Moore's Law与机器学习:MLIR编译器基础设施在CGO研讨会上的探讨
下载需积分: 50 | PDF格式 | 818KB |
更新于2024-07-09
| 62 浏览量 | 举报
"MLIR C4ML CGO Workshop Talk.pdf - MLIR Primer:一种针对摩尔定律终结的编译器基础设施"
在CGO 2019的机器学习编译器工作坊上,Chris Lattner和Jacques Pienaar介绍了MLIR(多层中间表示)这一新的编译器基础设施,它是应对摩尔定律逐渐失效挑战的一种解决方案。MLIR旨在为异构、分布式、移动设备以及定制ASICs等不同加速器提供一个抽象层。这一工作的目标是服务于TensorFlow社区,尤其是其广泛的编程APIs和对多种语言的支持。
TensorFlow作为一个开源项目,为不同的人提供了许多功能,包括编译器。其作为通用系统,需要支持张量问题的全范围,因此不能做出简化假设。这就提出了一个问题:既然已有LLVM和其他优秀的编译器基础设施,为什么还需要MLIR?
LLVM生态系统包含了Clang编译器、LLVM IR(中间表示)和Machine IR,以及用于C、C++、Objective-C、CUDA、OpenCL和汇编的AST(抽象语法树)。这些都是静态单一赋值形式的IR,具有不同的抽象层次。然而,它们在处理机器学习和张量运算时可能不够灵活,因为这些运算通常涉及大量的并行性和跨硬件平台的优化。
MLIR的设计理念在于提供一个多级别的中间表示,允许编译器在不同的抽象层次上进行优化,同时支持领域特定语言(DSL)的嵌入。这使得在编译过程中可以更早地进行高级优化,并且更容易地集成到现有编译流水线中。此外,MLIR的模块化设计允许为不同的硬件后端定制优化,适应硬件的特定特性和性能需求。
