Python分布式任务队列Celery深度解析
PDF格式 | 294KB |
更新于2024-09-01
| 110 浏览量 | 举报
"Python并行分布式框架Celery详解"
在Python编程中,为了处理高并发和大规模数据处理,开发者经常需要利用并行分布式框架。Celery就是这样一个强大的工具,它允许开发者在分布式环境中运行异步任务,提高应用的性能和响应速度。本文将深入探讨Celery的原理和使用方法。
首先,Celery是一个基于分布式消息传递的作业队列,它专注于实时任务处理,同时也具备出色的调度功能。它的核心设计理念是解耦任务的创建和执行,使得任务的发起者(生产者)与执行者(消费者)之间保持松散耦合。这种设计模式使得Celery适用于多种应用场景,如后台任务处理、批量数据计算等。
在Celery的架构中,一个关键组件是Broker(消息中间件)。Broker的作用是接收来自生产者的任务消息,并分发给等待执行任务的消费者(worker)。常见的Broker选项包括RabbitMQ、Redis、Beanstalk、MongoDB、CouchDB以及使用SQLAlchemy或Django ORM的数据库。选择合适的Broker对于Celery的性能和稳定性至关重要。
另一个关键组件是Backend,用于存储任务的执行结果。Backend通常与Broker一起工作,但其主要职责是保存任务的返回值,以便后续查询。Celery允许开发者选择不同的Backend,例如Redis、数据库等,以适应不同的需求。
Celery的设计使其能够很好地融入各种Python Web框架,如Django、Pylons和Flask。通过相应的插件(如django-celery、celery-pylons和Flask-Celery),开发者可以轻松地在这些框架中集成Celery,实现任务的异步处理。
在理解Celery之前,了解生产者消费者模式是很有帮助的。这种模式源自多线程理论,描述了一种数据处理模型。生产者负责生成数据,而消费者则消费这些数据。在Celery中,生产者是创建任务的应用,它们将任务发送到Broker;消费者则是Celery worker,它们从Broker获取任务并执行。这种模式确保了生产者与消费者之间的独立性,使得系统能够扩展以应对高负载。
在使用Celery时,开发者需要定义任务(task)并注册到Celery实例中。任务可以是任何可调用的对象,如函数或方法。任务的执行可以是同步的(立即返回结果)或异步的(返回一个未来结果的引用,结果会在后台计算)。Celery提供了丰富的API,可以进行任务的延迟执行、定时执行、结果跟踪等功能。
Celery是Python世界中的一个强大工具,它通过提供一个灵活的异步任务队列,使得开发者能够在分布式环境中有效地处理复杂的工作流。通过理解Celery的架构和工作原理,开发者可以更好地利用这一框架提升应用程序的效率和可扩展性。
Python并行分布式框架并行分布式框架Celery详解详解
今天小编就为大家分享一篇关于Python并行分布式框架Celery详解的文章,小编觉得内容挺不错的,现在分享给大家,具有很好
的参考价值,需要的朋友一起跟随小编来看看吧
