优化分布式数据库存储设计:HDFS与数据库对比与改进策略
134 浏览量
更新于2024-08-29
1
收藏 772KB PDF 举报
分布式数据库的存储设计改进是一个关键领域,它涉及到如何优化大规模数据在分布式环境中的存储和管理。这个问题起源于对Hadoop HDFS(Hadoop Distributed File System)的思考,HDFS在启动时需要Datanode扫描所有数据块并上报给Namenode,这个过程可能导致长时间的延迟,特别是在数据量庞大时。相比之下,如果分布式数据库的设计借鉴了HDFS的这种策略,即Master节点直接存储每个记录的节点信息,将会造成性能瓶颈和元数据管理的复杂性。
在HDFS中,数据的存储是基于机器负载的,这有助于数据均匀分布和动态调整,但这种策略在分布式数据库中应用有限。理想的改进应该是实现更智能的数据分布算法,比如在添加新节点时,能够快速地将数据均匀分布在新节点上,而不仅仅依赖于数据的自然收敛。这就需要一种自动或半自动的重平衡机制,类似于Hadoop的rebalance操作,但需要在分布式数据库中集成,以提高效率。
与HDFS相比,分布式数据库通常采用不同的架构,例如,将表的分区分散在Dbnode上,而不是记录级的信息存储在Master节点。这种方式虽然减少了元数据的规模,但也可能导致读写性能受随机访问的影响。理想的情况是,设计出一种机制,能在数据写入时就自动分配到合适的节点,或者在需要时进行动态迁移,从而兼顾数据的随机访问性能和元数据管理的效率。
在设计改进时,需要考虑以下几个方面:
1. **数据分布策略**:开发一个智能的分布算法,可以根据节点能力、负载和数据访问模式动态调整数据分布,以达到均衡负载和快速响应查询的目的。
2. **数据迁移**:引入数据迁移或重分布功能,当添加新节点或节点状态变化时,能快速而高效地调整数据分布,减少对服务的影响。
3. **元数据管理**:简化元数据结构,可能需要一种轻量级的机制,只存储必要的信息,以便在读写操作中快速查找数据位置。
4. **性能优化**:通过优化数据访问路径,如使用缓存或预加载策略,提高数据的读写速度。
5. **可扩展性和灵活性**:设计应易于扩展,支持动态增加或减少节点,同时允许调整数据分布规则,以适应不断变化的业务需求。
改进分布式数据库的存储设计是一个持续优化的过程,需要在保持数据的高效分布、减少元数据负担和提升整体性能之间找到平衡。通过借鉴和改进Hadoop的某些理念,但同时考虑数据库的特性和应用场景,分布式数据库有望实现更高效的存储和管理。
分布式数据库的存储设计改进分布式数据库的存储设计改进
背景
