Ubuntu安装Hadoop2.x实战指南:从环境配置到运行
需积分: 9 108 浏览量
更新于2024-07-18
收藏 1.5MB DOCX 举报
"Ubuntu上搭建Hadoop2.x的详细步骤及Hadoop相关知识"
在分布式计算领域,Hadoop是一个不可或缺的名字,它是一个开源框架,主要用于存储和处理大规模数据。本文档主要介绍了如何在Ubuntu操作系统上搭建Hadoop2.x环境,特别强调了伪分布式模式的配置。在深入讨论安装步骤之前,我们先来理解一下Hadoop的相关背景和原理。
Hadoop的核心组件包括HDFS(Hadoop Distributed File System)和MapReduce。HDFS是分布式文件系统,它将大型数据集分割成块,并在集群中的多台机器上存储这些数据块,以实现高可用性和容错性。MapReduce则是一种编程模型,用于处理和生成大数据集,通过将任务分解为映射(Map)和化简(Reduce)两个阶段,使得并行处理成为可能。
在分布式系统中,传统的RPC(Remote Procedure Call)技术存在一些限制,例如同步通信、紧密耦合的生命周期以及点对点通信。为了解决这些问题,引入了MOM(Message-Oriented Middleware),如Java Message Service (JMS)。JMS提供了一种标准接口,支持点对点和发布/订阅两种消息模型,确保消息的可靠传输、事务管理和过滤功能,使得不同MOM系统之间可以实现互操作。
现在,我们转向Ubuntu上安装Hadoop2.x的具体步骤:
1. 首先,你需要在VMwareWorkstation上安装Linux系统,这里推荐使用Ubuntu 12.04.3 LTS(长期支持版)。确保你已经在软件安装目录找到了VMwareWorkstation和Ubuntu的安装文件。
2. 安装完成后,启动Ubuntu并安装Hadoop2.9.0。安装过程包括下载Hadoop的tarball文件,解压到指定目录(如 `/usr/local/hadoop`),然后配置环境变量,如`HADOOP_HOME`,并将Hadoop的bin目录添加到`PATH`中。
3. 在Ubuntu中,你可以通过图形界面的终端(快捷键Ctrl+Alt+T)或使用Vi、XShell等远程连接工具进行进一步的配置。确保你的系统已经联网,因为安装过程中可能需要下载一些依赖库。
4. 配置Hadoop时,你需要修改`hdfs-site.xml`和`core-site.xml`文件,设置HDFS的名称节点和数据节点,以及Hadoop的临时目录。此外,还需要配置`mapred-site.xml`以指定MapReduce的运行模式为YARN。
5. 对于伪分布式模式,你需要在`hadoop-env.sh`中设置Java路径,并在` slaves`文件中仅列出本地主机名,表示所有Hadoop服务都在同一台机器上运行。
