Hadoop MapReduce源码解析
需积分: 10 83 浏览量
更新于2024-07-31
收藏 2.3MB DOC 举报
"Hadoop源码分析文档主要关注MapReduce部分,介绍了MapReduce的工作流程、输入输出处理、Mapper和Reducer的运作机制,以及Combiner的功能。"
Hadoop MapReduce是Google MapReduce模型的开源实现,它是大数据处理的核心组件之一,尤其在云计算环境中扮演着重要角色。Hadoop MapReduce的设计理念是将大规模数据处理分解为两个主要阶段:Map阶段和Reduce阶段,以便于并行化执行。
Map阶段是数据处理的初始步骤,用户提交的任务首先由JobTracker协调。在这个阶段,数据被切分成多个块(InputSplit),由RecordReader接口读取并转化为键值对(<k,v>)的形式。这些键值对随后由Mapper处理,Mapper是用户自定义的函数,用于对输入数据进行转换或计算。Mapper的输出通过OutputCollector收集,并由Partitioner决定哪些键值对会被发送到哪个Reducer。
Reduce阶段则负责聚合Map阶段产生的结果。TaskTracker监控Reduce任务的执行,这些任务在独立的Java虚拟机中运行。Reducer根据接收到的键值对进行聚合操作,通常用于汇总、统计或者聚合数据。在Reducer之前,用户还可以选择使用Combiner来优化性能,Combiner在本地(在同一台机器上)对Mapper的输出进行预处理和合并,减少网络传输的数据量。
InputFormat接口是Hadoop MapReduce处理输入数据的关键,它定义了如何从不同数据源(如文本文件、数据库等)读取数据并将其分割为适合处理的块。InputSplit接口用于表示数据的物理分割,而RecordReader接口则负责从InputSplit中提取逻辑记录,形成键值对供Map函数使用。
输出方面,OutputFormat接口定义了如何将Reduce阶段的结果写回到HDFS。这通常涉及到创建输出文件和定义键值对的序列化格式。
Hadoop MapReduce通过将复杂的大数据处理任务分解为可并行执行的Map和Reduce任务,实现了高效的分布式计算。源码分析可以帮助开发者深入理解其内部工作原理,从而更好地优化应用程序,提高处理效率。在实际应用中,理解MapReduce的工作流程、输入输出处理机制以及如何利用Combiner进行局部聚合,都是提升Hadoop性能的关键。
"'A:得到 @ 对应的 A,必须在调用 "'@ 后调用;
5:得到现在的进度;
,来自 &+ 的 . 接口,用于清理 。
我们以 LineRecordReader 为例,来分析 RecordReader 的构成。前面我们已经分析过 FileInputFormat 对文件的划分了,划分完的 Split 包括了文件
