Java利用HtmlParser构建基础网络爬虫实战
"本篇文章主要介绍了如何使用Java结合HtmlParser库实现一个简单的网络爬虫。作者通过示例演示了如何抓取12306网站中的货物运价率数据,并展示了如何处理表格结构以提取所需信息。此外,文章还涉及到了危险品运输栏目的数据抓取,进一步扩展了爬虫应用的范围。
Java爬虫的核心在于解析HTML文档,HtmlParser是一个强大的Java库,它允许开发者解析HTML文档并获取其中的数据。在本文中,我们首先从导入必要的库开始,包括HttpURLConnection用于网络请求,以及HtmlParser库中的核心类如Parser、Node、NodeList等,它们是解析HTML文档的基础。
1. **网络请求与连接**:
在`JavaCrawler`类的`main`方法中,首先创建`JavaCrawler`对象并初始化。然后通过`URL`构造函数创建一个指向目标网页的URL对象,利用`HttpURLConnection`进行GET请求,获取网页内容。
2. **HTML解析**:
- `getGoodFareData`方法是抓取货物运价率数据的关键部分。首先,通过URL构建一个`Parser`对象,设置过滤器(如TagNameFilter)来指定要抓取的标签类型,如`TableTag`(表格标签),以定位到包含运价率信息的部分。然后,使用`AndFilter`、`HasAttributeFilter`和`TagNode`等组合条件,确保只抓取特定属性的表格列(例如`TableColumn`),如运价率数据所在的列。
3. **处理表格数据**:
HtmlParser库提供了`TableRow`和`TableColumn`节点,可以遍历获取到的表格行和列,进而提取出具体的数据。这里需要根据实际HTML结构设计相应的解析逻辑,可能涉及到递归或循环来遍历整个表格。
4. **扩展应用**:
文章中还提到了危险品运输栏目的数据抓取,这部分同样需要类似的方法,只是目标页面和HTML结构可能会有所不同。需要创建一个单独的方法,如`getDangerDivData`,使用相同的解析策略,针对危险品栏目的HTML结构定制过滤器,抓取并处理数据。
5. **封装和复用**:
提供的代码示例是一个基础的爬虫实现,但在实际项目中,通常会将这些功能封装成更通用的模块,以便在多个场景下重用,提高代码的可维护性和扩展性。
通过这篇教程,读者可以学习到如何使用Java和HtmlParser库开发一个能抓取网页数据并进行初步解析的网络爬虫,理解如何根据HTML结构设计和实现定制化的过滤器,以及如何处理表格数据。这对于对网络爬虫有兴趣,特别是需要处理结构化数据的开发者来说,是一份实用且具有实践价值的指南。
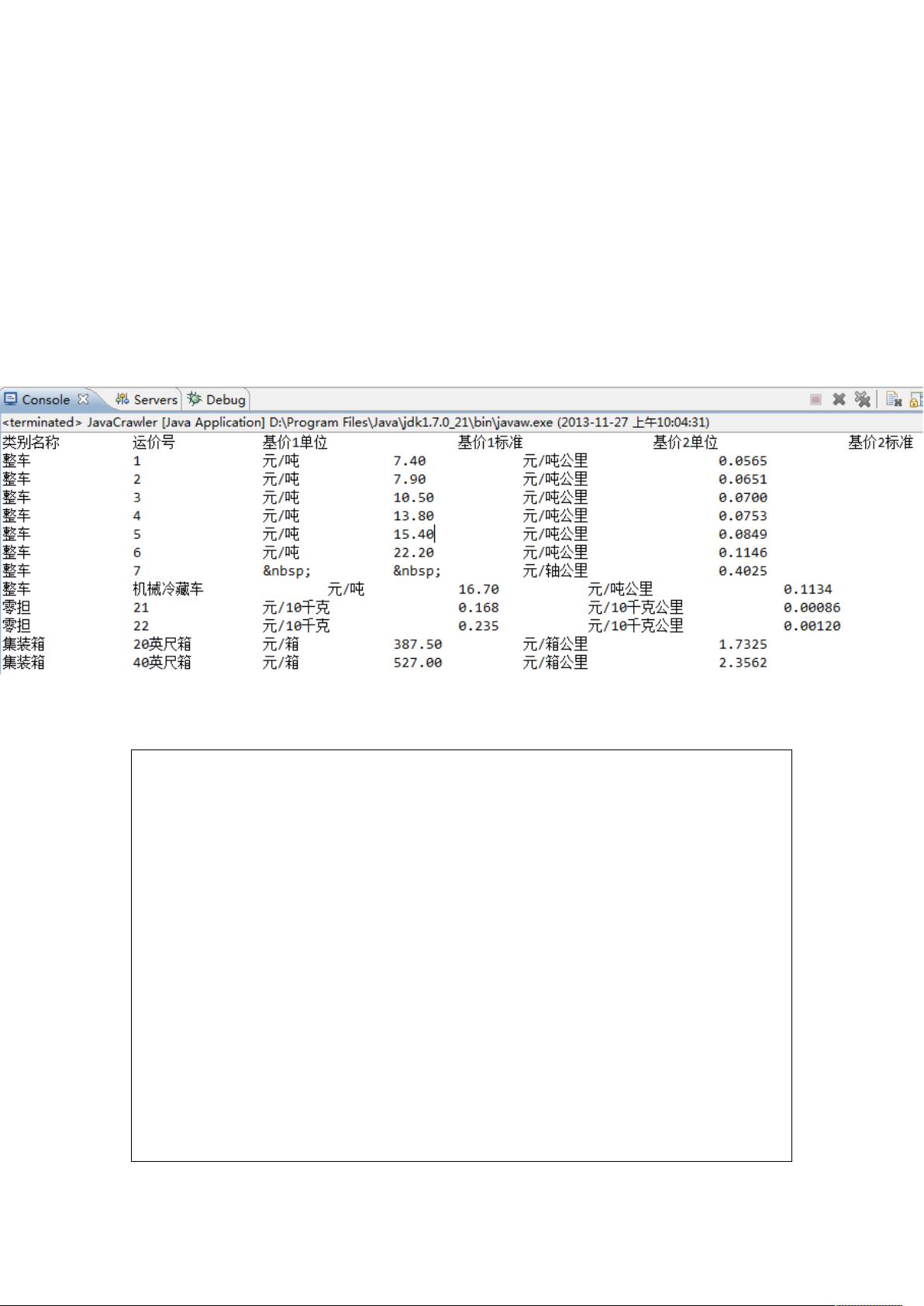
Java 使用 HtmlParser 实现简单的网络爬虫
目的
Java 使用 HtmlParser 抓取网页数据并解析。
效果图
例如:抓取 12306 网站中 货物运价率 的数据
源代码