Celery 简介简介
除了redis,还可以使用另外一个神器---Celery。Celery是一个异步任务的调度工具。
Celery 是 Distributed Task Queue,分布式任务队列,分布式决定了可以有多个 worker 的存在,队列表示其是异步操作,即存在一个产生任务
提出需求的工头,和一群等着被分配工作的码农。
在 Python 中定义 Celery 的时候,我们要引入 Broker,中文翻译过来就是“中间人”的意思,在这里 Broker 起到一个中间人的角色。在工头提出
任务的时候,把所有的任务放到 Broker 里面,在 Broker 的另外一头,一群码农等着取出一个个任务准备着手做。
这种模式注定了整个系统会是个开环系统,工头对于码农们把任务做的怎样是不知情的。所以我们要引入 Backend 来保存每次任务的结果。这
个 Backend 有点像我们的 Broker,也是存储任务的信息用的,只不过这里存的是那些任务的返回结果。我们可以选择只让错误执行的任务返回
结果到 Backend,这样我们取回结果,便可以知道有多少任务执行失败了。
Celery(芹菜)是一个异步任务队列/基于分布式消息传递的作业队列。它侧重于实时操作,但对调度支持也很好。Celery用于生产系统每天处理数
以百万计的任务。Celery是用Python编写的,但该协议可以在任何语言实现。它也可以与其他语言通过webhooks实现。Celery建议的消息队列
是RabbitMQ,但提供有限支持Redis, Beanstalk, MongoDB, CouchDB, 和数据库(使用SQLAlchemy的或Django的 ORM) 。
Celery是易于集成Django, Pylons and Flask,使用 django-celery, celery-pylons and Flask-Celery 附加包即可。
在学习Celery之前,我先简单的去了解了一下什么是生产者消费者模式。
生产者消费者模式生产者消费者模式
在实际的软件开发过程中,经常会碰到如下场景:某个模块负责产生数据,这些数据由另一个模块来负责处理(此处的模块是广义的,可以是
类、函数、线程、进程等)。产生数据的模块,就形象地称为生产者;而处理数据的模块,就称为消费者。
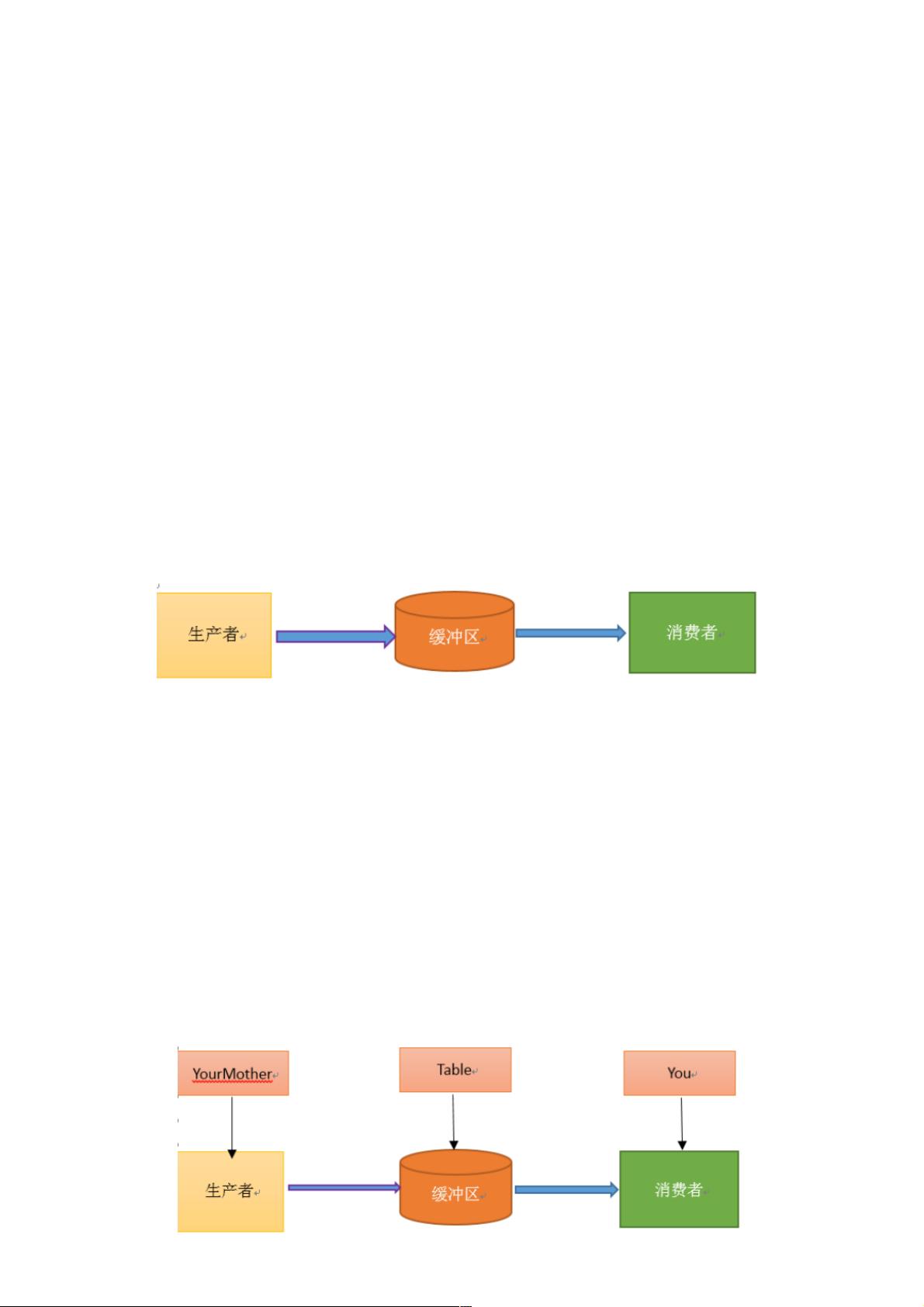
单单抽象出生产者和消费者,还够不上是生产者消费者模式。该模式还需要有一个缓冲区处于生产者和消费者之间,作为一个中介。生产者把数
据放入缓冲区,而消费者从缓冲区取出数据,如下图所示:
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过消息队列(缓冲区)来进
行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给消息队列,消费者不找生产者要数据,而是直接从消息队列里取,消息队列
就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个消息队列就是用来给生产者和消费者解耦的。------------->这里又有一个问题,什
