C3D与I3D行为识别模型对比:时空特征与Kinetics数据集
需积分: 39 188 浏览量
更新于2024-07-09
2
收藏 5.31MB PPT 举报
本资源是一份关于行为识别的深度学习模型C3D和I3D的比较分析PPT。该报告深入探讨了如何利用3D卷积神经网络(3D ConvNets)在视频行为识别领域的有效性,以及它们与传统2D模型的差异。
首先,报告的核心贡献指出C3D网络在时空特征提取方面的优秀性能,特别是3x3x3的卷积核在实验中表现出色。C3D模型即使通过简单的线性分类器也能达到较高的精度,这强调了其在保持计算效率的同时,能够捕获视频中的时空信息。
在介绍部分,作者强调了理想的视频描述子应具备良好的泛化性、紧凑性和计算效率。由于2D图像模型在缺乏运动建模的情况下难以适应视频,先前的研究者提出了3D ConvNets,但这些模型的成功往往依赖于大规模数据集的支持。C3D的创新之处在于其设计简洁,不依赖复杂的特征编码方法和分类器,仅通过简单的模型就能实现高效识别。
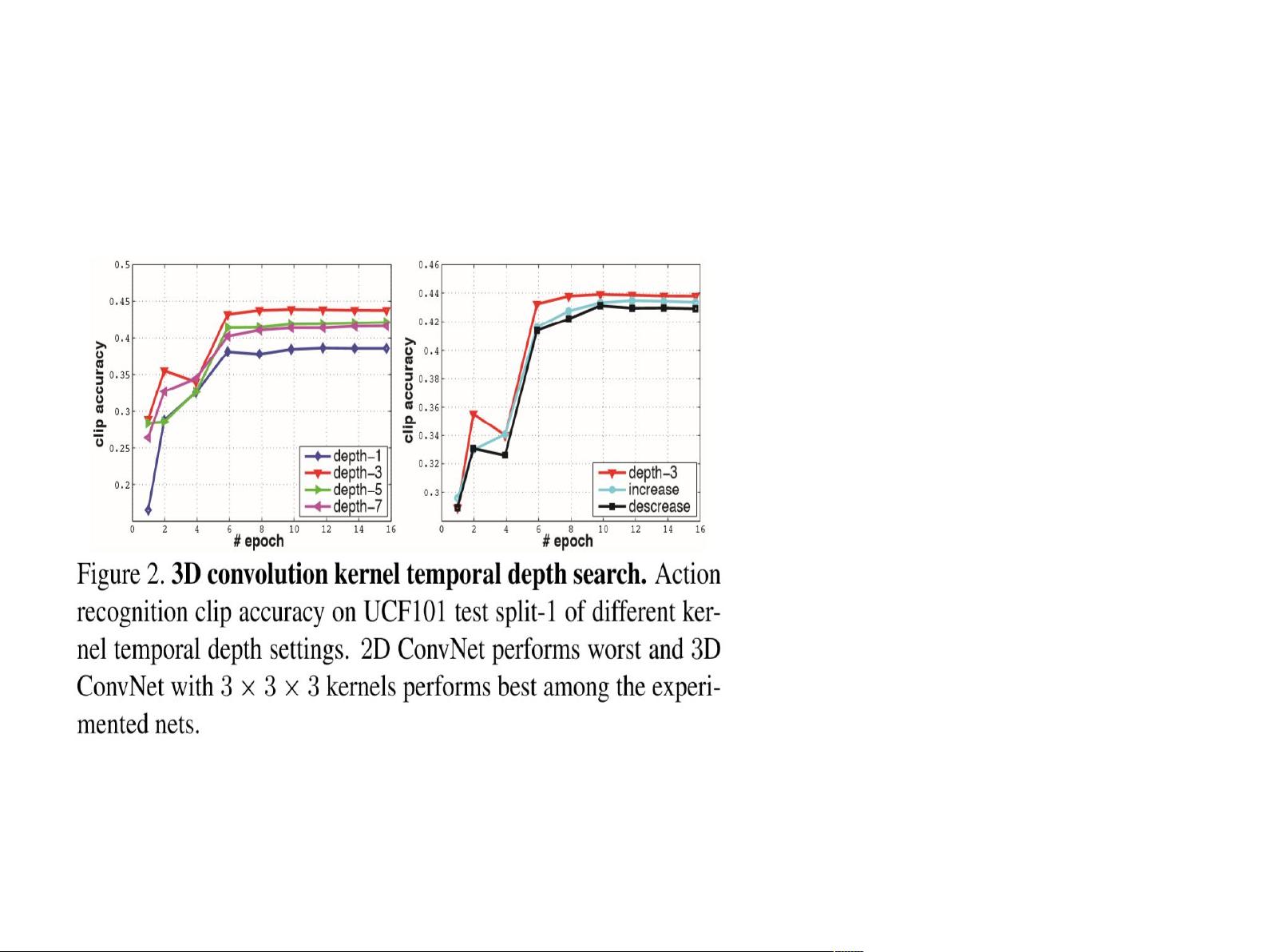
3D卷积是关键,它允许模型同时考虑空间和时间维度,解决了2D卷积在处理视频时丢失时间信息的问题。通过对比图示,作者解释了2D卷积和3D卷积的区别:2D卷积仅关注单帧,而3D卷积则形成一个三维体积,捕捉到视频序列的信息。研究还特别提到,基于2D ConvNet(如VGG网络)的经验,更深的3x3x3内核在3D卷积中效果最佳。
报告进一步讨论了两种不同架构:一是均匀时间深度,实验涉及不同帧数(如1、3、5、7帧),以探索最佳的时间跨度;二是变化的时间深度,即内核时间深度在不同网络层中动态调整,以适应不同视频段落的复杂性。
总结来说,这份PPT详细比较了C3D和I3D在行为识别中的优势,以及3D卷积技术如何通过优化网络结构和内核参数来提升性能。这对于理解深度学习在视频领域中的应用和优化策略具有重要意义。
6
3.2 时间深度
3. Learn Features with 3D
ConvNets
左图:均匀时间深度
Depth-3 最好
右图:变化的时间深度
Depth-3 最好
剩余27页未读,继续阅读
2021-05-13 上传
2024-10-27 上传
2024-10-27 上传
2024-10-27 上传
2023-09-14 上传
2023-05-26 上传
2023-09-01 上传

猫咪爱啤酒
- 粉丝: 1
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- mysql代码-table employees table salaries
- 天若OCR文字识别V4.48.zip
- merney
- video-game-web
- 在家工作
- Enc:惯用的编码,解码和散列方式
- MATLAB用拟合出的代码绘图-University-Projects:大学项目
- 华为EC6108V9A-RK3128-安卓4.4.4-卡刷固件包-当贝纯净桌面
- phaser-cli:创建没有构建配置的Phaser项目
- railz:“ Railz”团队周项目的前端
- QPNPED:使用排队 Petri 网评估数据库性能
- 1毫克
- dcr:绘制颜色重复-一种用于重复绘画和着色的小男孩编程语言
- jumpstart:干净的WordPress入门主题
- iconic-interview
- AdvancedCS-first-project:我的第一个Advanced CS项目