6. 初始化HDFS文件系统,格式化名称节点,然后启动Hadoop服务,包括DataNode、NameNode、ResourceManager和NodeManager。
7. 最后,你可以通过Hadoop自带的命令行工具,如`hadoop fs -ls`,检查HDFS是否正常工作,或者编写一个简单的MapReduce程序测试环境。
通过以上步骤,你将在Ubuntu上成功搭建起一个Hadoop2.x的伪分布式环境,可以开始进行大数据处理的学习和实践。在后续的使用中,记得定期检查日志,以便排查和解决可能出现的问题。
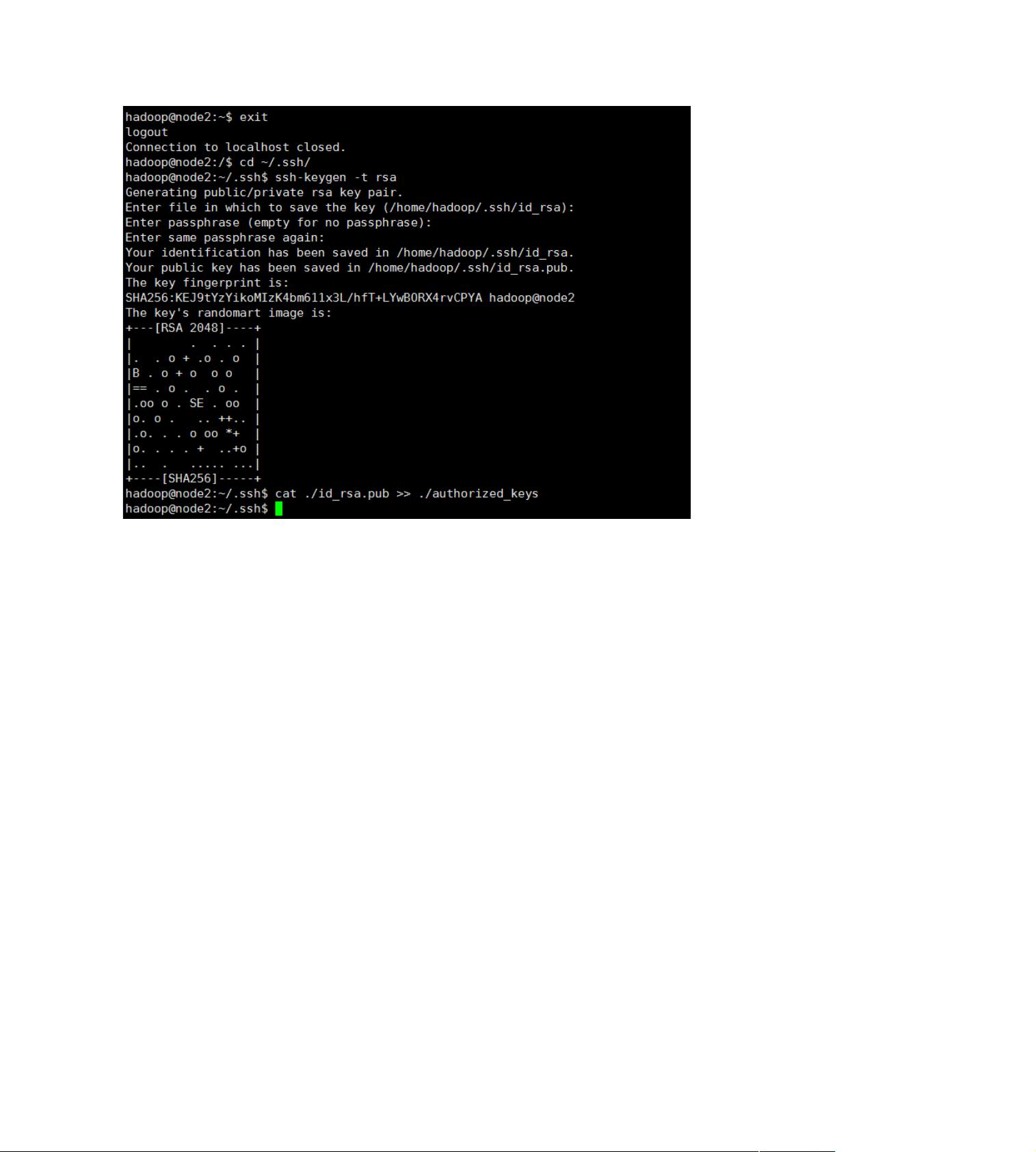
exit 退出刚才的 ssh localhost
cd ~/.ssh/ 若没有该目录,请执行一次 ssh localhost
ssh-keygen -t rsa 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys 加入授权
【注:~的含义
在 Linux 中,~代表的是用户的主文件夹,即”/home/用户名”这个目录,如你的用户名为 hadoop,则~就代表”/home/hadoop”
。此外,命令中的#后面的文字是注释】
此时再用 ssh localhost 命令,无需输入密码就可以直接登录了,如下图所示。
剩余16页未读,继续阅读
1215 浏览量
2022-11-21 上传
160 浏览量
2022-10-15 上传
122 浏览量
252 浏览量
2022-10-13 上传
271 浏览量

qq_25459521
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- personal_website:个人网站
- css按钮过渡效果
- 解决vb6加载winsock提示“该部件的许可证信息没有找到。在设计环境中,没有合适的许可证使用该功能”的方法
- haystack_bio:草垛
- BaJie-开源
- go-gemini:Go中用于Gemini协议的客户端和服务器库
- A14-Aczel-problems-practice-1-76-1-77-
- 行业文档-设计装置-一种拉出水泥预制梁的侧边钢筋的机构.zip
- assessmentProject
- C ++ Primer(第五版)第六章练习答案.zip
- website:KubeEdge网站和文档仓库
- MATLAB project.rar_jcf_matlab project_towero6q_牛顿插值法_牛顿法求零点
- ML_Pattern:机器学习和模式识别的一些公认算法[决策树,Adaboost,感知器,聚类,神经网络等]是使用python从头开始实现的。 还包括数据集以测试算法
- matlab布朗运动代码-clustering_locally_asymtotically_self_similar_processes:项目
- 行业文档-设计装置-一种折叠钢结构雨篷.zip
- mswinsck.zip