对于机器学习来说,MLIR提供了一个统一的框架,可以将模型的计算图表示与底层硬件的指令集紧密关联起来。这样,编译器就能更好地理解和优化深度学习模型的计算流程,从而提高运行效率和能耗比。在面临硬件性能提升速度放缓的背景下,MLIR这样的编译器基础设施对于实现高效、可移植的机器学习代码至关重要。
总结来说,MLIR是针对现代机器学习需求而设计的新型编译器基础设施,它弥补了传统编译器在处理复杂并行运算和跨平台优化上的不足,尤其适合处理与摩尔定律终结相关的挑战。通过提供多层次的中间表示,MLIR能够支持TensorFlow这样的系统更高效地利用各种硬件资源,从而推动机器学习领域的持续发展。
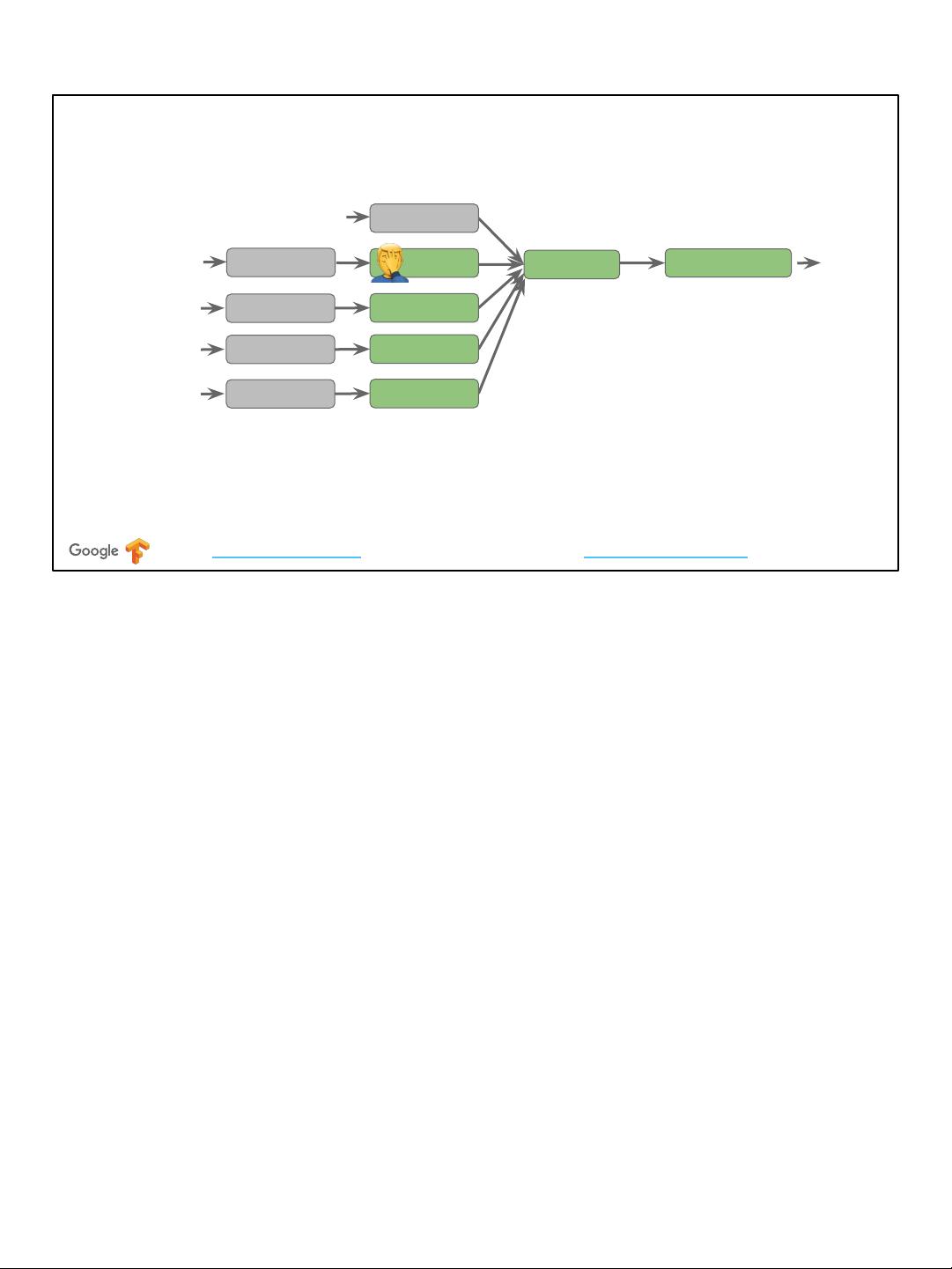
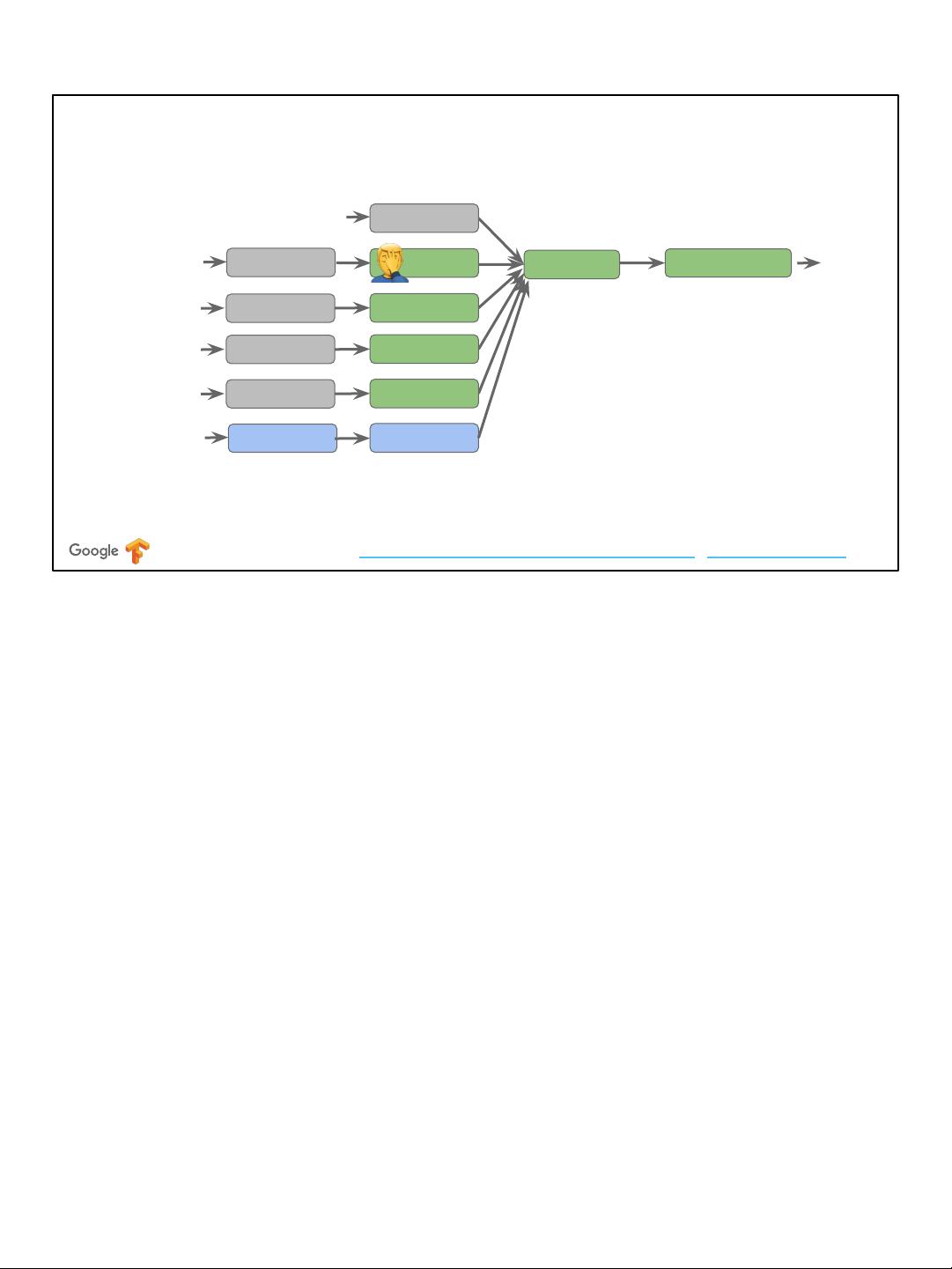
Rust and Julia have things similar to SIL
LLVM IR
Machine IR
Asm
Swift
Java & JVM
Languages
Java BC
SIL IR
Swift AST
Rust
MIR IR
Rust AST
Julia
Julia IR
Julia AST
“Introducing MIR”: Rust Language Blog, “Julia SSA-form IR”: Julia docs
● Dataflow driven type checking - e.g. borrow checker
● Domain specific optimizations, progressive lowering
Clang AST
C, C++, ObjC,
CUDA, OpenCL, ...
CIL IR
Swift isn’t alone here, many modern high level languages are doing the same thing.
剩余44页未读,继续阅读
相关推荐





cococoninini
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- BP神经网络在人脸识别中的应用与Matlab实现
- FF HSE基金会现场总线高速以太网通信研究及实现
- Springboot项目DemoOne:快速搭建与数据库实践指南
- 江海鹰Pspice课件精要解读
- 为Chrome扩展Easy Access-crx打造快捷网址
- 智能建筑办公楼解决方案详细介绍
- EtherCAT协议中文原版资料大全
- STM32-CAN-OBD解决方案与应用指南
- kubectl-check:高效检测Kubernetes资源状态插件
- ISO26262标准解读及翻译文档
- HTTPCore 4.4.5 版本压缩包内容及使用教程
- 9Cr2轧棍钢焊接工艺的详细操作指南
- 基于Tensorflow实现的128关键点人脸识别技术
- MacOS虚拟机模板制作指南及资源下载
- 《五夜弗雷迪》与NextJS开发教程
- STM32超声波成像技术资料解压缩











