DBSCAN聚类算法详解:无监督密度-based集群分析
需积分: 5 39 浏览量
更新于2024-06-30
收藏 1.02MB PDF 举报
"这篇文档是关于无监督学习中的DBSCAN(Density-Based Spatial Clustering of Applications with Noise)聚类算法在学生上网行为分析中的应用。DBSCAN是一种基于密度的聚类算法,无需预先设定簇的数量,能自动发现不同形状和大小的簇。"
DBSCAN全称为密度基空间聚类算法,它在处理大数据集时尤其有用,因为它能够有效地识别出高密度区域,并将其归类为簇,同时忽略低密度区域,将其视为噪声。这一特性使得DBSCAN在处理包含噪声和不规则形状簇的数据集时表现出色。
DBSCAN的核心概念包括两个参数:Eps(ε)和MinPts。Eps是一个距离阈值,定义了邻域的半径;MinPts是指一个点被认为是核心点所需的邻域内最少点的数量。具体来说:
1. **核心点**:如果一个点在其Eps半径内有至少MinPts个点(包括自身),那么这个点就被认为是核心点。这些点构成了簇的主体部分。
2. **边界点**:如果一个点的Eps邻域内的点少于MinPts,但至少有一个核心点的Eps邻域包含它,那么这个点就是边界点。它们位于簇的边缘。
3. **噪音点**:既不是核心点也不是边界点的点,通常被认为是数据的异常值或者孤立点。
DBSCAN的执行过程如下:
1. **初始化**:遍历数据集中的每一个点,根据Eps和MinPts判断其类型,标记为核心点、边界点或噪声点。
2. **删除噪声点**:在确定了噪声点之后,通常会从数据集中移除这些点,因为它们不参与簇的构建。
3. **构建图**:将所有核心点之间距离小于Eps的点连接起来,形成边。这一步创建了一个图结构,其中边代表邻接关系。
4. **形成簇**:找到所有连通的核心点集合,这些集合就构成了不同的簇。
5. **分配边界点**:将边界点分配给最近的核心点的簇,根据哪个核心点的邻域包含了这个边界点。
例如,一个包含13个样本点的数据集,在Eps=3和MinPts=3的情况下,DBSCAN会计算每个点的Eps邻域内的点数。如果点的邻域内点数超过3,该点被标记为核心点。然后,检查其余的点是否在任何核心点的Eps邻域内,如果是,则为边界点,否则为噪声点。接着,通过连接距离不超过3的所有核心点,形成三个簇。
DBSCAN的一个关键优势是它的灵活性和抗噪声能力,它可以处理任意形状的簇,而不仅仅是球形。此外,由于它不需要预设簇的数量,使得它在面对未知聚类结构的数据集时特别有用。然而,DBSCAN的性能受到Eps和MinPts选择的影响,合适的参数选择对于获得良好的聚类结果至关重要。在实际应用中,可能需要通过调整这两个参数来探索最佳的聚类效果。
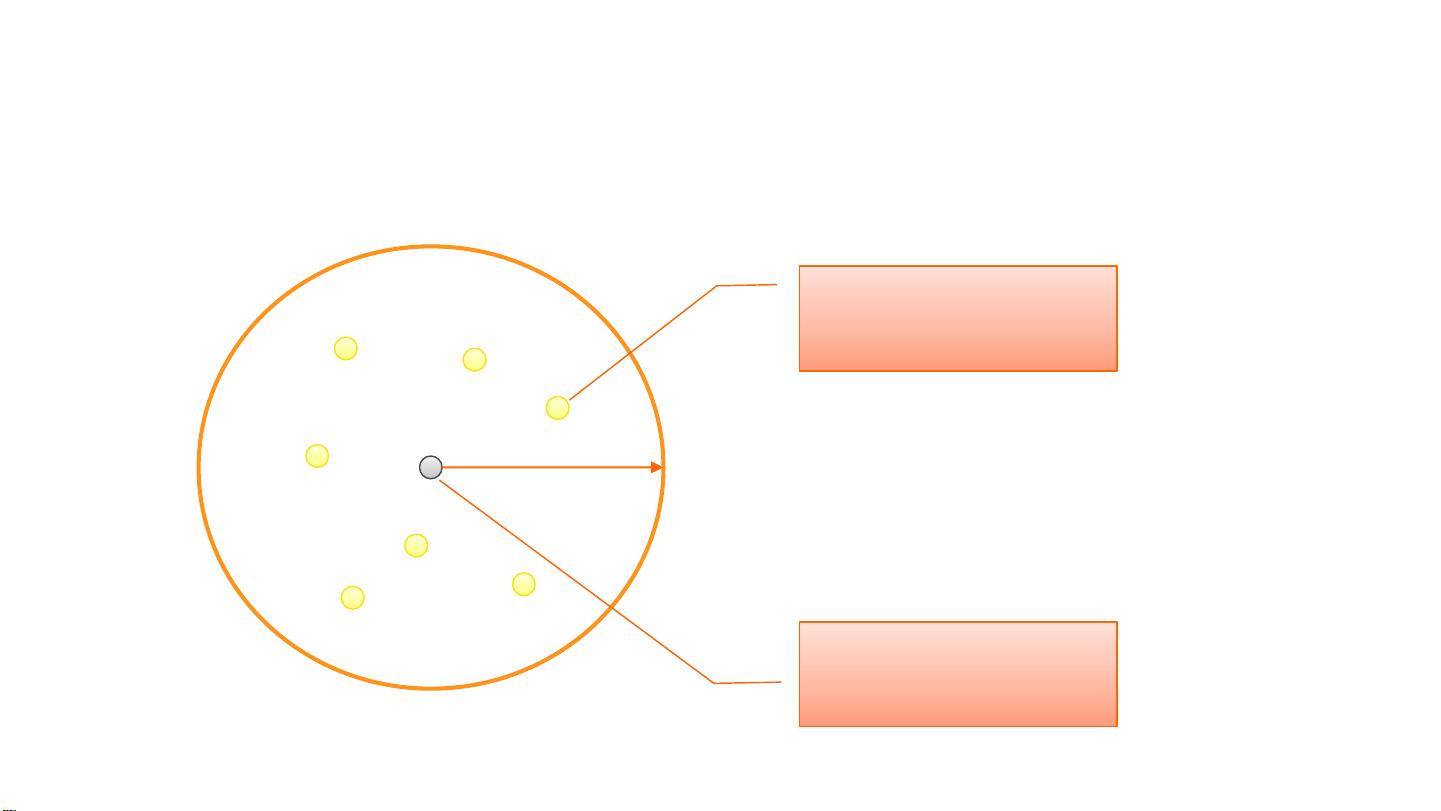
DBSCAN密度聚类
Eps
MinPts=5
边界点:若其邻域内
点不超过MinPts个
核心点:邻域内点的
个数超过MinPts
剩余20页未读,继续阅读
2021-03-21 上传
2022-09-22 上传
2022-07-15 上传
2023-07-01 上传
2023-07-01 上传

「已注销」
- 粉丝: 0
- 资源: 23
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
