理解LSA与PLSA:模型解析与应用
需积分: 10 112 浏览量
更新于2024-09-16
收藏 254KB DOC 举报
"PLSA和LSA的调研"
在信息检索和自然语言处理领域,PLSA(概率潜在语义分析)和LSA(潜在语义分析)是两种重要的技术,它们都致力于理解和揭示文本数据中的隐藏语义结构。本文主要探讨了这两种方法的基本概念、特点和应用。
一、LSA(潜在语义分析)
LSA是一种统计方法,由S.T. Dumais等人在1988年提出,其目标是通过分析大量文本,找出词与词之间的潜在语义关系,以消除词汇的相关性,降低文本向量的维度。LSA的核心在于奇异值分解(SVD),它将高维的词-文档矩阵转换为低维的潜在语义空间。在这个空间中,词和文档的表示更能反映它们的语义相似性,而不是简单的词汇共现。LSA的应用广泛,包括信息过滤、文档索引、视频检索、文本分类与聚类、图像检索和信息抽取等。
二、LSA的工作原理
LSA的基本步骤包括:
1. 创建词-文档矩阵,记录每个文档中每个词的频率。
2. 对该矩阵进行奇异值分解(SVD),分解成三个矩阵的乘积:U * Σ * V^T。
3. 保留最大的K个奇异值,形成一个低秩近似,以降低维度。
4. 重构矩阵,获得文档在低维空间的表示。
5. 分析重构后的矩阵,提取出低维语义特征,这些特征可以用来计算文档之间的相似度。
三、PLSA(概率潜在语义分析)
PLSA是LSA的一个概率解释,它引入了主题(topics)的概念,认为每个文档都是由多个主题混合生成的,而每个词的出现则与这些主题有关。在PLSA模型中,每个文档被视为由一系列隐藏主题的概率分布组合而成,每个主题又有一系列词的概率分布。PLSA的目标是通过最大似然估计找到这些隐藏的主题分布,以解释观察到的词频数据。与LSA不同,PLSA的优化通常采用EM(期望最大化)算法。
四、PLSA与LSA的区别
虽然两者都试图捕捉文本的潜在语义,但它们的出发点和方法有所不同:
1. LSA是基于线性代数的矩阵分解,而PLSA是基于概率模型。
2. LSA的输出是静态的低维空间,而PLSA可以提供主题的动态解释。
3. PLSA可以解释为什么某些词出现在特定文档中,而LSA则不能。
总结,PLSA和LSA都是强大的工具,用于挖掘文本数据的深层结构。LSA更侧重于降维和相似性计算,而PLSA则提供了对主题分布的洞察,有助于理解文本内容的生成过程。在实际应用中,选择使用哪种方法取决于具体任务的需求和数据的特性。
PLSA 模型和 LSA 模型调研
引言?
一.LSA 概念
潜 在 语 义 分 析 ( Latent Semantic Analysis ) 或 者 潜 在 语 义 索 引
(Latent Semantic Index),是 1988 年 S.T. Dumais 等人提出了一种新
的信息检索代数模型,是用于知识获取和展示的计算理论和方法,它使用统计
计算的方法对大量的文本集进行分析,从而提取出词与词之间潜在的语义结构,
并用这种潜在的语义结构,来表示词和文本,达到到达消除词之间的相关性和
简化文本向量并实现降维的目的。
LSA 通过对大量出自原有的语料库或高维度的“语义空间”的机读语言样本进
