . . , x
N
}, where x
n
is a downsampled version of x by
a factor r
n
, for some r > 1. Each generator G
n
is responsi-
ble of producing realistic image samples w.r.t. the patch dis-
tribution in the corresponding image x
n
. This is achieved
through adversarial training, where G
n
learns to fool an as-
sociated discriminator D
n
, which attempts to distinguish
patches in the generated samples from patches in x
n
.
The generation of an image sample starts at the coarsest
scale and sequentially passes through all generators up to
the finest scale, with noise injected at every scale. All the
generators and discriminators have the same receptive field
and thus capture structures of decreasing size as we go up
the generation process. At the coarsest scale, the generation
is purely generative, i.e. G
N
maps spatial white Gaussian
noise z
N
to an image sample ˜x
N
,
4571
Authorized licensed use limited to: GUILIN UNIVERSITY OF ELECTRONIC TECHNOLOGY. Downloaded on March 21,2023 at 05:32:04 UTC from IEEE Xplore. Restrictions apply.
剩余10页未读,继续阅读
2024-03-09 上传
2022-02-05 上传
2023-04-05 上传
2023-04-05 上传
2023-04-06 上传
2023-02-22 上传
2023-08-15 上传
2023-02-06 上传
2024-04-18 上传

m0_46285064
- 粉丝: 47
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- Postman安装与功能详解:适用于API测试与HTTP请求
- Dart打造简易Web服务器教程:simple-server-dart
- FFmpeg 4.4 快速搭建与环境变量配置教程
- 牛顿井在围棋中的应用:利用牛顿多项式求根技术
- SpringBoot结合MySQL实现MQTT消息持久化教程
- C语言实现水仙花数输出方法详解
- Avatar_Utils库1.0.10版本发布,Python开发者必备工具
- Python爬虫实现漫画榜单数据处理与可视化分析
- 解压缩教材程序文件的正确方法
- 快速搭建Spring Boot Web项目实战指南
- Avatar Utils 1.8.1 工具包的安装与使用指南
- GatewayWorker扩展包压缩文件的下载与使用指南
- 实现饮食目标的开源Visual Basic编码程序
- 打造个性化O'RLY动物封面生成器
- Avatar_Utils库打包文件安装与使用指南
- Python端口扫描工具的设计与实现要点解析
