深度学习入门:神经网络与实践
"《神经网络与深度学习》是一本深入浅出的深度学习入门书籍,由Michael Nielsen撰写,英文原版可在[1]网址获取。本书结合理论与实践,旨在帮助读者理解和掌握神经网络的基础概念和实际应用,特别是针对手写数字识别这一经典问题进行讲解。
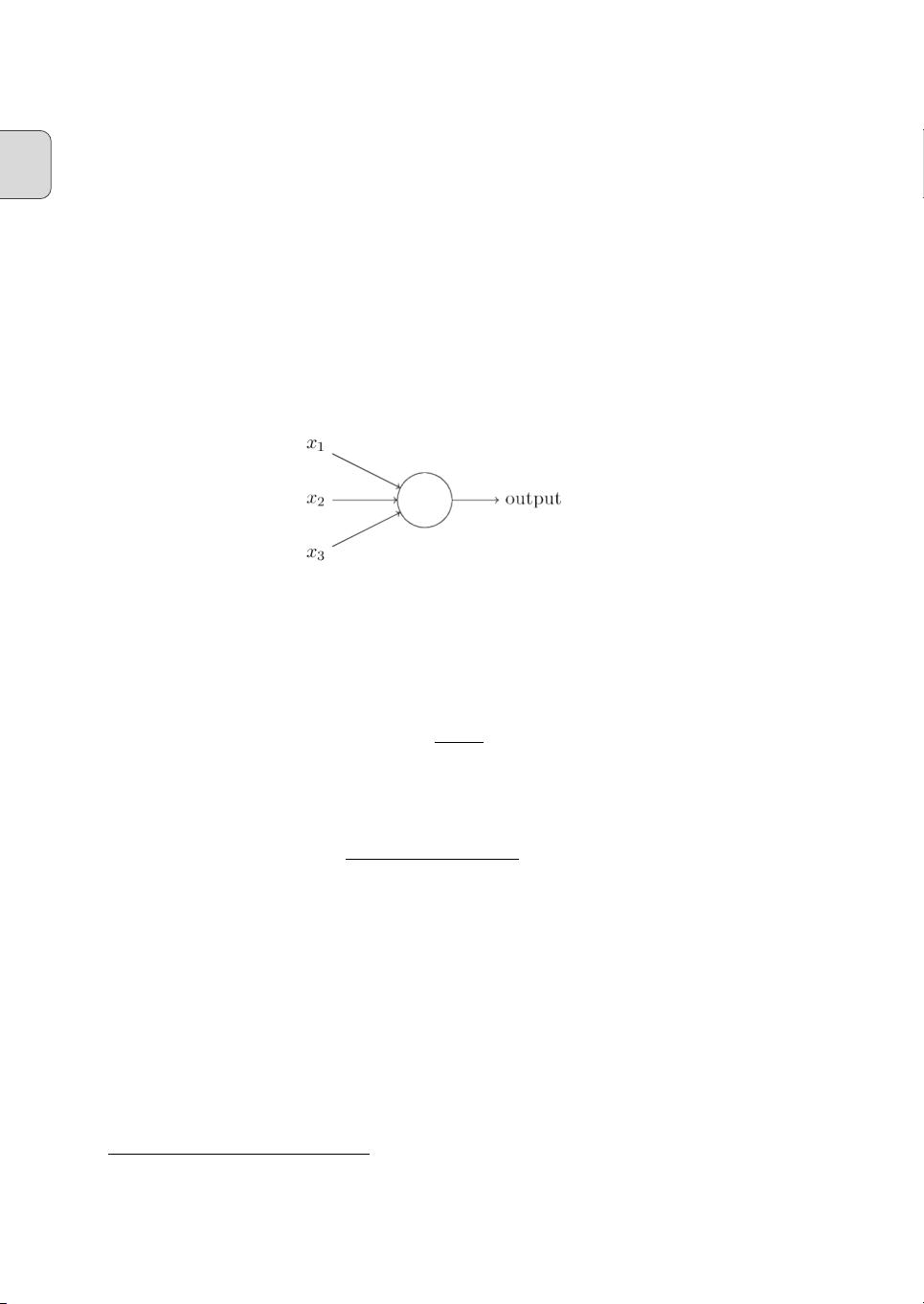
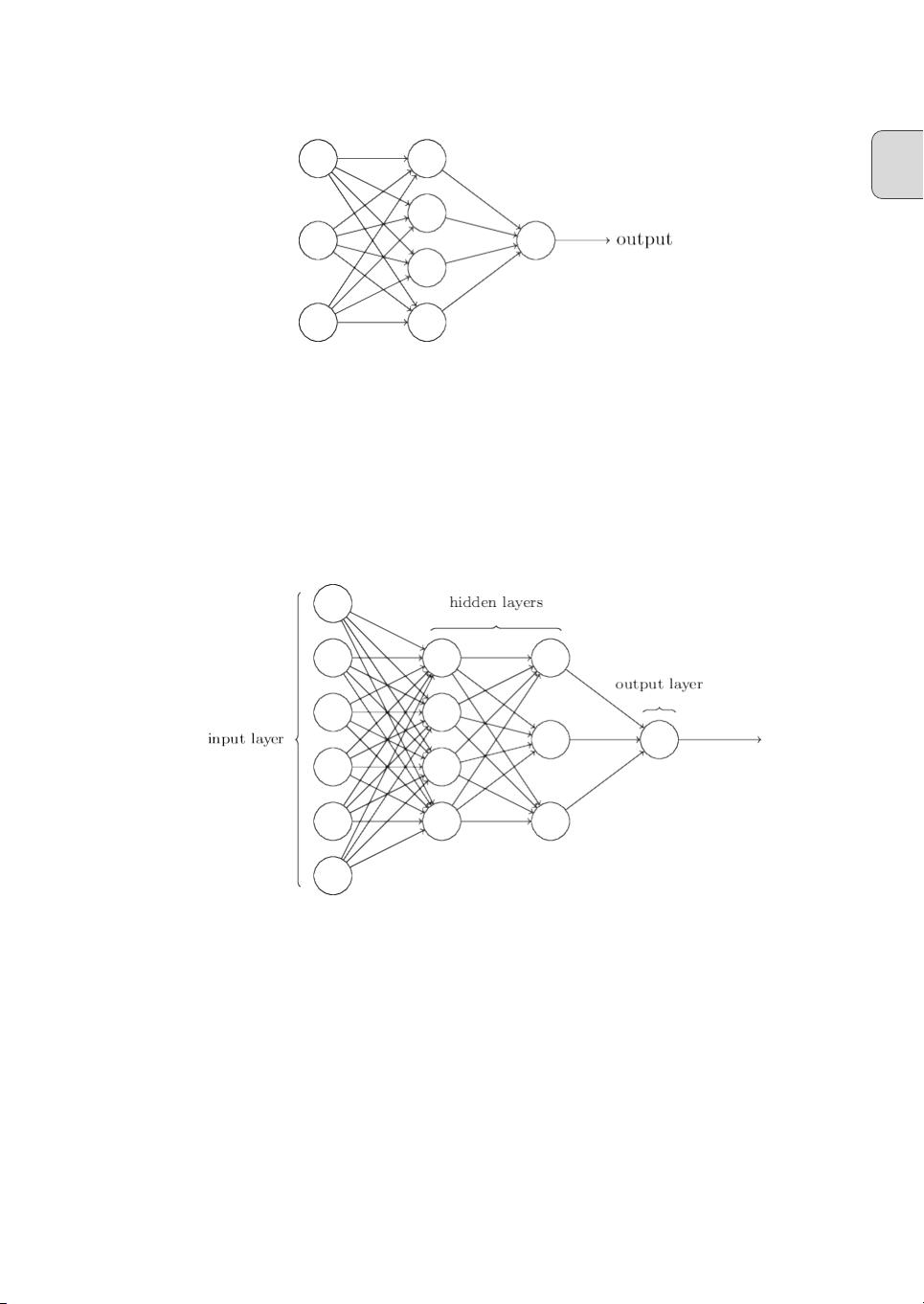
第1章介绍了如何使用神经网络来识别手写数字。首先,作者通过Perceptron模型(感知机)概述了基本的逻辑单元,然后引入了Sigmoid神经元,强调其在处理非线性问题上的优势。接着,书中详细讨论了神经网络的架构,包括多层网络设计,以及如何构建一个简单的网络来对MNIST数据集中的手写数字进行分类。学习过程的核心是梯度下降法,该方法展示了如何调整权重以最小化预测误差。
第2章着重于反向传播算法,这是训练深层神经网络的关键技术。作者首先用矩阵运算演示了一个简化的神经网络输出计算,然后揭示了成本函数的两个关键假设。Hadamard乘法在此过程中扮演重要角色,推动理解四条基础方程。这部分还提供了这些方程的证明,并给出了完整的反向传播算法步骤,以及为何它被视为一种高效的计算策略。此外,作者还探讨了反向传播的大局观,即它如何在整个网络中传递误差信号。
第3章聚焦于改进神经网络的学习方式。这里涉及了如何优化网络结构、正则化方法、以及防止过拟合的策略。作者可能会介绍不同类型的损失函数,如交叉熵损失,以及批量归一化和Dropout等常用技术,以提升模型性能和泛化能力。
《神经网络与深度学习》提供了一个循序渐进的学习路径,从基础知识到核心算法,再到实践技巧,让读者逐步建立起深度学习的基础,并能够在实践中构建和优化自己的神经网络模型。无论是对于初学者还是希望深入了解深度学习的工程师,这本书都是一份宝贵的资源。"
8
Using neural nets to recognize handwritten digits
very complicated way. So while your “9” might now be classified correctly, the behaviour of
the network on all the other images is likely to have completely changed in some hard-to-