package com.zc.test;
import java.net.HttpURLConnection;
import java.net.URL;
import org.htmlparser.Node;
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import org.htmlparser.filters.AndFilter;
import org.htmlparser.filters.HasAttributeFilter;
import org.htmlparser.filters.TagNameFilter;
import org.htmlparser.nodes.TagNode;
import org.htmlparser.tags.TableColumn;
import org.htmlparser.tags.TableRow;
import org.htmlparser.tags.TableTag;
import org.htmlparser.util.NodeList;
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
2020-01-15 上传
2014-05-05 上传
2020-09-03 上传
2016-04-20 上传
2024-03-08 上传
2010-10-28 上传
2012-04-11 上传

襄阳人漂泊
- 粉丝: 5
- 资源: 25
 我的内容管理
展开
我的内容管理
展开







最新资源
- d3-Scatterplot-Graph-fcc:FreeCodeCamp d3散点图
- CG引擎:一个随机的家伙,很开心创建c ++ OpenGl游戏引擎
- Linux shell脚本.rar
- UltrasonicDistanceMeasurementSystem:超声波测距,报警,LCD1602显示数据,温度校正超声波速度
- Excel模板基础体温记录表excel版.zip
- Advanced-Factorization-of-Machine-Systems:GSOC 2017-Apache组织-#使用并行随机梯度下降(python和scala)在Spark上实现分解机器
- operating_system_concept_os
- dosxnt文件-DOS其他资源
- Smart-Device:对于htmlacademy
- static-form-lambda:无服务器模板,创建一个FaaS AWS Lambda来处理表单提交
- Python库 | python-jose-0.6.1.tar.gz
- :scissors: React-Native 组件可在您想要的任何地方切割触摸Kong。 教程叠加的完美解决方案
- ocr
- react-pwa:使用creat js的示例渐进式Web应用程序
- VBiosFinder:从(几乎)任何BIOS更新中提取嵌入式VBIOS
- Python库 | python-hpilo-2.4.tar.gz