在一次游泳的时候,想起一个问题,为什么 hdfs 的 namenode 没有存储块的对应节点信息,导致启动 hdfs 的时
候,datanode 需要扫描所有的数据块,再将该 datanode 上的块信息发送给 namenode,namenode 才能构建完整的元数据
信息。根据文件和数据块的多少,启动 hdfs 的时候需要几分钟到几个小时。
对比下分布式数据库,如果把记录对应的节点信息发送给 Master,那就不可想象了。所以在分布式数据库中 hdfs 的存储策略
不可取。同时最近一直被目前的分布式数据库的存储上有几个问题困扰着:
在节点数固定的时候,Hdfs 的数据是根据机器负载来决定存储在哪个节点上的,这样做的好处是数据平均分布,可以根
据机器的存储大小加权平均,并且依据机器的负载情况动态调整;目前分布式分布式数据库中做的很有限,该如何改进
呢
添加新节点的时候, Hdfs 配置好新节点指向的 namenode,然后启动新节点即可,存储过一段时间会收敛到平均,如
果想加入后马上使得数据平均分布,可以执行 rebalance 操作;而分布式数据库添加节点的时候,配置好新节点指向的
Master,然后启动新节点之后,通常还需要根据分布的规则进行数据重新分布,甚至规则也可能需要进行拆分合并扩展
等修改,分布式数据库能做到什么程度,如何做 当然如果能做到数据重新分布,rebalance 的操作也就可以加入到分布
式数据库中,两者是共通的,都是做数据的移动,数据重新分布关注过程,rebalance 关注结果。
Hadoop 中的 hdfs 和分布式数据库的对比
在进一步的讨论如何改进分布式数据库的存储之前,先看看分布式数据库和 hadoop 中 hdfs 的对比。
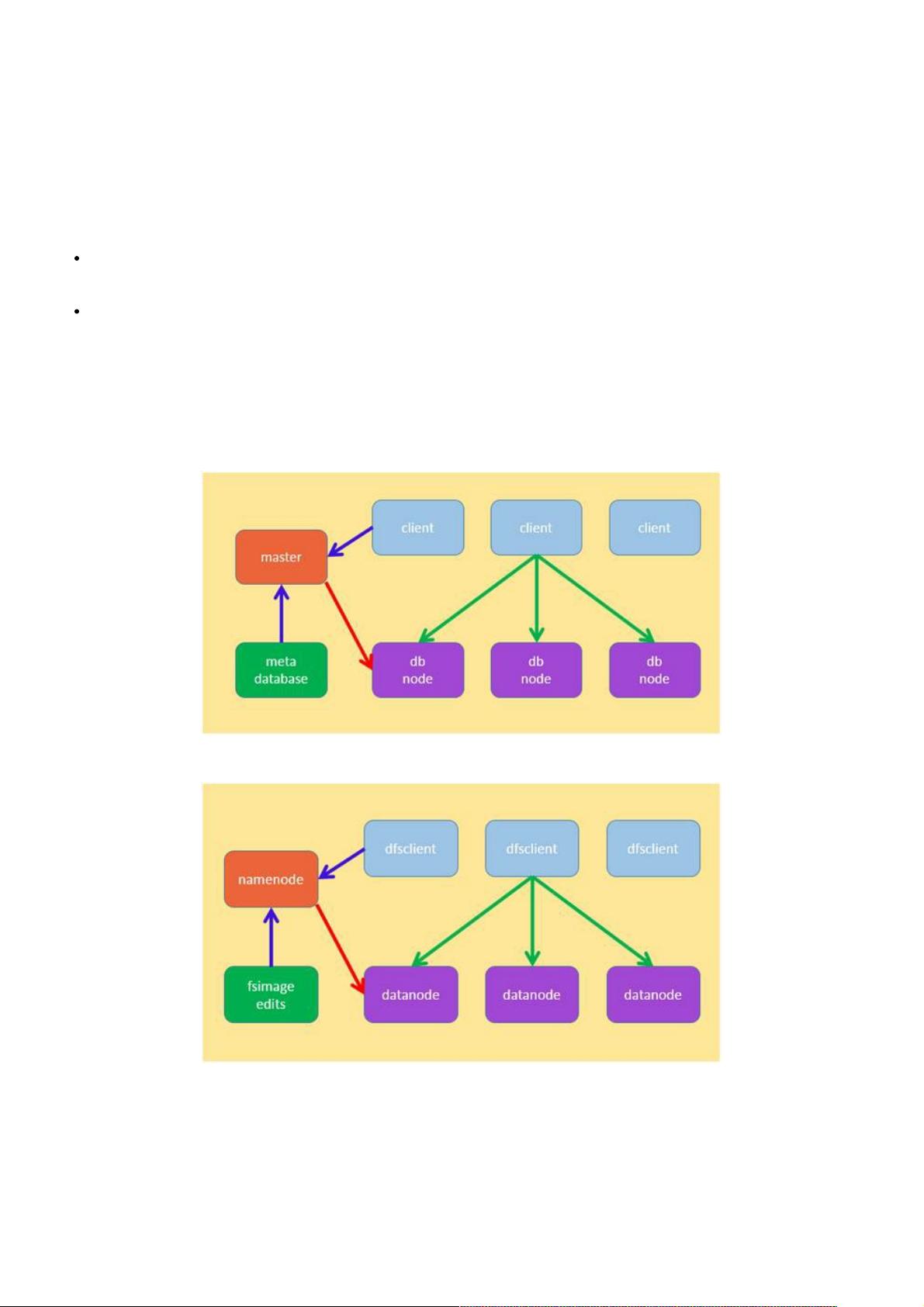
Figure 1: 分布式数据库的架构
Figure 2:hadoop 中 hdfs 的架构
前面提到分布式数据库中把记录对应的节点信息上报给 master 是不可行的方案,这里其实是一种夸大的对比,两者中的概念
按照如下的类比更加合适:
下载后可阅读完整内容,剩余9页未读,立即下载
2021-08-09 上传
2021-08-08 上传
2021-08-08 上传
2022-05-27 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-06-22 上传

weixin_38725015
- 粉丝: 8
- 资源: 926
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