control way. That makes it difficult to see how to gradually modify the weights and biases so
that the network gets closer to the desired behaviour. Perhaps there’s some clever way of
getting around this problem. But it’s not immediately obvious how we can get a network of
perceptrons to learn.
We can overcome this problem by introducing a new type of artificial neuron called a
sigmoid neuron. Sigmoid neurons are similar to perceptrons, but modified so that small
changes in their weights and bias cause only a small change in their output. That’s the crucial
fact which will allow a network of sigmoid neurons to learn.
Okay, let me describe the sigmoid neuron. We’ll depict sigmoid neurons in the same way
we depicted perceptrons:
Just like a perceptron, the sigmoid neuron has inputs,
x
1
, x
2
,...
. But instead of being just 0
or 1, these inputs can also take on any values between 0 and 1. So, for instance, 0
.
638
...
is a
valid input for a sigmoid neuron. Also just like a perceptron, the sigmoid neuron has weights
for each input,
w
1
, w
2
,...
, and an overall bias,
b
. But the output is not 0 or 1. Instead, it’s
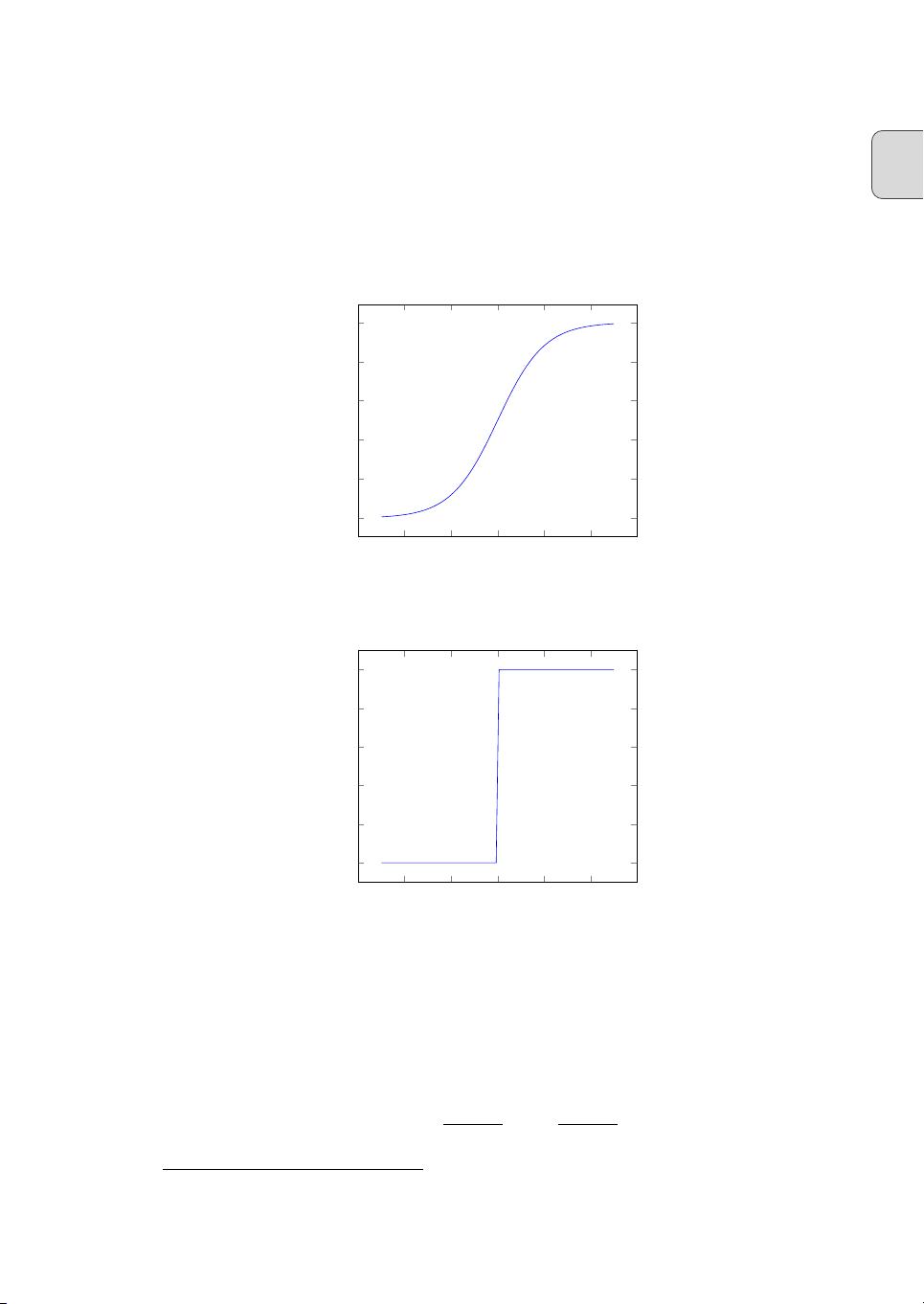
σ(wx + b), where σ is called the sigmoid function
1
, and is defined by:
σ(z) ≡
1
1 + e
−z
. (1.3)
To put it all a little more explicitly, the output of a sigmoid neuron with inputs
x
1
,
x
2
,
...
,
weights w
1
, w
2
,..., and bias b is
1
1 + exp
−
P
j
w
j
x
j
− b
. (1.4)
At first sight, sigmoid neurons appear very different to perceptrons. The algebraic form of
the sigmoid function may seem opaque and forbidding if you’re not already familiar with
it. In fact, there are many similarities between perceptrons and sigmoid neurons, and the
algebraic form of the sigmoid function turns out to be more of a technical detail than a true
barrier to understanding.
To understand the similarity to the perceptron model, suppose
z ≡ w · x
+
b
is a large
positive number. Then
e
−z
≈
0 and so
σ
(
z
)
≈
1. In other words, when
z
=
w · x
+
b
is large
and positive, the output from the sigmoid neuron is approximately 1, just as it would have