名,起始偏移量,划分的长度。由于文件是文本文件,LineRecordReader 的初始化方法 initialize 会创建一个基于行的读取对象 LineReader(定义
在 org.apache.hadoop.util 中,我们就不分析啦),然后跳过输入的最开始的部分(只在 Split 的起始偏移量不为 0 的情况下进行,这时最开始的部
分可能是上一个 Split 的最后一行的一部分)。nextKey 的处理很简单,它使用当前的偏移量作为 Key,nextValue 当然就是偏移量开始的那一行了
(如果行很长,可能出现截断)。进度 getProgress 和 close 都很简单。
0
Hadoop
源代码分析(包
mapreduce.lib.map )
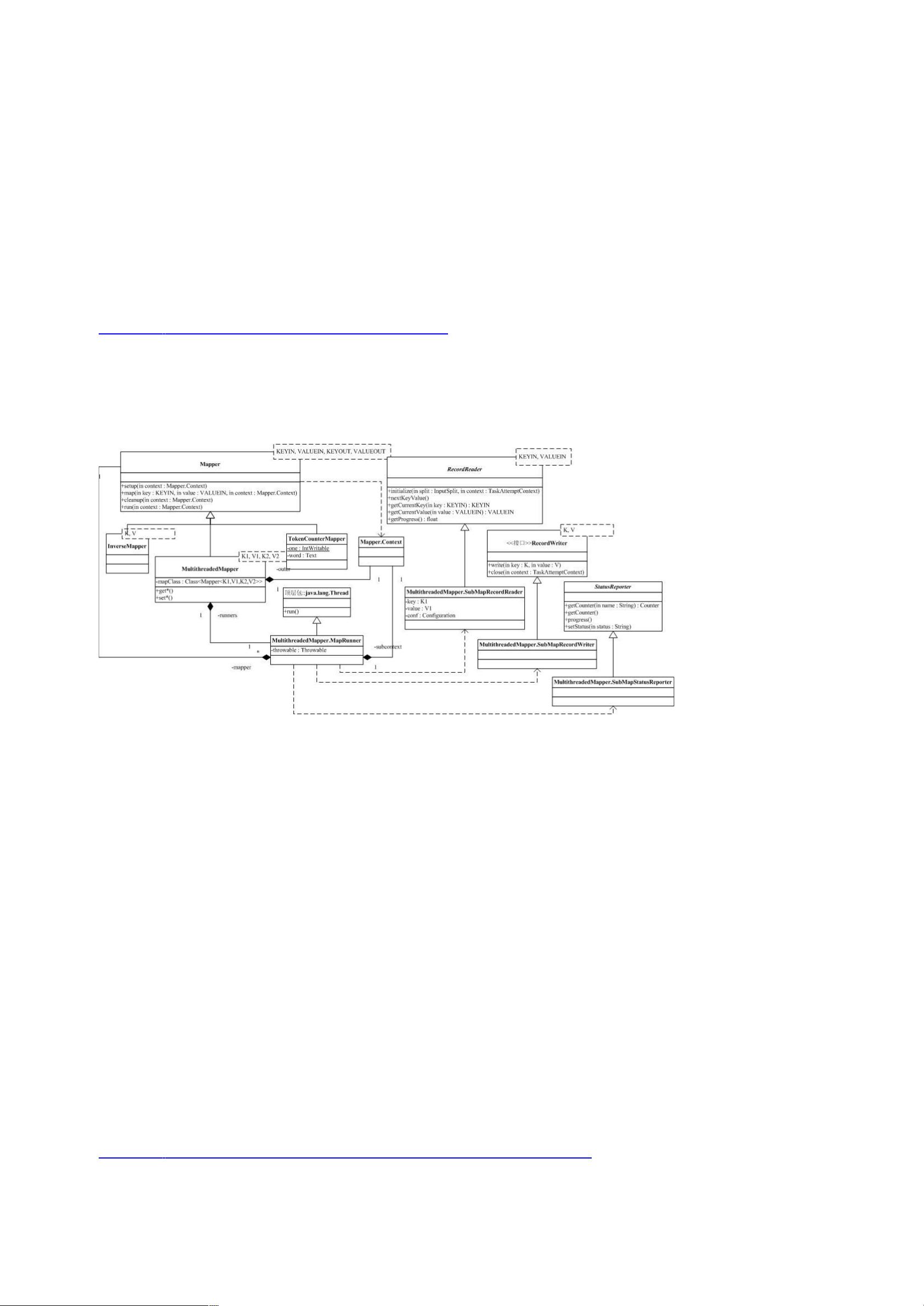
的 框架中, 动作通过 类来抽象。一般来说,我们会实现自己特殊的 ,并注册到
系统中,执行时,我们的 会被 框架调用。 类很简单,包括一个内部类和四个方法,静态结构
图如下:
#
内部类 ."' 继承自 ."',并没有引入任何新的方法。
的四个方法是 , ," 和 "。其中, 和 " 用于管理 生命周期中的资源,
在完成 构造,即将开始执行 动作前调用," 则在所有的 动作完成后被调用。方法 用
于对一次输入的 + 对进行 动作。" 方法执行了上面描述的过程,它调用 ,让后迭代所有的 +
对,进行 ,最后调用 "。
中实现了 的三个子类,分别是 ,"+(将输入12%
+3% 为输出1+2%3),(多线程执行 方法)和 )"."(对
输入的 + 分解为 " 并计数)。其中最复杂的是 ,我们就以它为例,来分析 的实现。
会启动多个线程执行另一个 的 方法,它会启动
""(配置项)个线程执行 :
""(配置项)。 重写了基类 的 " 方法,启动 F
个线程(对应的类为 "")执行 ""(我们称为目标 )的 " 方法
(就是说,目标 的 和 " 会被执行多次)。目标 共享同一份 ,",这就意味着,对
," 的数据读必须线程安全。为此, 引入了内部类
,;,,分别继承自
,; 和 ,它们通过互斥访问 的 ."',实
现了对同一份 ," 的线程安全访问,为 提供所需的 ."'。这些类的实现方法都很简单。
G
Hadoop
源代码分析( mapreduce.lib.partition/reduce/output )
的结果,会通过 " 分发到 上, 做完 操作后,通过 4 ,进行输出,下
面我们就来分析参与这个过程的类。
剩余22页未读,继续阅读
2023-06-27 上传
2021-09-06 上传
2020-01-19 上传
2020-04-06 上传
2019-10-26 上传
2021-12-06 上传

小廉飞镖
- 粉丝: 7
- 资源: 22
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
