深度学习与小规模标签:从SGD到宽极小值
需积分: 5 30 浏览量
更新于2024-07-10
收藏 1.54MB PDF 举报
"小规模标签Chaudhari-SPIGL2020.pdf"
这篇文档主要探讨了在小规模标签数据集上进行机器学习,特别是针对深度学习中的几个关键概念和方法。作者Pratik Chaudhari提及了在有限的标注样本情况下如何训练模型,以及这种环境下的挑战和解决方案。
首先,学习小规模标签数据的核心问题在于,模型需要从少量的样例中捕获足够的信息来泛化到未见过的数据。传统的优化目标是找到最小化损失函数的参数,即:
$$\theta^* = \arg\min_{\theta} \frac{1}{N}\sum_{i=1}^{N} f_i(\theta)$$
在实践中,随机梯度下降(SGD)是解决这类问题的常用方法,它通过迭代更新参数来逼近最优解:
$$\theta_{t+1} = \theta_t - \eta \frac{1}{b}\sum_{k=1}^{b} \nabla f_{\omega_k}(\theta_t)$$
其中,$\theta_t$是当前的参数,$\eta$是学习率,$b$是批量大小,$\omega_k$是从训练集中随机选择的样本。
然而,SGD往往在深度网络中找到的是宽泛的局部最小值,这意味着模型可能对输入的微小变化过于敏感。为了改进这一点,文献提出了Local Entropy的概念,这是一种修改后的损失函数:
$$f_{\gamma}(\theta) = -\log \left(G_{\gamma}^* e^{-f(\theta)}\right)$$
Local Entropy旨在通过引入熵来鼓励模型学习更平滑的决策边界。
另外,文档还介绍了Parle,这是一个并行化的SGD方法,结合马尔可夫链蒙特卡洛(MCMC)与分布式更新,以实现 state-of-the-art 的性能。实验结果表明,Parle 在处理小规模标签数据时,如WRN-28-10在CIFAR-10上的表现,即使在较小的计算节点数下也能取得优于传统SGD的准确率。
该文档涉及了小样本学习、SGD优化、深度学习的局部最小问题以及利用并行化技术提高训练效率的策略。这些内容对于理解在AI、人工智能,特别是自然语言处理(NLP)领域中,如何高效地利用有限的标注数据进行模型训练具有重要价值。
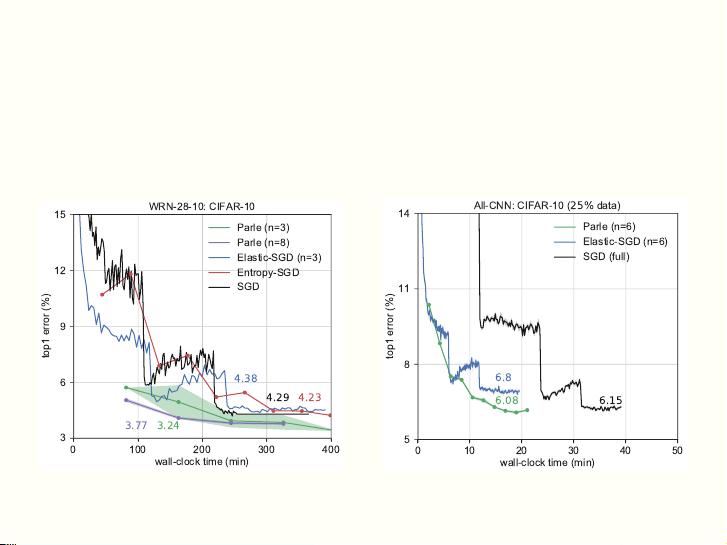
6
Parle: parallelizing stochastic gradient descent
Couple MCMC and distributed updates to get state-of-the-art
performance [Chaudhari et al., SysML18]
0 100 200 300 400
wall-clock time (min)
3
6
9
12
15
top1 error (
%
)
3.77 3.24
4.38
4.234.29
WRN-28-10: CIFAR-10
Parle (n=3)
Parle (n=8)
Elastic-SGD (n=3)
Entropy-SGD
SGD
0 10 20 30 40 50
wall-clock time (min)
5
8
11
14
top1 error (
%
)
6.08
6.8
6.15
All-CNN: CIFAR-10 (
25%
data)
Parle (n=6)
Elastic-SGD (n=6)
SGD (full)


剩余60页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-02-26 上传
2021-02-15 上传
2021-04-19 上传
2021-06-07 上传
点击了解资源详情
2024-11-28 上传

Jayxp
- 粉丝: 6
- 资源: 137
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
