深度学习Python实战:手把手教你从入门到精通
需积分: 10 31 浏览量
更新于2024-07-20
1
收藏 5.85MB PDF 举报
"《Deep Learning with Python:A Hands-on Introduction》是尼基尔·凯特卡尔(Nikhil Ketkar)撰写的一本书,涵盖了深度学习的基础到进阶知识,包括了机器学习基础、前馈神经网络、Theano的介绍、卷积神经网络、循环神经网络、Keras的入门、随机梯度下降以及自动微分等内容。该书还涉及到GPU在深度学习中的应用,并提供了相关的源代码和补充材料。"
这本书深入浅出地引导读者进入深度学习的世界。在第一章“Introduction to Deep Learning”中,作者可能介绍了深度学习的基本概念,包括神经网络的架构、深度学习与传统机器学习的区别,以及深度学习在图像识别、自然语言处理等领域的重要应用。
第二章“Machine Learning Fundamentals”探讨了机器学习的基础,可能涵盖了监督学习、无监督学习、数据预处理、模型评估等关键概念,这是理解深度学习的基础。
第三章“Feed Forward Neural Networks”详细讲述了前馈神经网络(FFNN),包括其结构、训练过程和反向传播算法,这些都是构建深度学习模型的基础。
第四章“Introduction to Theano”则介绍了Theano这一深度学习框架,可能讨论了如何用Theano定义和优化计算图,以及其在多维数组处理和数学运算上的优势。
第五章“Convolutional Neural Networks (CNN)”专注于卷积神经网络,讲解了CNN在图像识别中的作用,如特征提取、池化操作以及卷积层和全连接层的工作原理。
第六章“Recurrent Neural Networks (RNN)”探讨了循环神经网络,重点在于它们在序列数据处理上的能力,如LSTM和GRU单元,以及它们在自然语言处理任务中的应用。
第七章“Introduction to Keras”介绍了Keras这一高级深度学习库,强调了其易用性、模块化设计以及与TensorFlow等底层库的集成。
第八章“Stochastic Gradient Descent (SGD)”讲述了随机梯度下降法,这是深度学习中常用的一种优化算法,用于更新网络权重以最小化损失函数。
第九章“Automatic Differentiation”深入了自动微分的概念,它是深度学习中计算梯度的关键,使得模型能够进行端到端的训练。