行处理,LSA 能对所使用词汇、词串做出表征。通过收集包含或不包含所给词
汇的词汇语境,得出一套共同的约束原则,从而可以在很大程度上确定词汇间
和词串间的相似度。
从 LSA 中得到的相似度依赖于数学分析,这种分析能够正确推断深层关系
(所以叫做潜在语义),同时还可以对于基于意义的判断和表征做出深层次预
测,与长期以来语言学家所使用的分析语言现象的表层临近原则相比,潜在语
言分析显示出明显优势。
潜在语义分析的基本思路观点是:把高维的向量空间模型(VSM)表示中的文
档映射到低维的潜在语义空间中。这个映射是通过对文档矩阵的奇异值分解
(SVD)来实现的。
LSA 的应用领域有:信息滤波、文档索引、视频检索、文本分类与聚类、
图像检索、信息抽取等。
二.LSA 的特点及原理
潜在语义分析通过奇异值分解,将文档在高维向量空间模型中的表示,投影
到低维的潜在语义空间中,有效地缩小了问题的规模。它生成的高维向量矩阵
适于对象间的匹配比较。它不仅是知识表述的工具,而且也是机器学习的一种
模型。
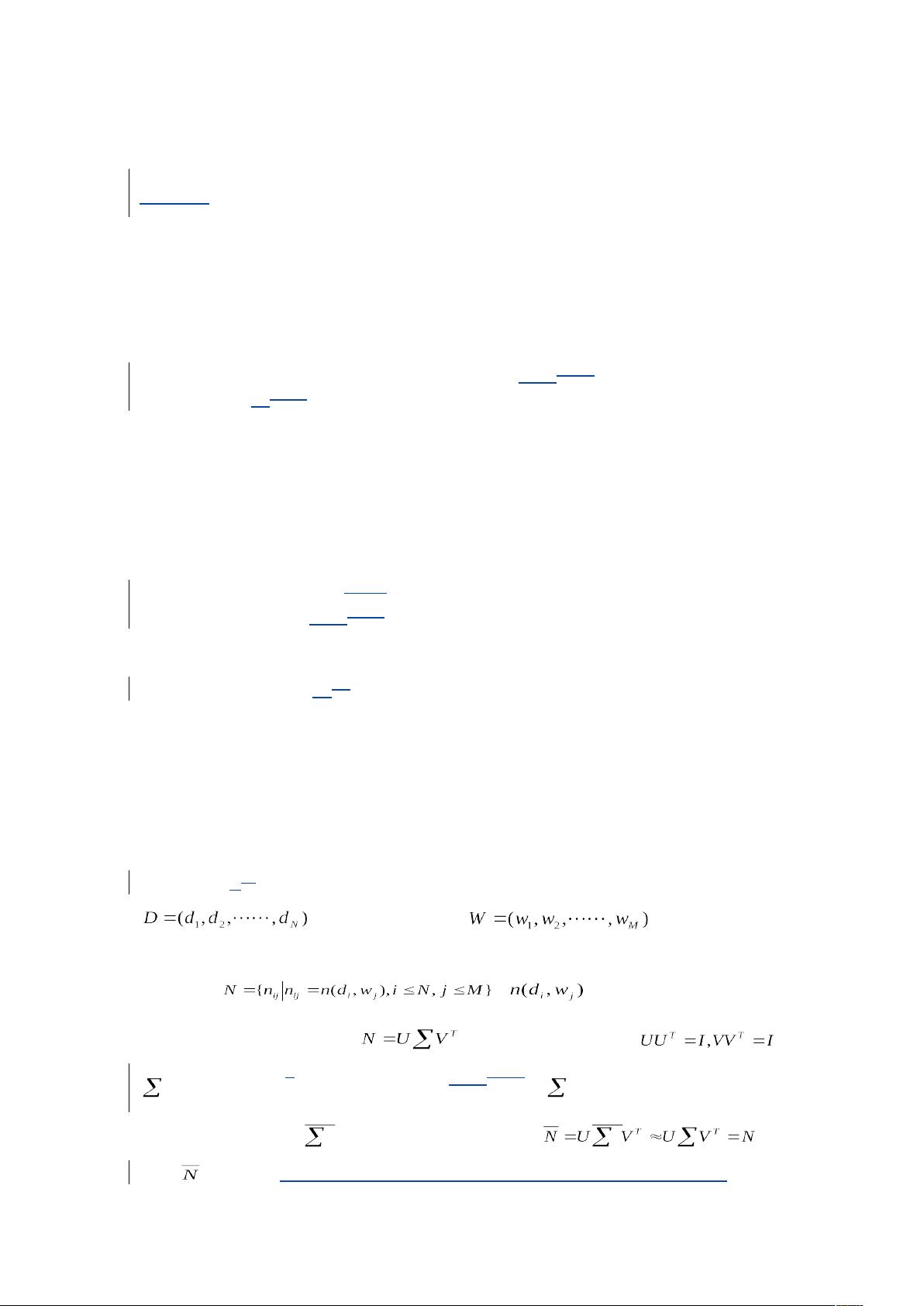
对 于 LSDA 原 理 可 以 描 述 如 下 : 首 先 对 给 定 文 档 (documents) 集 合
和词汇(words)集合 ,忽略词汇在文
档中出现的次序(bag of word 模型) 统计出词汇在文档中出现次数的矩阵,词-
文档矩阵 , 是词在文档中出现的次
数。其次对N做SVD分解 其中U,V是正交矩阵 ,
是由N的奇异z值组成的对角阵。然后再次将 中除最大的K个值以外的
全部值置为0,得到 ,再重构出矩阵N,即有 ,最
后对 进行分析(如何分析,如何得到低维语义特征,原理是什么?),得到
下载后可阅读完整内容,剩余8页未读,立即下载
279 浏览量
108 浏览量
2021-02-10 上传
174 浏览量
2021-09-11 上传
413 浏览量
322 浏览量

jihaifeng137211
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 易二维码签到系统:会议活动签到解决方案
- Ceres库与SDK集成指南:C++环境配置及测试程序
- 深入理解Servlet与JSP技术应用与源码分析
- 初学者指南:掌握VC摄像头抓图源代码实现
- Java实现头像剪裁与上传的camera.swf组件
- FileTime 2013汉化版:单文件修改文件时间的利器
- 波斯语话语项目:实现discourse-persian配置指南
- MP4视频文件数据恢复工具介绍
- 微信与支付宝支付功能封装工具类介绍
- 深入浅出HOOK编程技术与应用
- Jettison 1.0.1源码与Jar包免费下载
- JavaCSV.jar: 解析CSV文档的Java必备工具
- Django音乐网站项目开发指南
- 功能全面的FTP客户端软件FlashFXP_3.6.0.1240_SC发布
- 利用卷积神经网络在Torch 7中实现声学事件检测研究
- 精选网站设计公司官网模板推荐