been for a perceptron. Suppose on the other hand that
z
=
w · x
+
b
is very negative. Then
e
−z
→ ∞
, and
σ
(
z
)
≈
0. So when
z
=
w · x
+
b
is very negative, the behaviour of a sigmoid
1
Incidentally,
σ
is sometimes called the logistic function, and this new class of neurons called logistic
neurons. It’s useful to remember this terminology, since these terms are used by many people working
with neural nets. However, we’ll stick with the sigmoid terminology.
1


剩余223页未读,继续阅读
相关推荐




四道眉毛
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 四轴飞行器飞控系统stm32f103与mpu9250综合应用
- 物流采购领域的可行性分析深度解析
- React Redux Boilerplate:ES6及Material-UI应用模板
- nRF52832平台成功移植RT-THREAD基础功能案例
- 一步到位:如何在谷歌浏览器安装react-devtools扩展
- 易语言荣获2005年大赛三等奖的MYSQL数据库管理器
- 三菱FX系列PLC与VB通讯程序详解
- STM32-F系列单片机输入捕获实验详解
- PyFunctional库:Python中创建数据管道的链函数编程库
- 掌握Microsoft Kinect for Windows SDK 2.0的源代码解析
- XX电器供应商管理与辅导规范文件下载
- layui轻量级后台管理系统模板:企业与个人网站开发首选
- 使用AVL BOOST模拟发动机性能与热力学过程
- C语言课程设计项目源码合集
- STM32-F0/F1/F2移植UC/OS-II教程与工具包
- HullTrend_HTF_Signal MetaTrader 5脚本:趋势方向与信号分析