第十章“Introduction to GPUs”讨论了如何利用GPU加速深度学习计算,解释了GPU并行计算的优势和如何配置环境以利用GPU资源。
这本书是一本面向实践的深度学习指南,通过实际案例和代码示例,帮助读者掌握深度学习的核心技术和工具,特别是Keras框架的使用。对于希望入门或提升深度学习技能的人来说,这是一个非常有价值的资源。
CHAPTER 2 ■ MACHINE LEARNING FUNDAMENTALS
9
# Output
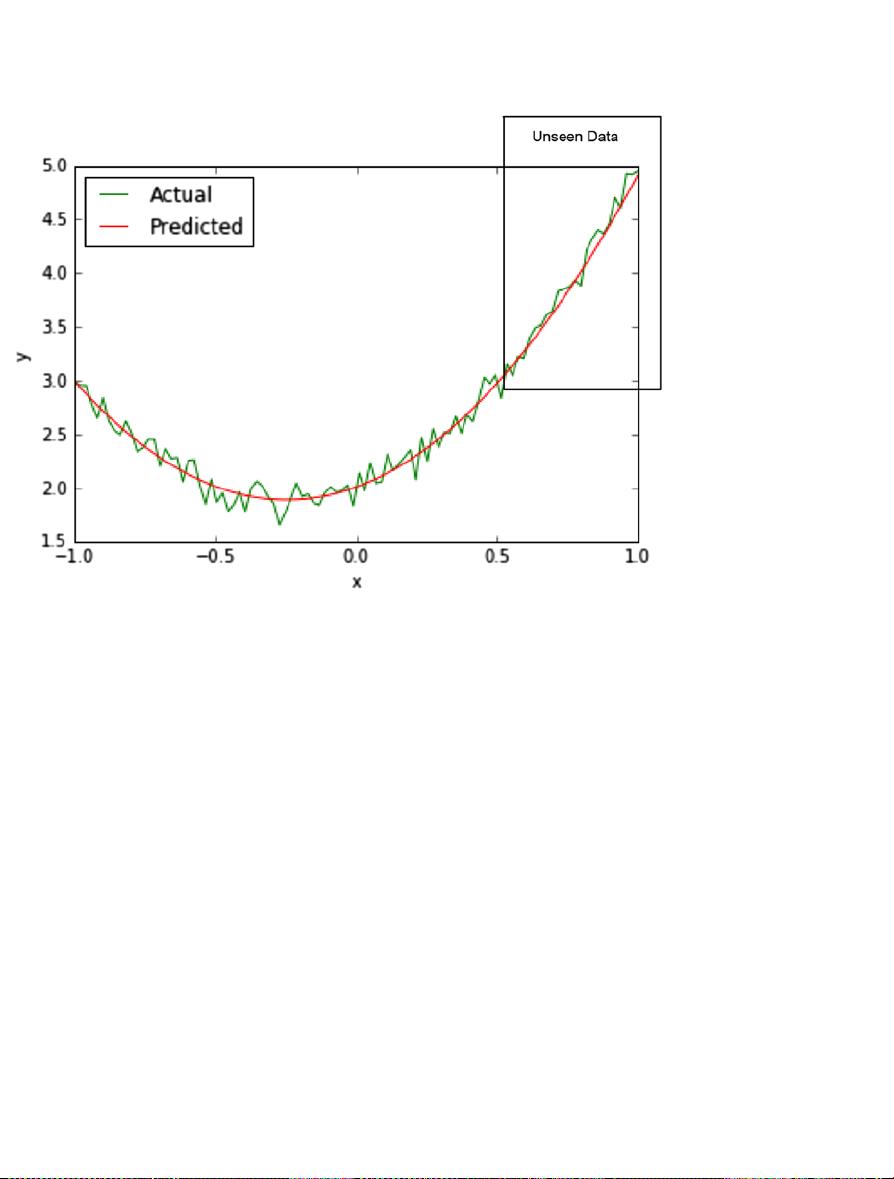
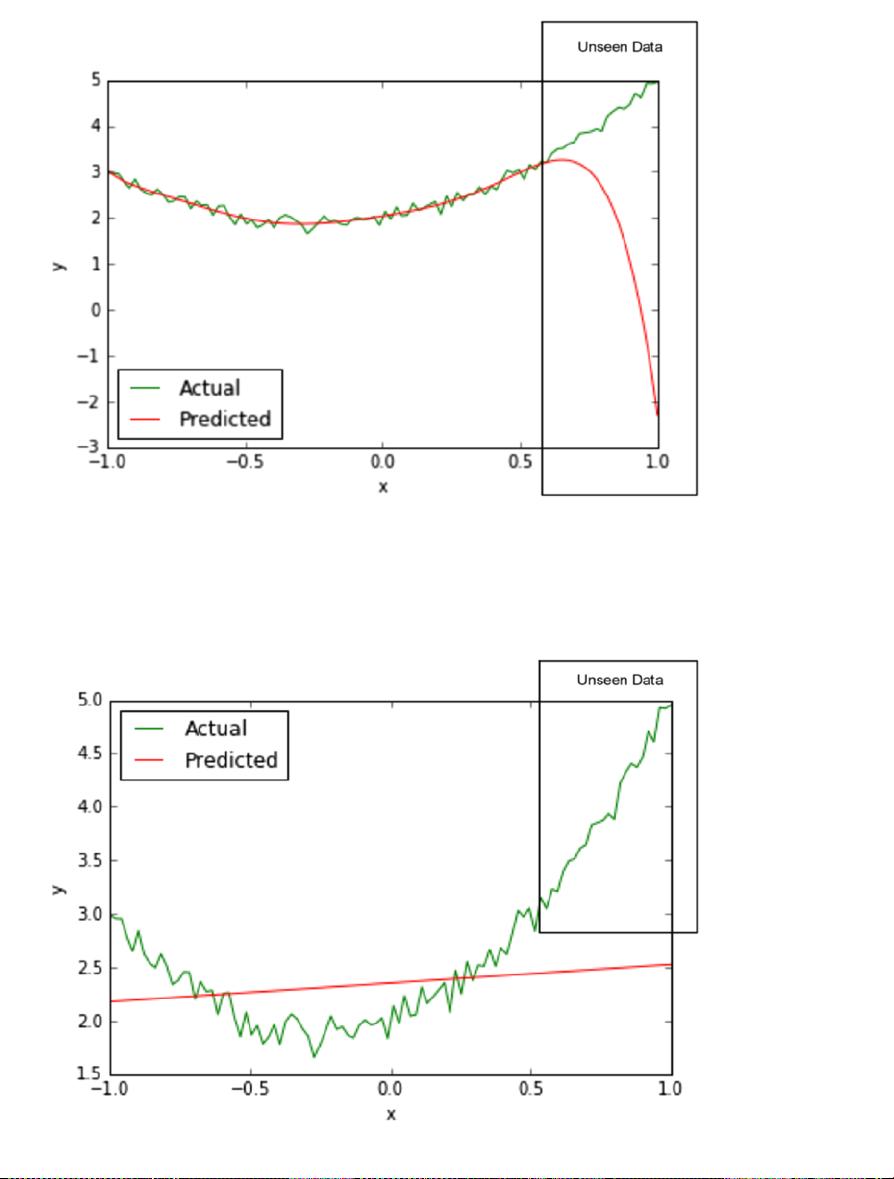
Train RMSE (Degree = 1) 3.50756834691
Test RMSE (Degree = 1) 7.69514326946
Train RMSE (Degree = 2) 0.91896252959
Test RMSE (Degree = 2) 0.446173435392
Train RMSE (Degree = 8) 0.897346255079
Test RMSE (Degree = 8) 14.1908525449
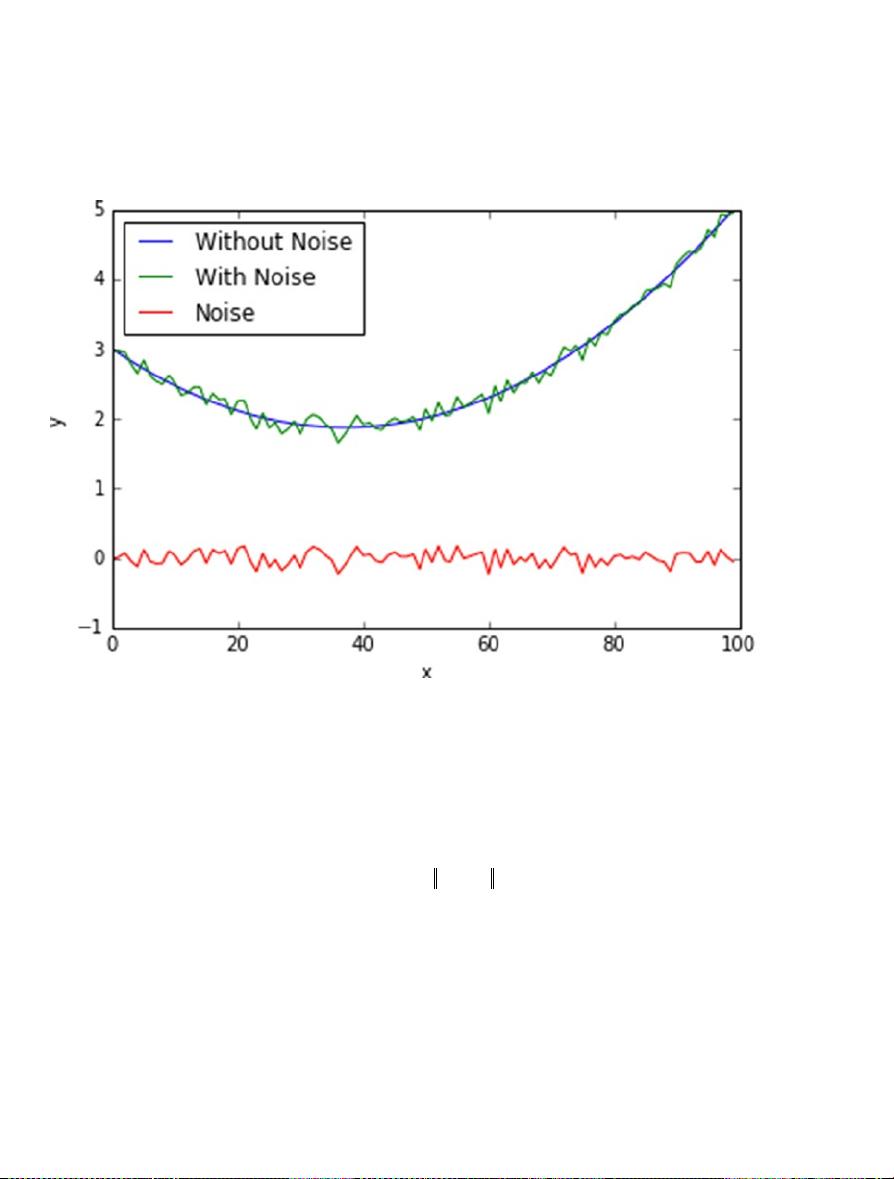
Figure 2-1. Generate a toy problem dataset for regression
In order to simulate seen and unseen data, we use the first 80 data points as seen data and the rest
we treat as unseen data. That is, we build the model using only the first 80 data points and use the rest for
evaluating the model.
Next, we use a very simple algorithm to generate a model, commonly referred to as Least Squares.
Given a data set of the form
Dxyxyxy
nn
=
()()
¼
()
{}
11 22
,, ,
,,
where
x
n
Î
and
y
Î
, the least squares model
takes the form y =
b
x where
b
is a vector such that
Xy
b
-
2
2
is minimized. Here X is a matrix where each row
is an x, thus
X
mn
Î
´
with m being the number of examples (in our case 80). The value of
b
can be derived
using the closed form
b
=
()
-
XX
Xy
TT
1
. We are glossing over a lot of important details of the least squares
method but those are secondary to the current discussion. The more pertinent detail is how we transform
the input variable to a suitable form. In our first model, we will transform x to be a vector of values [x
0
, x
1
,x
2
].
That is, if x = 2, it will be transformed to [1, 2, 4]. Post this transformation, we can generate a least squares
model
b
using the formula described above. What is happening under the hood is that we are approximating
the given data with a second order polynomial (degree = 2) equation, and the least squares algorithm is
simply curve fitting or generating the coefficients for each of [x
0
, x
1
,x
2
].


剩余163页未读,继续阅读
2998 浏览量
101 浏览量
2018-07-15 上传
2021-07-02 上传
2010-08-19 上传

吴_楚
- 粉丝: 1
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