么叫做解耦?
解耦解耦
假设生产者和消费者分别是两个类。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。将来如果
消费者的代码发生变化,可能会影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。生产者直接调用
消费者的某个方法,还有另一个弊端。由于函数调用是同步的(或者叫阻塞的),在消费者的方法没有返回之前,生产者只好一直等在那边。万
一消费者处理数据很慢,生产者就会白白糟蹋大好时光。缓冲区还有另一个好处。如果制造数据的速度时快时慢,缓冲区的好处就体现出来了。
当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。等生产者的制造速度慢下来,消费者再慢慢处理掉。
因为太抽象,看过网上的说明之后,通过我的理解,我举了个例子:吃包子。
假如你非常喜欢吃包子(吃起来根本停不下来),今天,你妈妈(生产者)在蒸包子,厨房有张桌子(缓冲区),你妈妈将蒸熟的包子盛在盘子
(消息)里,然后放到桌子上,你正在看巴西奥运会,看到蒸熟的包子放在厨房桌子上的盘子里,你就把盘子取走,一边吃包子一边看奥运。在
这个过程中,你和你妈妈使用同一个桌子放置盘子和取走盘子,这里桌子就是一个共享对象。生产者添加食物,消费者取走食物。桌子的好处
是,你妈妈不用直接把盘子给你,只是负责把包子装在盘子里放到桌子上,如果桌子满了,就不再放了,等待。而且生产者还有其他事情要做,
消费者吃包子比较慢,生产者不能一直等消费者吃完包子把盘子放回去再去生产,因为吃包子的人有很多,如果这期间你好朋友来了,和你一起
吃包子,生产者不用关注是哪个消费者去桌子上拿盘子,而消费者只去关注桌子上有没有放盘子,如果有,就端过来吃盘子中的包子,没有的话
就等待。对应关系如下图:
下载后可阅读完整内容,剩余6页未读,立即下载
相关推荐




weixin_38704156
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 山东大学单片机实验教程之LCD 1602显示实验详解
- Dockerized Debian/Ubuntu deb包构建器:一站式解决方案
- 数字五笔:电脑上的手机笔划输入法
- 轻松实现自定义标签输入,Bootstrap-tagsinput组件教程
- Android页面跳转与数据传递的入门示例
- 又拍图片下载器:批量下载相册图片的利器
- 探索《Learning Python》第五版英文原版精髓
- Spring Cloud应用演示:掌握云计算开发
- 如何撰写奖学金申请书的完整指南
- 全面学成管理系统源码:涵盖多技术领域
- LiipContainerWrapperBundle废弃指南:细粒度控制DI注入
- CHM电子书反编译工具:一键还原内容
- 理解PopupWindows回调接口的实现案例
- Osprey网络可视化系统:开源软件平台介绍
- React组件:在谷歌地图上渲染自定义UI
- LiipUrlAutoConverterBundle不再维护:自动转换URL和邮件链接
